-

__iter__必须返回迭代器对象,因Python内置操作依赖__next__和StopIteration;返回列表或错误self会破坏协议;正确方式是返回self(需实现__next__)或新迭代器(如生成器)。
-

swappiness=0不能完全禁用swap,因NUMA下numa_balancing触发zone_reclaim时若vm.zone_reclaim_mode含bit2(值为2/3/6/7),会无视swappiness强制swap;彻底禁用需设vm.zone_reclaim_mode=0并关闭numa_balancing。
-

Linux平台下使用Python脚本进行网络编程的技巧在今天的互联网时代,网络编程成为了一门重要的技术,无论是网站开发、数据传输还是服务器搭建,都少不了网络编程的支持。而Python作为一门简洁而强大的编程语言,也提供了丰富的库和模块,使得网络编程变得更加简单和高效。本文将介绍在Linux平台下使用Python脚本进行网络编程的一些技巧,同
-

Python中的序列化和反序列化技巧的最佳实践是什么?序列化和反序列化是在数据存储、数据传输等场景中常用的技术。在Python中,通过序列化和反序列化可以将一个对象转化为可以存储或传输的格式,然后再将其重新转化回对象。本文将介绍Python中序列化和反序列化的最佳实践,包括使用pickle和json库,以及如何处理自定义对象的序列化和反序列化。使用pickl
-

Scrapy框架实践:抓取简书网站数据Scrapy是一个开源的Python爬虫框架,可用于从万维网中提取数据。在本文中,我们将介绍Scrapy框架并使用它来抓取简书网站的数据。安装ScrapyScrapy可以使用pip或conda等包管理器来安装。在这里,我们使用pip来安装Scrapy。在命令行中输入以下命令:pipinstallscrapy安装完成后
-

掌握Python中安装NumPy库的技巧与方法,需要具体代码示例Python是一种非常强大的编程语言,但是它在进行科学计算和数值运算方面稍显不足。为了克服这个问题,许多开发者开发了各种科学计算库,其中一个最流行且功能强大的就是NumPy库。NumPy是Python中最基础和最重要的科学计算库之一,可以帮助我们进行高效的数组处理和数值运算。本文将介绍如何在Py
-

python作为一门多功能、易于学习的编程语言,凭借其丰富的库和社区支持,在计算机视觉领域发挥着日益重要的作用。本文将探讨Python在图像处理和分析方面的应用,并展示其在计算机视觉领域的强大优势。1.Python库:助力图像处理与分析Python拥有众多功能强大的库,可轻松实现图像处理和分析。其中最常用的包括:OpenCV:计算机视觉领域的标配库,提供图像处理、分析和机器学习功能。NumPy:用于科学计算的库,提供高效的数值计算功能。SciPy:科学计算库,提供信号处理、统计和优化等功能。Matplot
-

使用NumPyRandom.normal设置上限和下限如何在使用NumPy的random.normal...
-

如果您已经使用python了一段时间,尤其是在数据抓取的特定情况下,您可能遇到过在尝试检索所需数据时被阻止的情况。在这种情况下,了解如何使用代理是一项方便的技能。在本文中,我们将探讨什么是代理、它们为何有用,以及如何通过python中的库请求来使用它们。什么是代理?让我们从头开始定义什么是代理。您可以将代理服务器视为计算机和互联网之间的“中间人”。当您向网站发送请求时,该请求首先通过代理服务器。然后,代理将您的请求转发到网站,接收响应并将其发送回给您。此过程会屏蔽您的ip地址,使请求看起来像是来自代理服务
-
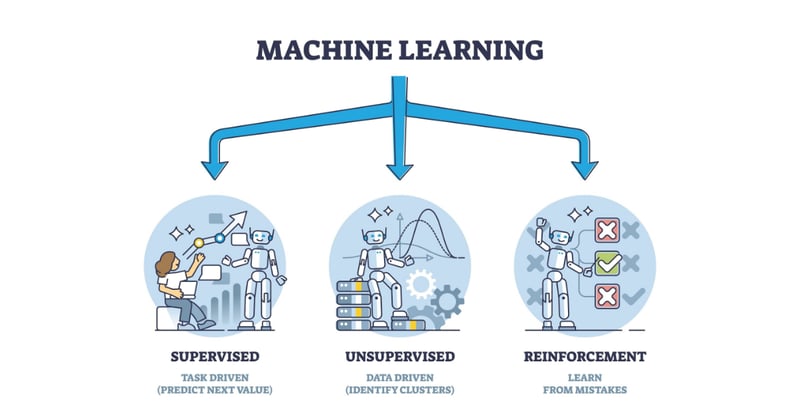
机器学习(ML):开启人工智能时代的新篇章机器学习是当今最激动人心、最具颠覆性的技术之一,它正在改变着各个行业的面貌,从个性化推荐到自动驾驶,其影响力日益显著。但机器学习究竟是什么?它如何运作?本文将用简洁易懂的语言,为您揭开机器学习的神秘面纱。什么是机器学习?简单来说,机器学习是人工智能(AI)的一个分支,它赋予计算机从数据中学习并进行决策的能力,无需人工编写针对每种情况的具体规则。我们只需提供数据给算法,算法便能学习其中的模式,从而进行预测或决策。例如,要构建一个识别照片中猫的系统,无需编写诸如“猫有
-

本文介绍了Python元组格式化输出和对齐技巧,主要方法是:1.使用str.format()方法,通过占位符{}和对齐标志(<,>,^)控制输出格式及宽度;2.使用f-string,语法更简洁,可读性更好,并可指定数据类型格式(如:.2f保留两位小数)。需注意元素类型一致性及宽度设置,大数据量处理可预先计算格式化字符串提升效率。清晰易懂的代码至关重要。
-

Python高效文件搜索替换方法是:1.使用os模块遍历文件,re模块利用正则表达式进行精准匹配替换;2.利用multiprocessing.Pool创建进程池,实现多进程并行处理,显著提升效率;3.可进一步优化,例如:增量式替换减少IO操作,备份原始文件防止数据丢失,开发图形界面提升用户体验,优化正则表达式提高效率,并注意代码可读性和异常处理。通过这些步骤,可以构建一个高效、强大的文件搜索替换工具。
-

Anaconda环境下缺失包的解决方法在使用Anaconda进行Python开发时,经常会遇到某些需要的包未安装的情况。例如,�...
-

Node.js和Python...
-

本地安装Python包失败:只创建dist-info文件夹而非包文件在使用pipinstall...