-
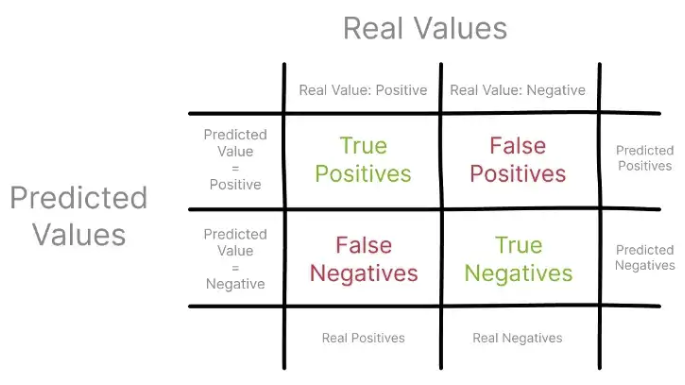
正文ROC分析和曲线下面积(AUC)是数据科学中广泛使用的工具,借鉴了信号处理,用于评估不同参数化下模型的质量,或比较两个或多个模型的性能。传统的性能指标,如准确率和召回率,在很大程度上依赖于正样本的观察。因此,ROC和AUC使用真阳性率和假阳性率来评估质量,同时考虑到正面和负面观察结果。从分解问题到使用机器学习解决问题的过程有多个步骤。它涉及数据收集、清理和特征工程、构建模型,最后是,评估模型性能。当您评估模型的质量时,通常会使用精度和召回率等指标,也分别称为数据挖掘领域的置信度和灵敏度。这些指标将预测
-

python作为一种功能强大的编程语言,为数据可视化提供了丰富的工具箱。这些工具使数据科学家和分析师能够将复杂的数据转换为直观易懂的可视化效果,从而揭示模式、趋势和见解。1.Matplotlib:基础且灵活Matplotlib是最流行的Python可视化库之一。其提供了一系列绘图功能,包括线形图、条形图、散点图和直方图。它允许高度定制,使您可以创建专业级的可视化效果。importmatplotlib.pyplotaspltplt.plot(x,y)plt.xlabel("x-axis")plt.ylabe
-

python多线程和多进程在未来发展中具有广阔的前景。随着计算机硬件的不断发展,多核处理器已成为主流。多线程和多进程可以充分利用多核处理器的优势,提高程序的运行效率。1.多线程的发展趋势Python多线程的发展趋势主要体现在以下几个方面:线程池的广泛应用:线程池是一种管理线程的机制,可以提高线程的创建和销毁效率。线程池在很多场景中都有应用,例如WEB服务器、数据库服务器等。GIL的改进:GIL是Python中的一个全局锁,它保证同一时刻只有一个线程可以执行Python字节码。GIL的存在限制了Python
-

PyCharm技巧:轻松掌握多行注释的操作技巧作为一款功能强大的Python集成开发环境,PyCharm提供了许多便捷的操作技巧,帮助开发者提高工作效率。其中,对于多行注释的操作也是开发过程中频繁使用的功能之一。在本篇文章中,我们将介绍如何在PyCharm中轻松掌握多行注释的操作技巧,并提供具体的代码示例。一、在PyCharm中插入多行注释在PyCharm中
-

Ubuntu系统安装pip的步骤和注意事项【引言】在使用Python开发时,我们通常需要使用到很多第三方库。而pip作为Python的包管理工具,可以方便地安装和管理这些第三方库。本文将介绍在Ubuntu系统上安装pip的步骤和需要注意的事项,并提供具体的代码示例。【步骤】以下是在Ubuntu系统上安装pip的步骤:步骤1:更新系统软件包列表打开终端,运行以
-

为什么要使用pip换源?它有什么好处?在使用Python进行开发的过程中,我们经常会用到pip这个包管理工具来安装、升级和卸载各种Python包。然而,由于网络的原因,有时候我们可能会遇到pip安装包非常缓慢甚至失败的情况。为了解决这个问题,我们可以使用pip换源,将默认的源修改为国内的源。本文将介绍为什么要使用pip换源以及它的好处,并且给出具体的代码示例
-

Python函数介绍:slice函数的介绍及示例Python是一种简单易学、功能强大的高级编程语言,拥有丰富的内置函数和标准库。其中,slice函数是Python中非常实用的一个函数,用于创建一个切片对象,用来切割序列(包括字符串、列表等)。slice函数的语法如下:slice(stop)slice(start,stop[,step])其中,slice函
-

为什么外企对Python编程技能的需求更高?近年来,Python编程语言在全球范围内的应用越来越广泛。尤其是在外企,对Python编程技能的需求更是高涨。那么,为什么外企对Python编程技能的需求更高呢?本文将从以下几个方面来探讨这个问题。首先,Python是一种简单易学的编程语言。相较于其他编程语言,Python的语法更加简洁明了,更具可读性。这使得Py
-

技巧大揭秘:用Python绘制漂亮的3D图表引言:在数据可视化领域,制作漂亮的3D图表能够更直观地展示数据的特征和趋势。Python作为一种功能强大的编程语言,拥有众多的库和工具,能够帮助我们实现这一目标。本文将分享一些Python绘制漂亮的3D图表的技巧和具体代码示例,帮助读者更好地理解和应用。一、准备工作:在开始之前,我们需要安装几个必要的Python库
-

文本预处理需兼顾语义与效率,中文应使用领域增强分词、保留否定词、标准化数字英文;问答匹配推荐双塔结构+对比学习,辅以hardnegative构造;评估重Recall@1与MRR,须模拟真实检索流程。
-

多进程异常处理需通过IPC机制传递异常信息,因进程隔离导致异常无法自动冒泡。常用方法包括:子进程中捕获异常并通过Queue或Pipe发送给父进程;使用multiprocessing.Pool的AsyncResult.get()在父进程重新抛出异常;辅以日志记录便于排查。关键在于主动传递异常详情,避免沉默失败,并注意pickle序列化、超时设置和资源清理等问题。
-

Python3.9引入类型提示中的|运算符作为Union的语法糖,替代Union[T1,T2]写法,无需导入typing,支持str|int|None等简洁标注,提升可读性、可维护性与协作效率,但仅限类型注解上下文使用。
-

Python单线程高并发I/O靠事件循环+非阻塞I/O+协程协作调度,非多线程;await挂起协程交还控制权,I/O就绪后恢复;CPU密集型任务需用run_in_executor避免阻塞循环。
-

Python3.7+中dict.fromkeys()能保序去重,是因为字典本身保持插入顺序,且按iterable遍历顺序插入key(value为None),重复key自动跳过;需显式转list使用,仅适用于可哈希元素。
-

LightGBM比XGBoost快的核心在于GOSS和EFB:GOSS按梯度绝对值排序,保留top_rate(默认0.2)高梯度样本并随机采样other_rate(默认0.1)小梯度样本加权计算,每轮仅处理约30%样本;EFB将互斥稀疏特征通过位移+加法编码捆绑压缩,降低特征维度,两者协同显著减少冗余计算。