-

通过Python学习选择排序的基本思想与应用选择排序(SelectionSort)是一种简单直观的排序算法,它的基本思想是从待排序的数据中选择最小(或最大)的元素放到已排序区域的末尾,然后再从剩余的未排序数据中选择最小(或最大)的元素放到已排序区域的末尾,以此类推,直到所有数据都排序完成。选择排序的具体步骤如下:首先,从待排序的数据中找到最小(或最大)的元
-

PyCharm是一款常用的Python集成开发环境(IDE),它提供了强大的功能和丰富的插件,方便开发者进行Python程序开发。然而,对于某些用户来说,初始字体大小可能不太符合个人的阅读习惯。本文将介绍如何在PyCharm中个性化设置字体大小。PyCharm提供了多种方法来调整字体大小。下面将详细说明三种常见方法:方法一:使用菜单栏进行设置打开PyChar
-

在python中,字符串是不可变的,意味着不能直接修改字符串的单个字符。但是可以通过一些方法来删除字符串中的部分内容。以下是一些常用的删除字符串内容的方法:利用切片操作删除字符串的一部分内容。切片操作用于提取字符串的一部分,如果不将提取的部分重新赋值给原字符串,就相当于删除了该部分内容。例如:string="Hello,World!"new_string=string[:7]+string[8:]print(new_string)#输出:HelloWorld!使用replace()方法
-

随着科技的不断发展,现今世界已经进入了信息时代,程序语言的发展和运用也越来越广泛。而Python作为一门以简单、易读、易学著称的高级编程语言,更是备受青睐。在Python中,正则表达式是一种十分重要和必须要了解的内置模块。通过使用Python正则表达式,可以进行文本的搜索、匹配和替换等操作。本文将详细介绍如何在Python编程中使用正则表达式。Part1:
-
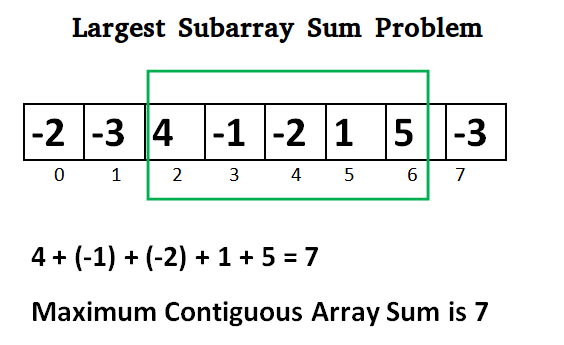
最大子数组问题及其历史20世纪70年代末,瑞典数学家ulfgrenander一直在讨论一个问题:如何比暴力破解更有效地分析二维图像数据数组?那时的计算机速度很慢,图片相对于ram来说也很大。更糟糕的是,在最坏的情况下,暴力破解需要o(n^6)时间(六次时间复杂度)。首先,grenandier简化了问题:给定一个一维数字数组,如何最有效地找到总和最大的连续子数组?蛮力:一种具有立方时间复杂度的简单方法蛮力,分析一维数组的时间是分析二维数组的一半,所以o(n^3)来检查每个可能的组合(立方时间复杂度)。def
-

如何判断是否存在于海量数据中?在面对海量数据时,快速确定一个元素是否存在至关重要。传统方法需要遍历...
-

切片:切片是python中用于提取序列的一部分的编程技术。通过指定索引范围,您可以检索序列的特定部分,而无需更改原始数据。示例:名称=[2,8]步骤运算符:步进运算符是指在循环中指定迭代增量的能力。在python中,这通常与range()函数一起使用,它允许指定一个步骤来控制循环变量在每次迭代后如何变化。示例:姓名[2:8:3]3是步骤运算符。使用两个变量的程序:start,end=1,6whileend>1:fornuminrange(start,end):print(num,end="")pri
-

PostgreSQL环境配置Windows下常见问题及解决方案在PostgreSQL...
-

Flask-Restful中使用jwt_required装饰器在Flask-Restful中,使用jwt_required装饰器来保护API...
-

数据类型的转换可以通过显式和隐式转换实现。1.数值类型之间的转换,如整数转浮点数。2.数值与字符串之间的转换,如数字转字符串。3.自定义类型之间的转换,如类对象间的转换。转换时需注意精度丢失、溢出和格式错误等问题。
-

学习Python需要具备以下基础知识:1.编程基础:理解变量、数据类型、控制结构、函数和模块。2.算法与数据结构:掌握列表、字典、集合等数据结构及排序、搜索等算法。3.面向对象编程:熟悉类、对象、继承、封装和多态。4.Python特有的特性:了解列表推导式、生成器、装饰器等。5.开发工具和环境:熟练使用PyCharm、VSCode等IDE,及虚拟环境和包管理工具。
-

Python中实现快速排序可以通过以下步骤:1.选择一个基准元素(pivot)。2.将数组划分为小于pivot的left,大于pivot的right,和等于pivot的middle。3.递归地对left和right进行排序,最后合并结果。示例代码为:defquicksort(arr):iflen(arr)<=1:returnarrelse:pivot=arr[len(arr)//2]left=[xforxinarrifx<pivot]middle=[xforxinarrifx==pivot]r
-

学习Python的路径应从基础语法开始,逐步深入到高级用法和性能优化。1.掌握基本编程概念和Python安装。2.学习基本语法和数据结构。3.理解函数、模块和面向对象编程。4.熟悉基本和高级用法。5.掌握常见错误调试和性能优化。通过实践和应用,你将逐渐掌握Python。
-

在Python中实现数据透视表的最佳方法是使用Pandas库的pivot_table函数。1)创建示例数据框。2)使用pivot_table按日期和地区汇总销售数据。3)调整参数生成不同透视表,如按产品和地区汇总。4)注意数据清洗和性能优化,处理多级索引和常见错误。
-

在Python中处理爬取数据主要使用BeautifulSoup解析HTML、json模块处理JSON和xml.etree.ElementTree解析XML。1)使用BeautifulSoup从HTML中提取标题和段落。2)用json.loads()解析JSON数据。3)用xml.etree.ElementTree从XML中提取信息。数据处理还包括清洗、转换和存储,通常使用pandas库进行操作。