-

条件语句:基于条件执行代码if语句:用于根据给定条件执行代码块。可以使用elif和else子句处理其他情况。while循环:只要条件为真,就反复执行代码块。for循环:遍历序列中的每个元素,并在每次迭代中执行代码块。分支语句:非线性代码执行break语句:立即退出循环或switch语句。continue语句:跳过循环中的剩余代码,继续执行下一轮迭代。return语句:从函数返回一个值,并立即退出函数。pass语句:用作占位符,表示该代码块不会执行任何操作。错误处理:优雅地处理异常try-except块:将
-

讨论shutil.copytree添加多线程**我在python上写的讨论:https://discuss.python.org/t/add-multithreading-to-shutil-copytree/62078**背景shutil是python中一个非常有用的模块。你可以在github中找到它:https://github.com/python/cpython/blob/master/lib/shutil.pyshuutil.copytree是一个将文件夹复制到另一个文件夹的函数。在这个函数中,
-

HandyHub:将客户与可靠的商人联系起来项目目的HandyHub旨在弥合客户与所在领域熟练商人之间的差距。我们的目标是简化寻找和雇用技工的流程,使客户更容易通过用户友好的平台获得管道、电气工作和维修等基本服务。团队成员、角色和时间表HandyHub项目是ALXSE计划最终项目的一部分,开发团队包括:BislonZulu(我自己):负责后端开发,包括数据库设计、API创建和整体项目架构。项目时间表:开发正在进行中,最小可行产品(MVP)目前已完成并正在审查中。HandyHub适合谁?HandyHub服务
-

启动独立进程执行命令有时候需要Python脚本启动其他程序,并且希望它们在Python脚本执行完成后继续运行。以下...
-

京东滑块验证码的破解策略在使用Selenium...
-

人工智能已经成为各种规模企业的游戏规则改变者,为从客户服务到供应链管理的各个方面提供变革性解决方案。但面对如此多类型的人工智能模型,您如何确定哪一种最适合您的特定业务需求?了解不同人工智能模型的基础原理和功能对于做出明智的选择至关重要。为什么选择正确的人工智能模型很重要选择正确的人工智能模型会影响您企业的效率、成本效益和对未来变化的适应性。正确的人工智能模型不仅应该满足当前的需求,还应该能够扩展,以随着业务的发展满足未来的需求。选择正确的模型有助于确保您的用例获得最佳结果,从而最大限度地提高人工智能技术的
-

元组:Python中有序、不可变的数据结构元组是Python中一种内置的数据结构,它以固定顺序存储多个项目。一旦创建,元组的内容就不能更改。与列表类似,元组可以包含重复的值和混合数据类型(其他元组、列表、数字、字符串等)。元组的元素可以通过索引访问,索引从0开始。元组用圆括号()表示。t=(10,20,30)print(t)#输出:(10,20,30)print(type(t))#输出:<class'tuple'>fornumint:print(num)#输出:10,20,30(依次输出)to
-

我玩《Everspace2》有一段时间了,这款由ROCKFISHGames开发发行的动作冒险太空射击游戏让我爱不释手!在浩瀚的星系中驾驶飞船探险,体验感很棒。然而,游戏中一些显示元素的设计让我略感困惑。特别是游戏中的标记系统,用于在HUD上显示兴趣点。当视线无阻碍时,标记显示为白色;如有物体遮挡,标记则变为半透明的白色。问题在于,屏幕上物体众多且部分物体非常明亮时,这些半透明的标记就难以辨识。我尝试在游戏设置中寻找修改标记颜色的选项,但遗憾的是没有找到。为此,我开发了一个简单的PyQt5GUI,添加到游戏
-
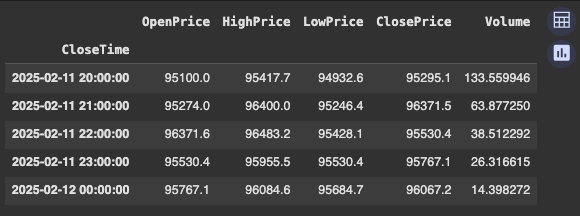
Pandas:Python数据分析利器,轻松驾驭海量数据Pandas是Python中最流行的数据分析库之一,无论数据集大小,都能轻松完成数据清洗、转换和分析。本文将演示如何使用Pandas获取和处理数据,并将其可视化。无需本地安装,GoogleColab提供基于云的JupyterNotebook环境,默认包含Pandas。首先,导入必要的库:importrequests#用于数据获取importpandasaspd#用于数据处理和可视化在使用API和Pandas之前,需要
-

程序启动方式的选择:Gunicorn的代码启动方法在使用异步框架Uvicorn时,可以直接通过uvicorn.run()函数在Python...
-

本文介绍了Python文本加密解密方法。1.首先演示了简单的Caesar密码,但其安全性低;2.随后使用pycryptodome库实现了更安全的AES加密,使用了CBC模式并进行了填充操作,强调了密钥管理的重要性;3.最后,提及了更高级的用法,如结合RSA和SHA-256算法,以及常见错误和性能优化方法。选择合适的加密方法取决于安全需求和性能要求,没有绝对安全的加密方法,持续学习才能更好地保护数据。
-

Django项目中文章置顶功能的到期处理在Django项目中,实现文章置顶功能并使其在指定时间后自动取消,是一个常...
-

关于pip3错误:“'_NamespacePath'对象没有属性'sort'”的解答在使用pip3安装Python包时,遇到“_NamespacePath...
-

在VSCode中配置Python开发环境需要安装以下插件:1.Python,2.Pylance,3.Jupyter,4.PythonTestExplorer。调试技巧包括:1.设置断点,2.使用条件断点,3.变量监视,4.远程调试。
-

TimeMachine和Python虚拟环境如何管理和备份工作成果并确保开发环境隔离?1.使用TimeMachine进行自动备份,保护数据并支持恢复到历史时间点。2.通过Python虚拟环境(如venv)为每个项目创建独立环境,避免依赖冲突。