-

FastAPI中高效处理大于小于的CRUD操作Django的django-filter...
-

深入探讨uvicorn、gunicorn和uwsgi的多进程并发模型本文将深入探讨uvicorn是如何实现多进程同时监听同一个socket的,...
-

使用requests库爬取网页数据时遇到问题?很多开发者在使用Python的requests库爬取网页数据时,常常会遇到获取到�...
-

使用Python进行地址数据清洗,核心方法是:1.利用addressparser库解析地址,提取省市区街道门牌号等关键信息;2.将提取的信息拼接成标准化地址格式;3.使用try...except语句处理无法完整解析的地址;4.针对大量数据,考虑多线程或多进程处理及高效数据结构,最终实现地址数据标准化,提升数据质量。
-

Python与SSL:常见问题及解决方案安全套接字层(SSL)是互联网安全通信的关键组成部分。Python作为一门广泛应用的编程语言,常常需要通过SSL与API、数据库和Web服务进行交互。然而,SSL相关的各种问题可能会给开发人员带来挑战,影响程序运行并危及安全性。本文总结了Python中常见的15个SSL问题,并提供相应的解决方案,帮助开发者提升Python应用的安全性与可靠性。1.SSL证书验证失败Python的SSL库无法验证服务器提供的SSL
-
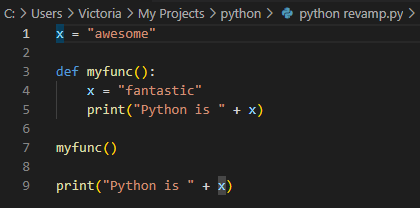
探索Python编程的奇妙旅程:深入理解函数与全局变量一直以来,构建优秀程序的挑战激发着我的热情。虽然我秉持着谦逊的学习态度,但此刻,我渴望将所学知识用于更广阔的应用,造福大众。近日,我深入复习了Python的基础概念,并从中获得了重要的领悟:更深层次的思考我开始追问更深层次的问题,例如:“如果我这样修改,这段代码为什么无法运行?”即使问题最终得以解决,这样的发问也帮助我理解代码背后的运行机制,这对于调试和问题解决至关重要。函数的魅力函数是执行特定任务的代码块,可以被重复调用以获得结果。以下示例展示了全局
-

PyMySQL执行插入却未报错,原因何解?在使用PyMySQL进行数据库操作时,有时可能会遇到如下情况:执行插入语句�...
-

Django部署时出现自定义模板标签无法识别错误在使用uwsgi和nginx部署Django...
-
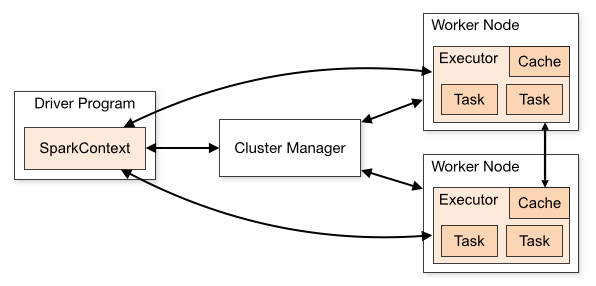
为什么spark慢?从一个引人注目的标题“spark为什么这么慢?”开始,值得注意的是,称spark“慢”可能意味着多种含义。聚合速度慢吗?数据加载?存在不同的情况。此外,“spark”是一个广泛的术语,其性能取决于编程语言和使用上下文等因素。因此,在深入讨论之前,让我们将标题改进得更加精确。由于我主要在databricks上使用spark和python,因此我将进一步缩小范围。优化后的标题将是:“spark的第一印象:‘听说它很快,但为什么感觉很慢?’初学者的视角”写作动机(随意的想法)作为广泛使用pa
-

如何在piplist中找到已安装的cudatoolkit和cudnn?使用conda安装库时,它们不会显示在piplist中。这是因为...
-

Python3.12中使用class__init__*属性报错在Python3.12...
-

大家好,我在使用OpenAIAssistantsAPI创建控制台机器人时遇到困难,希望得到您的帮助。问题是这样的:我通过Playground创建了一个助手并拥有它的ID。我现在的目标是创建一个与该助手交互的控制台机器人。助手仅使用指令,不使用任何工具。主要任务是确保机器人根据指令做出响应并维护对话历史记录。我尝试使用PromptEngineering,但问题是我必须单独保存历史记录(例如,以JSON格式)并每次将其发送到API,以便机器人理解上下文。对于AssistantsAPI,似乎没有必要,因为使用了
-

破解点触类验证码:第三方平台还是自研方案?点触类验证码在安全性和防止自动化填写方面有着广泛的应用,...
-

2024年7月12日星期五本周Python是关于过去一周Python世界发生的事情的简明阅读列表。Python文章Python有太多的包管理器使代理对象成为可能的Python内部机制使用Python数据帧在笔记本电脑上查询1TB将PowerShell变成Python引擎项目pyxel–Python的复古游戏引擎–作者:@kitaopackse–Python打包场景amphi-etl–适用于结构化和非结构化数据的低代码ETLcrawlee-python–用于Python的网络抓取和浏览器自动化库,用于构建可
-

要打开刚下载的Python,请按以下步骤操作:将安装程序放在易于访问的位置。双击安装程序图标并按照屏幕上的说明进行操作。安装完成后,在命令提示符或终端窗口中输入"python"以启动Python交互式shell。