-

如何用PythonforNLP提取并分析多个PDF文件中的文本?摘要:随着大数据时代的来临,自然语言处理(NLP)成为了解决海量文本数据的重要手段之一。而PDF作为一种常见的文档格式,包含了丰富的文字信息,因此如何提取和分析PDF文件中的文本成为了NLP领域的一项关键任务。本文将介绍如何使用Python编程语言和相关的NLP库来提取和分析多个PDF文件中
-

开发基于ChatGPT的智能客服系统:Python为您办事,需要具体代码示例随着人工智能技术的发展,智能客服系统在各个行业得到了广泛的应用。基于ChatGPT的智能客服系统可以通过自然语言处理和机器学习的技术,为用户提供快速、准确的解答和帮助。本文将介绍如何使用Python开发基于ChatGPT的智能客服系统,并提供具体的代码示例。一、安装所需的Python
-

ChatGPT和Python的完美结合:打造实时聊天机器人导言:随着人工智能技术的快速发展,聊天机器人在各个领域中扮演着越来越重要的角色。聊天机器人可以帮助用户提供即时且个性化的帮助,同时也可以为企业提供高效的客户服务。本文将介绍如何使用OpenAI的ChatGPT模型和Python语言相结合,打造一个实时聊天机器人,并提供具体的代码示例。一、ChatGPT
-

从入门到精通:Python变量赋值的奥秘揭秘Python作为一门简洁而强大的编程语言,变量的赋值是其基础之一。虽然在表面上看起来很简单,但实际上Python的变量赋值有着一些奥秘的内涵。在本文中,我们将揭秘Python变量赋值的奥秘,并通过具体的代码示例来帮助读者更好地理解。首先,让我们从最基础的变量赋值开始。在Python中,通过使用等号(=)将值赋给变量
-

Python是一种简单易学的高级编程语言,被广泛用于数据分析、人工智能、Web开发等领域。在Python中,print是一个常用的函数,用于在屏幕上输出结果或调试信息。本文将详细介绍print函数的用法,并提供具体的代码示例帮助读者更好地掌握。首先,print函数可以接受多个参数,并将它们打印到屏幕上。这些参数可以是字符串、整数、浮点数等,甚至还可以是变量、
-

PyCharm是一款由JetBrains公司开发的强大的Python集成开发环境(IDE),旨在为开发者提供便捷、高效的Python编程工具。PyCharm分为社区版和专业版两个版本,两者在功能上有一定的差异。本文将详细介绍PyCharm社区版和专业版的功能区别,帮助读者更好地选择适合自己的版本。首先,需要明确的是PyCharm社区版
-

1.区块链概述区块链是一种分布式数据库,用于以安全、透明和防篡改的方式记录交易。它由一个链状结构组成,其中每个区块都包含一定数量的交易信息、前一个区块的哈希值和其他元数据。区块链的技术核心是分布式账本和共识机制,实质上是一种去中心化的数据库。2.Python中的区块链实现首先,我们创建一个新的python项目,并安装必要的库。PythonimporthashlibimportJSONfromdatetimeimportdatetime然后,我们创建一个新的区块链类。pythonclassBlockchai
-

UnittestUnittest是python内置的单元测试框架。它提供了一组全面的断言方法,用于比较实际结果和预期结果。Unittest还可以轻松分组和组织测试用例,并生成详细的测试报告。PytestPytest是一个功能丰富的测试框架,扩展了unittest。它支持更灵活的测试编写,例如使用fixtures设置测试环境,使用参数化测试方法以及创建自定义报告。Pytest与各种插件集成,允许开发人员扩展其功能。NoseNose是一个流行的测试运行器,可以简化测试发现和执行过程。它可以自动检测测试用例,并
-
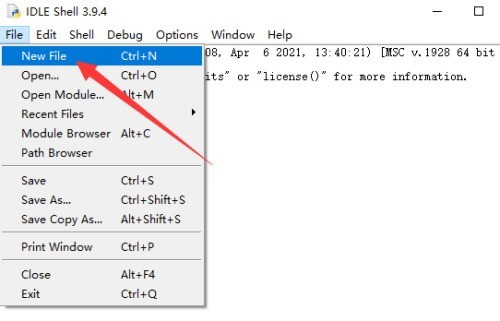
1、首先在python编辑器中,点击【File——NewFile】,新建文件。2、然后输入需要的程序代码之后,点击【File】。3、最后点击SaveAs去保存文件即可。
-

为什么在Geany中使用UTF-8无法正确显示中文?在Geany使用UTF-8后,中文乱码的原因是Geany...
-
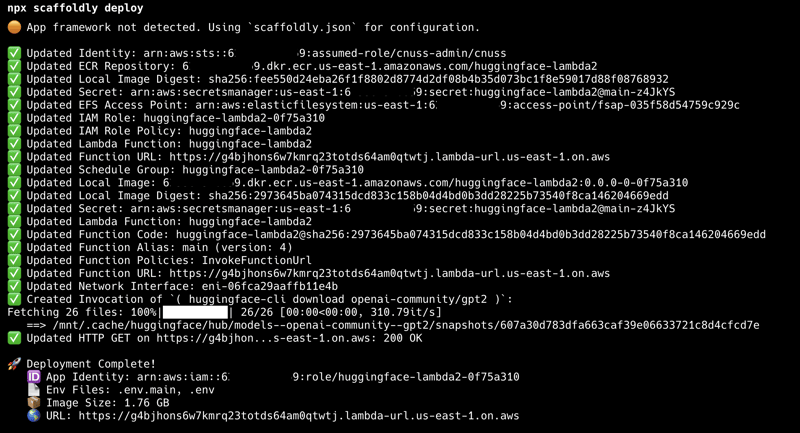
是否曾经想将huggingface模型部署到awslambda,但却被容器构建、冷启动和模型缓存所困扰?以下是如何使用scaffoldly在5分钟内完成此操作。长话短说在aws中创建名为.cache的efs文件系统:转到awsefs控制台点击“创建文件系统”将其命名为.cache选择任意vpc(scaffoldly会处理剩下的事情!)从python-huggingface分支创建您的应用程序:npxscaffoldlycreateapp--templatepython-huggingface部署它:cdm
-
几个python包进度条和tqdm:为循环、文件处理或下载等任务实现进度条。fromprogress.barimportchargingbarbar=chargingbar('processing',max=20)foriinrange(20):#dosomeworkbar.next()bar.finish()输出:processing████████████████████████████████100%tqdm:与进度条类似,但设置比进度条更简单。fromtqdmimporttqdmimporttim
-

为何选择LambdaRIC?LambdaRIC提供诸多优势,尤其在处理大型部署方面:Docker镜像支持更大规模部署(最大10GB):非常适合包含大量资源,例如OPA策略、大型代码库(而非简单的zip文件),并能实现更有效的资源管理。其优化的层管理和缓存机制进一步提升了效率。标准化环境:开发和生产环境保持一致,简化CI/CD流程,并提供统一的测试环境。同一容器可在本地和Lambda环境中运行。高度自定义:支持自定义运行时配置,方便集
-

Python通过format()方法或f-string控制十六进制输出格式和精度。1.使用{:04X}(或f"{number:04x}")指定输出格式,其中0表示用0填充,4表示宽度为4,X(或x)表示大写(或小写)十六进制字母。2.精度控制指整数部分位数,通过宽度参数控制。3.f-string通常比format()方法略快,但差异很小。熟练掌握格式化字符串语法,才能高效优雅地处理十六进制输出。
-

pytest测试结果中的符号含义解读在使用pytest...