-

高效利用OpenAI进行模型微调:纪律与协调为了高效地完成模型微调任务,我们需要遵循严格的流程,并充分利用OpenAI提供的工具。本文将详细介绍如何创建和管理OpenAI的微调作业,确保模型能够从精心准备的数据集中学习。使用OpenAI进行微调创建微调作业使用client.fine_tuning.job.create()方法,该方法需要您提供配置信息和数据集。以下是对关键参数的详细解释:参数详解1.模型(Model)说明:您希望微调的预训练GPT模型。示例:"gpt-3.5-turbo","davinci
-

Python字符串详解:字符串是Python中用单引号或双引号括起来的字符序列。例如:“你好,世界!”‘Python’“这是个问题吗?”字符串类型:单行字符串:使用单引号('这是一个字符串')或双引号("这也是一个字符串")创建。print('helloworld!')print("what'sup?")#输出:#helloworld!#what'sup?多行字符串:使用三个单引号(python'''''')或三个双引号(python"""""")创建。print("""我们养了一只宠物。它是一只狗。""
-

通过inspect获取装饰器参数的难题在Python中,inspect模块提供了获取函数元数据的方法。然而,获取装饰器传入的�...
-

机器视觉入门:推荐框架与学习路线作为机器视觉学习的新手,在众多框架中挑选一个合适的工具至关重要。根...
-

列表里面套列表(嵌套列表),如何把各个列表的元素循环出来?遇到嵌套列表时,可以使用嵌套循环来遍历其...
-
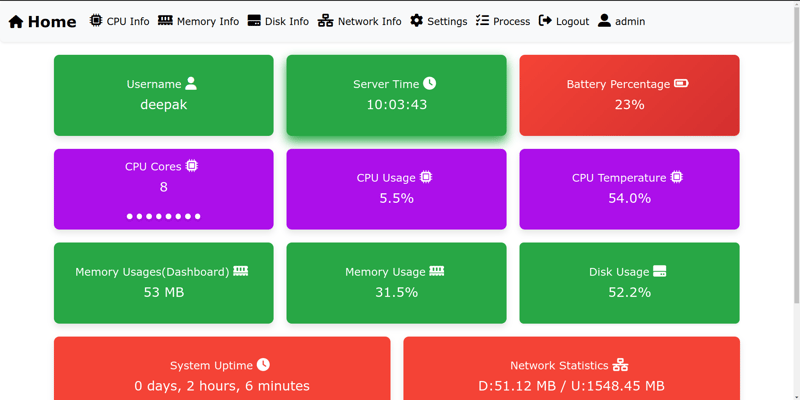
系统卫士?SystemGuard是您轻量级、用户友好且易于设置的服务器监控的首选工具。跟踪从CPU使用率和内存到网络速度和正在运行的进程的所有信息,全部集中在一处。✨主要特点全面的服务器监控:密切关注重要的服务器统计信息,例如CPU、内存、磁盘和网络使用情况。网速测试:使用内置速度测试轻松检查服务器的网络速度。限速速度测试:通过限制运行速度测试的频率来防止滥用。流程管理:只需单击一下即可识别并终止消耗CPU最多的进程。实时监控:获取服务器运行状况指标的最新更新。响应式设计:享受跨移动设备、平板电脑和桌面设
-

介绍我一直在云端构建llm应用程序。我还看到很多开发人员制作llm应用程序,这对于mvp或原型来说非常好,但需要一些工作才能使其做好生产准备。应用所列出的一种或多种实践可以帮助您的应用程序以有效的方式进行扩展。本文不涵盖应用程序开发的整个软件工程方面,而仅涵盖llm包装应用程序。此外,代码片段是用python编写的,相同的逻辑也可以应用于其他语言。1.利用中间件实现灵活性使用litellm或langchain等中间件来避免供应商锁定,并随着模型的发展在模型之间轻松切换。python:fromlitellm
-

