-

使用pipenv环境轻松构建可靠的开发环境开发环境的构建对于开发人员来说非常重要。一个稳定、可靠且易于管理的开发环境能够提高开发效率,减少错误和冲突。在Python项目的开发中,pipenv是一个非常有用的工具,它能轻松帮助我们构建一个稳定的开发环境。什么是pipenv?pipenv是一个Python开发环境管理工具,它结合了pip和virtualenv的功
-

代码规范利器:PyCharm批量缩进功能的实际应用引言:在软件开发领域,代码规范是非常重要的一环。良好的代码规范不仅能提高代码的可读性和可维护性,还能减少潜在的bug。然而,在编写代码的过程中,经常会出现缩进不一致的问题,不仅影响代码的美观,还可能导致语法错误。本文将介绍PyCharm这一优秀的Python开发工具中的批量缩进功能,以及其在实际开发中的应用。
-

如何使用Python实现拓扑排序算法?拓扑排序是图论中的一种排序算法,用于对有向无环图(DAG)进行排序。在拓扑排序中,图中的节点代表任务或事件,有向边表示任务或事件之间的依赖关系。在排序结果中,所有的依赖关系都被满足,每个节点都排在它的所有前驱节点之后。在Python中实现拓扑排序算法可以使用深度优先搜索(DFS)的思想来解决。下面是一个具体的代码示例:f
-
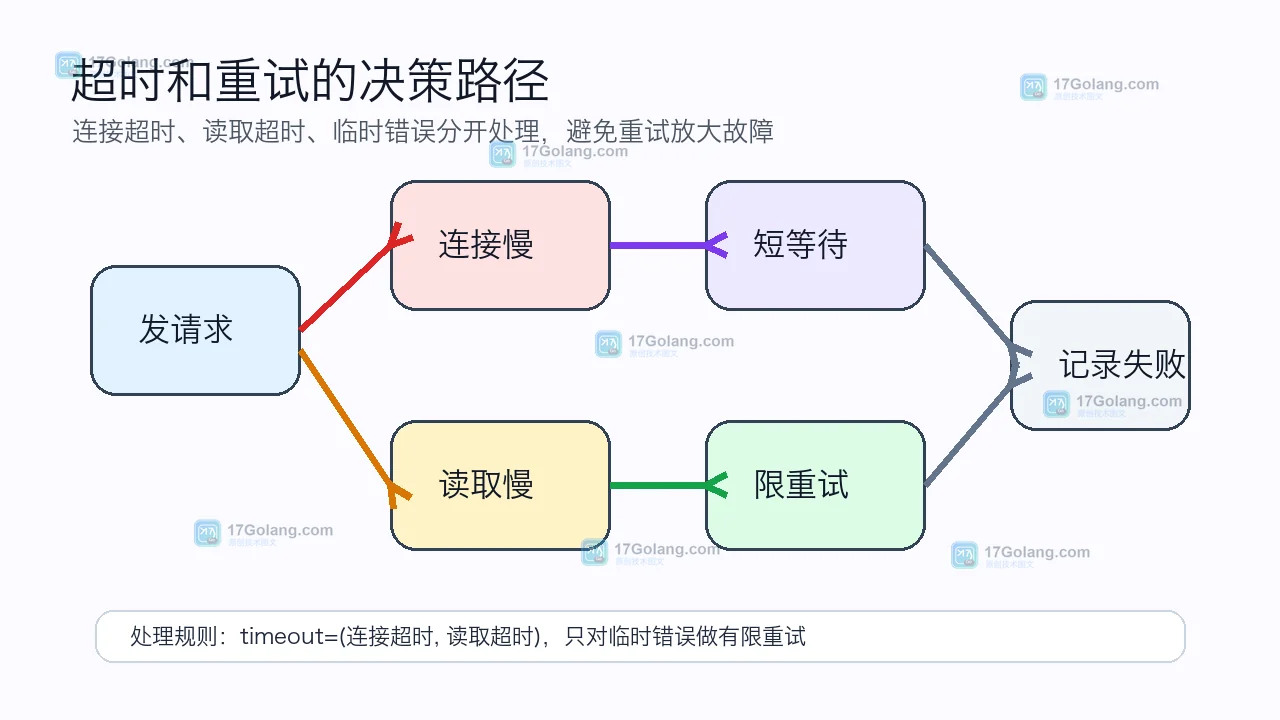
Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。
-
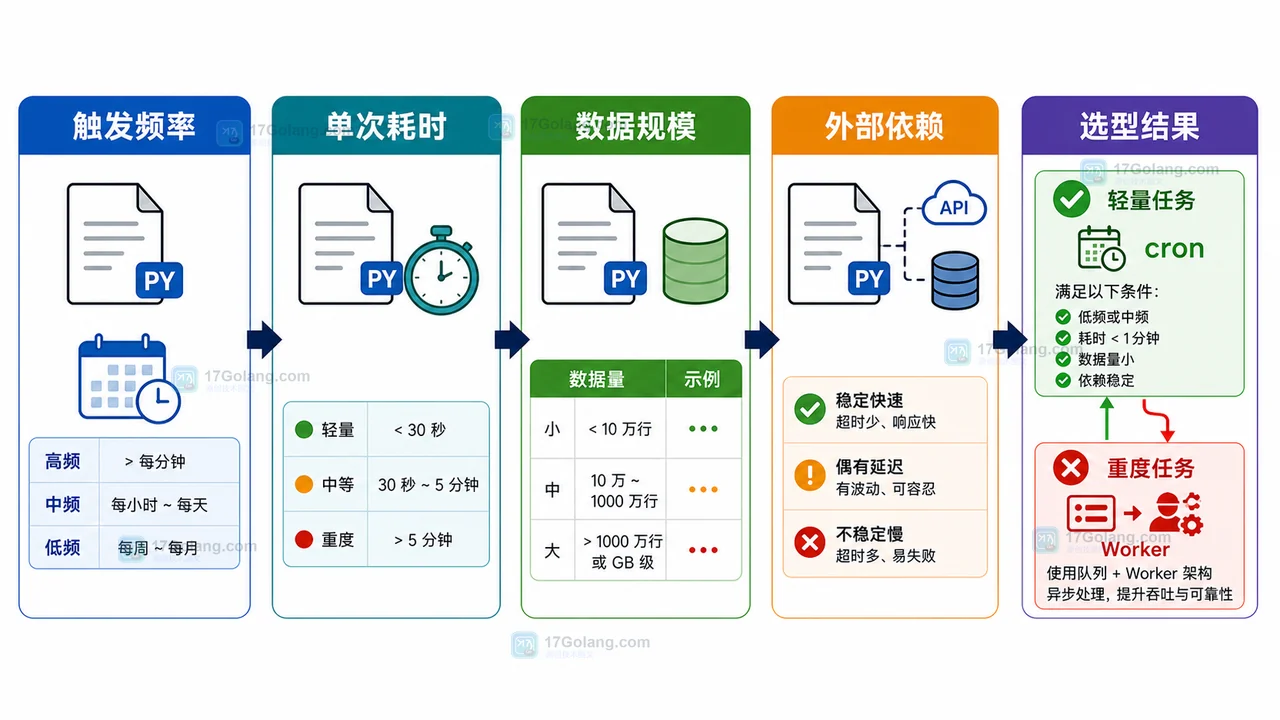
围绕 Python 定时任务上云,按负载、约束、方案对比、推荐架构、风险点和落地清单,比较单机 cron、容器任务、队列 Worker 和函数运行方案。
-

