-

在Python中,使用NumPy库可以实现向量化操作,提升代码效率。1)NumPy的ndarray对象支持高效的多维数组操作。2)NumPy允许进行逐元素运算,如加法。3)NumPy支持复杂运算,如统计和线性代数。4)注意数据类型一致性、内存管理和广播机制。
-

在Python中实现数据清洗可以通过以下步骤:1)使用Pandas的fillna方法处理缺失值,2)用duplicated和drop_duplicates方法处理重复数据,3)利用pd.to_datetime方法格式化日期数据,4)通过IQR方法检测并处理异常值。Python的Pandas和NumPy库使得这些操作简单高效,但需注意避免引入偏差。
-

在Python中,pandas库是处理时间序列数据的强大工具。1)创建和操作时间序列数据使用Timestamp和DatetimeIndex。2)进行重采样和滚动窗口计算,如月度重采样和7天移动平均。3)处理缺失值和异常值,使用fillna方法。4)处理不同时区的数据,使用tz_localize和tz_convert方法。5)处理不规则时间序列,使用asfreq方法。6)性能优化通过预计算和矢量化操作提升效率。
-

在Python中进行静态代码分析可以使用Pylint、Mypy和Bandit三种工具。1.Pylint用于检查代码风格和潜在错误。2.Mypy用于类型检查。3.Bandit用于检测安全漏洞。这些工具结合使用能显著提高代码质量和安全性。
-

本文将为大家详细介绍如何使用Python和wxPython来实现批量文件扩展名替换。小编认为这非常实用,因此分享给大家,希望大家在阅读后能有所收获。PythonwxPython实现批量文件扩展名替换引言在处理大量文件时,常常需要将文件扩展名从一种类型转换为另一种类型。Python提供强大的字符串处理功能,而wxPython则提供了直观的图形用户界面。本文将指导你如何使用Python和wxPython编写一个程序,以批量替换文件扩展名。步骤1:导入必要的模块首先,你需要导入必要的Python和wxPy
-

学习Python需要具备以下基础知识:1.编程基础:理解变量、数据类型、控制结构、函数和模块。2.算法与数据结构:掌握列表、字典、集合等数据结构及排序、搜索等算法。3.面向对象编程:熟悉类、对象、继承、封装和多态。4.Python特有的特性:了解列表推导式、生成器、装饰器等。5.开发工具和环境:熟练使用PyCharm、VSCode等IDE,及虚拟环境和包管理工具。
-

使用Python剪辑音频,主要步骤如下:1.使用pydub库加载音频文件,将其视为可切割的AudioSegment对象;2.利用audio[start_time:end_time]切片语法指定剪辑起始和结束时间(毫秒);3.使用export()方法导出剪辑后的音频文件。需注意处理音频格式兼容性、文件路径及内存溢出等问题,并可结合librosa进行高级操作或利用多线程优化性能。熟练掌握Python及相关库,才能高效完成音频剪辑。
-

深入探讨程序运行的基石:上下文、运行环境与执行环境程序的顺利运行依赖于诸多因素,其中“上下文”、“...
-

如何在同一台机器上运行多个UWSGI服务?问题描述:在一台服务器上部署了两个项目,计划使用UWSGI...
-
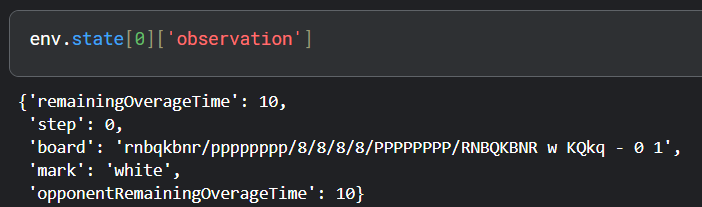
我最近尝试用DQN构建一个国际象棋AI代理。任何了解DQN和国际象棋的人都会告诉你这是个不太现实的想法。确实如此,但作为一名初学者,我依然乐于尝试。本文将分享我的经验和心得。环境理解在实现代理之前,我需要熟悉环境并创建一个自定义包装器,以便在训练过程中与代理交互。我使用了kaggle_environments库中的国际象棋环境。fromkaggle_environmentsimportmakeenv=make("chess",debug=True)我还使用了chessnut,一个轻量级的Python库,用
-

Selenium的add_cookies()添加Cookie无法实现网页登录的原因当使用Selenium的driver.add_cookies()方法添加Cookie...
-
猜数字游戏概述:这个python程序是一个有趣且引人入胜的猜数字游戏,用户有五次机会猜测1到100之间随机生成的数字。以下是游戏如何工作以及代码如何运行的详细说明:如何运作欢迎讯息游戏开始时,用户会收到一条有趣的消息:“你好!我是isaeusguiang,这是一个猜数字游戏。你有5次机会猜出数字,否则...你会死:)。”随机数生成该程序使用random.randint(1,100)生成1到100之间的随机整数。这个数字将是用户必须猜测的目标。用户输入和验证用户有五次尝试猜测数字的机会。如果用户输入的不是有
-

Python图表绘制:设定x轴刻度在绘制图表时,如何将x轴上的刻度设定为指定的日期,是一个常见的需求。以下将�...
-

我以前从未从终端运行过python,所以我不知道涉及什么,我总是从PyCharm运行我的项目。我的项目在PyCharm上运行良好。我在Linux上运行。我的文件结构如下:回溯测试-这是我的项目BackTestPkg-我的包之一initpy参数.py...MAX1-我的主要开发MAX1_Controller.pyMAX1_Main.py...TradingPkg-我的另一个包init.pyPlatformLib.py...MAX1_Controller.py调用MAX1_Main.py,并且都调用BackT
-

Python作为一门高级语言,被广泛应用于各种场景中。其中,服务器编程是Python的重要应用之一,它涉及到诸多技术和模型。本文将重点讲解Python服务器编程中的半同步半异步Reactor模型。一、什么是半同步半异步Reactor模型?在讲解半同步半异步Reactor模型之前,我们先来认识一下Reactor模型。Reactor是一种事件驱动模型,其基本思想