大家好,今天学习了Python的print语句。知道Python有这么多的功能真是令人着迷。我将分享我今天学到的一些东西sep,sep参数与print()函数一起使用,用于指定打印多个参数时的分隔符。转义序列如n(新行),t(添加空格),b(删除前一个字符)。串联添加两个不同的字符串。连接str和int通过类型转换将整数转换为字符串来组合字符串和整数。原始字符串Python中的原始字符串是通过在字符串文字前添加“r”或“R”前缀来定义的。原始字符串通常在使用正则表达式或处理文件系统中的路径时使用,以避免意
-

大家好!本周我又带着新的python课程回来了。本周我们将学习循环。在任何编程语言中,循环都是非常重要的主题。通过理解循环,您将能够在几秒钟内完成乏味且耗时的工作。由此可见循环是多么的重要。那么让我们深入研究一下吧。为什么我们需要循环?让我们尝试理解有问题的循环。假设你是班级的课代表,教授让你负责从数据库中找出班级的平均成绩。现在你们班有30名学生。所以数据库中有30个等级。现在,我们假设成绩作为列表存储在单个变量中。(稍后我们会详细讨论“列表”)现在手动找出平均成绩肯定需要很长时间。所以在这种情况下,循
-

使用datetime模块中的timedelta()方法将天数添加到日期中,例如result_1=date_1+timedelta(days=3)。timedelta方法可以传递天数参数并将指定的天数添加到日期。fromdatetimeimportdatetime,date,timedelta#✅将天数添加到日期my_str='09-24-2023'#????️(mm-dd-yyyy)date_1=datetime.strptime(my_str,'%m-%d-%Y')pri
-

通过conda快速创建虚拟环境,轻松管理项目依赖在进行Python开发时,我们经常会遇到需要使用不同的Python版本或不同的第三方库的情况。为了避免各种依赖和版本的冲突,我们可以使用虚拟环境来隔离不同的项目环境。conda是一个非常强大的包管理工具,它可以帮助我们快速创建并管理虚拟环境,解决项目依赖问题。首先,我们需要安装好Anaconda,它包含了con
-

Python字符串切片:简单易用的文本处理技巧引言在Python中,字符串是一种非常常见和重要的数据类型。在文本处理中,我们经常需要对字符串进行一些操作,如提取特定的子串、拼接多个字符串、替换字符串中的部分内容等。而Python中的字符串切片操作提供了一种非常简单易用的方法来实现这些功能。本文将介绍Python字符串切片的基本使用方法,并提供一些具体的代码示
-

正文大家好,我是Python人工智能技术如果说写代码最害怕什么,那无疑是Bug。而对于新手来说,刚刚接触编程,在享受写代码的成就感时,往往也会被各式各样的Bug弄得晕头转向。今天,我们就做了一期Python常见报错的分享,拯救你的代码!一.缩进错误(IndentationError)在Python中,所有代码都是通过正确的空格排列的。所以,无论是多出来空格,还是缺少空格,整个代码都不会运行,并且仅返回一个错误函数。Python代码遵循PEP8空白规范,每一级缩进使用4个空格。错误示例a=1b=2
-

高效删除Conda环境:提升工作效率的必备技能,需要具体代码示例随着数据科学领域的快速发展,Conda成为了许多数据科学家和开发者们首选的包管理工具。Conda不仅可以有效地创建和管理Python环境,还能够轻松地安装各种数据科学包和库。然而,在实际使用中需要频繁地创建和删除环境,因此对于高效删除Conda环境的技巧是提高工作效率的重要一环。本文将介绍一些高
-

Python中常见的数据转换问题及解决方案引言:在Python编程中,数据的转换是一项非常常见的任务。无论是从字符串到整数、从列表到元组,还是从字典到JSON,数据转换是我们在处理数据时经常遇到的问题之一。本文将介绍一些常见的数据转换问题,并提供一些解决方案和具体代码示例。将字符串转换为整数或浮点数当我们需要将字符串类型的数据转换为整数或浮点数时,可以使用内