Python接口测试需双重校验状态码与业务码,分类型捕获requests异常,用安全取值和链式断言提升健壮性,通过参数化和mock构造异常场景并保留curl命令便于复现。
-

Python处理JSON依赖json模块,核心是loads()解析字符串、load()读文件、dumps()转字符串、dump()写文件;需注意数据类型、编码、异常处理及with语句资源管理。
-

可通过engine.pool.checked_out()和engine.pool.checked_in()获取当前借出与空闲连接数,二者之和反映实时使用状态;需结合SELECT1执行检测真实可用性,并监控checked_out持续上升以定位连接泄漏。
-

本文介绍如何通过协变TypeVar、Protocol和@overload组合,构建支持多次叠加装饰、严格校验参数类型且不强制窄化的Python类型安全事件注册机制。
-

Flask-GraphQL路由需用add_url_rule注册GraphQLView.as_view,schema须为实例化对象,graphiql仅开发开启;resolver应通过info.context传依赖,ID参数优先用graphene.ID,分页用first/offset显式声明,默认值设在参数侧;Schema避免循环引用,类型必须真实导入或用LazyType。
-

本文介绍使用pd.concat()配合列表乘法高效实现DataFrame行的整块重复,严格保持原始行序,避免index.repeat()导致的“逐行展开式”排序问题。
-

GIL未被移除是因为移除会破坏CPython引用计数内存管理、导致C扩展兼容性灾难、实际收益有限,且已有multiprocessing等成熟替代方案。
-

Python连接字符串最常用方法是f-string(推荐)和join(),加号(+)适用于已知全为字符串的简单拼接,需注意类型一致;f-string简洁高效支持表达式,join()适合批量合并带分隔符的字符串。
-

列表推导式和字典推导式是Python中提升代码简洁性与可读性的核心技巧,用一行表达式替代多行循环+条件判断,语法分别为[表达式for变量in可迭代对象if条件]和{键:值for变量in可迭代对象if条件},需避免副作用、过度嵌套,注重可读性。
-

Python数据可视化核心是用图表讲清数据故事,需按序安装Matplotlib、Pandas、Seaborn三库,从散点图理解参数逻辑,依分析目标选图型,并通过单位、图例、字体三步提升可读性。