-

学习Python需要具备以下基础知识:1.编程基础:理解变量、数据类型、控制结构、函数和模块。2.算法与数据结构:掌握列表、字典、集合等数据结构及排序、搜索等算法。3.面向对象编程:熟悉类、对象、继承、封装和多态。4.Python特有的特性:了解列表推导式、生成器、装饰器等。5.开发工具和环境:熟练使用PyCharm、VSCode等IDE,及虚拟环境和包管理工具。
-

PyCharm支持通过SSH连接到Linux服务器进行远程Python开发和调试。1)配置SSH连接,2)选择远程Python解释器,3)创建远程Python项目,这样可以在本地编写代码并在服务器上运行和调试,提升开发效率。
-

在Ubuntu22.04上源码编译安装Python3.12的步骤包括:1.安装依赖项:使用sudoaptupdate和sudoaptinstall命令安装必要的库;2.下载源码:使用wget和tar命令下载并解压Python3.12源码;3.配置、编译和安装:运行./configure、make-j$(nproc)和sudomakealtinstall命令完成安装。
-

这篇文章提供了100道Python编程练习题,旨在帮助读者全面提升Python编程能力。1.基础知识回顾:Python支持多种数据类型,控制流包括条件语句和循环,函数支持高级用法,模块和包便于代码组织。2.核心概念解析:通过基本语法练习,如变量赋值、条件语句、循环和函数定义,巩固基础。3.算法与数据结构:介绍了排序算法和数据结构如栈的实现。4.使用示例:从基本用法如计算和判断,到高级用法如二分查找和图结构的实现。5.常见错误与调试:介绍了语法、逻辑、类型和索引错误的调试技巧。6.性能优化与最佳实践:建议使
-

Django中的分词搜索实现方法在Django项目中,实现分词搜索功能是一项非常实用的技能,特别是当你希望用户在搜...
-

在使用NumPy保存和加载数据时,可能会遇到numpy.load函数返回None...
-

Java技能提升:从入门到有趣小程序的实践之路很多Java学习者都会面临这样的困境:掌握了Java、Spring...
-

Python列表操作:append方法与"+"...
-
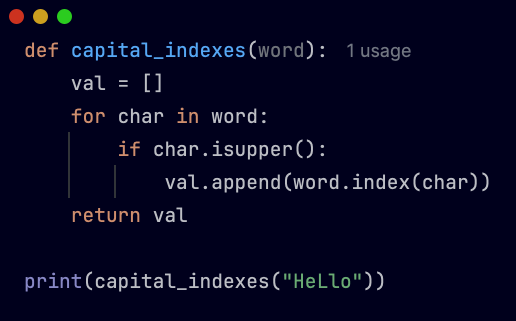
>写一个名为capital_indexes的函数。该函数采用单个参数,即string。您的函数应返回具有大写字母的字符串中所有索引的列表。例如,呼叫capital_indexes(“hello”)返回列表[0,2,4]。这是这里的>挑战>。正如您在编程中所知道的那样,有很多方法可以使用不同的方法来实现结果。主要要点是您的方法应该是好的,而不是一些垃圾,然后在这里和那里扔出不同的方法和功能。因此,我用两种不同的方法解决了这个问题。一个是我认为初学者会尝试做的,另一个是经验丰富的Pyth
-

片头字幕一切顺利的那一刻,就认为这个项目很有趣。我构建了一个客户端友好的cli项目来掌握类、方法和属性的工作原理。我的目录结构非常简单:└──lib├──模特│├──__init__.py│└──actor.py|└──movie.py├──cli.py├──debug.py└──helpers.py├──pipfile├──pipfile.lock├──readme.md正如您从结构中看到的,我建立了一个一对多关联,其中一个演员有很多电影。从这个协会我的菜单开始发挥作用。当前演员名单添加演员删除演员退出
-

这是第二天,编码为下午5点到630,中间休息10分钟目标是开始并获得第5章的几页内容,自动化处理字典的无聊内容。构建了一些项目,我最喜欢的项目是tiktaktoe基本命令行用户友好程序。我确实有一些想法可以建立在这个项目的基础上,但那是稍后的事情了。能够从用户a和用户b获得该程序真是太酷了。但我确实有一个小问题,那就是坐着,我只能坐几次,然后我开始抽筋,需要站起来。我确实从桌子上拔下了笔记本电脑的电源,然后走到床边,坐在那儿处理这件事。在此之前,我也注册了该网站https://roadmap.sh/pyt
-

向已有对象实例添加方法在Python...
-

而不是defdo_something(a,b,c):returnres_fn(fn(a,b),fn(b),c)我愿意:defdo_something(a,b,c):inter_1=fn(a,b)inter_2=fn(b)result=res_fn(inter_1,inter_2,c)returnresult第一个版本要短得多,如果格式正确,同样具有可读性。但我更喜欢第二种方法的原因是因为所有中间步骤都保存到局部变量中。像sentry这样的异常跟踪工具,甚至是设置debug=true时弹出的django错误
-

Matplotlib:基础绘图库Matplotlib是一个灵活且功能强大的2D绘图库,它提供了一系列函数来创建各种类型的图表。importmatplotlib.pyplotasplt#创建一个简单的折线图plt.plot([1,2,3,4],[5,6,7,8])plt.xlabel("X-axis")plt.ylabel("Y-axis")plt.title("折线图示例")plt.show()Seaborn:统计图形Seaborn构建在Matplotlib之上,提供了一个高级接口,专门用于创建美观且信息
-

在当今科技智能化的时代,智能家居系统正成为人们日常生活的标配,从智能门锁、智能灯泡,到智能音箱、智能家电等,智能家居正在逐渐地渗入到我们的生活中。而Python作为一种近年来较为流行的编程语言,其快速开发、易于学习、功能强大的特点,使其成为了许多智能家居控制系统的首选开发语言。那么,本文将介绍如何使用Python和树莓派,开发一个简单的智能家居控制系统,并提