-

Anaconda多语言虚拟环境配置详解在Anaconda中创建虚拟环境,方便管理不同项目的依赖包,是提高开发效率的关键�...
-

Python矩阵精确格式化输出可通过NumPy的np.set_printoptions函数实现。1.使用precision参数控制小数位数;2.使用suppress参数抑制科学计数法;3.使用linewidth参数控制每行输出字符数,避免输出过长。通过合理设置这些参数,可以有效提升矩阵输出的可读性和美观度,最终输出赏心悦目的矩阵。
-

Python密码生成器:算法深度解析你是否想过一个安全密码究竟是如何生成的?那些看似随机的字符组合背后,隐藏着哪些精妙的算法?这篇文章,我们就深入探讨几种Python实现的密码生成算法,并揭示其内在机制和潜在的陷阱。读完后,你将能够独立编写高效安全的密码生成器,并对密码安全有更深刻的理解。基础铺垫:随机数与熵密码生成的基石是高质量的随机数。Python的random模块提供了伪随机数生成器,但对于安全性要求较高的密码生成,这远远不够。我们需要的是真随机数,它依赖于系统的熵池,也就是系统收集
-

“str”对象没有“pop”属性的含义在Python...
-

在当今快节奏的世界中,快速信息检索是必要的,因为它会影响生产力和效率。对于应用程序和数据库也是如此。许多开发的应用程序通过后端接口与数据库协同工作。了解查询优化对于保持可扩展性、降低延迟和确保降低费用至关重要。本文将揭示优化数据库查询的先进技术,特别是django上的查询,以及它们对查询性能的影响。什么是查询优化?查询优化通过选择最有效的方式来执行给定查询来提高数据库速度和有效性。让我们在解决问题的背景下理解这一点。当然,解决问题的方法有很多种,但最有效的方法会节省更多的时
-

为什么改了子弹长度参数,但子弹长度还是不变?这个问题与设置类中的bullet_height参数设置有关。以下代码段�...
-

psycopg2执行大数据量SQL卡死的原因及其解决方法在使用psycopg2处理大数据量SQL时,经常会遇到执行execute(sql)后程�...
-

随着我们即将迈入2025年,游戏体验正在迅速发展,强化学习(RL)成为更智能、更具适应性的游戏AI背后的关键驱动力。强化学习使角色和不可玩角色(NPC)能够调整自己的行为,使游戏体验对玩家来说更具挑战性和身临其境。但强化学习到底是什么?它如何重塑游戏开发?在深入研究其应用程序之前,了解有关强化学习及其基础知识的更多信息。什么是游戏中的强化学习?在强化学习中,人工智能代理通过与其环境交互来学习做出决策。代理以奖励或惩罚的形式接收反馈,这有助于它随着时间的推移学习和适应。这种类型的AI允许NPC动态执行任务并
-

立志成为python认证入门级程序员(pcep)需要彻底了解python中的基本数据结构,例如列表和元组。列表和元组都能够在python中存储对象,但这两种数据结构在用法和语法上存在关键差异。为了帮助您在pcep认证考试中取得好成绩,这里有一些掌握这些数据结构的基本技巧。1。了解列表和元组的区别python中的列表是可变的,这意味着它们可以在创建后进行修改。另一方面,元组是不可变的,这意味着它们一旦创建就无法更改。这意味着元组的内存需求较低,并且在某些情况下比列表更快,但它们提供的灵活性较低。列表示例:#
-
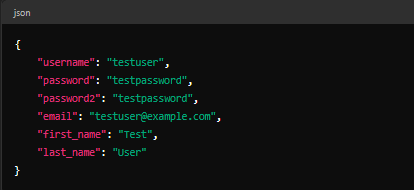
``##第四天#100daysofMiva编码挑战赛已经进行四天了。????深入了解Django:从头开始构建安全的用户身份验证API!您准备好将您的Django技能提升到新水平了吗??在本教程中,我将指导您使用Django创建强大的用户身份验证API。无论您是经验丰富的开发人员还是新手,本分步指南都将引导您完成设置用户注册、登录和基于令牌的身份验证。在本课程结束时,您将充分了解如何:设置Django项目并配置必要的包为用户数据创建和自定义序列化器构建视图来处理用户注册和身份验证实施基于令牌的身份验证以实
-

理解pythonGILPython的GIL(全局解释器锁)是一个独特的机制,它可以确保对Python对象的原子访问,避免多线程同时修改同一个对象时出现数据竞争。但是,GIL也会限制多线程编程的并行性,因为在同一时刻只能有一个线程执行Python字节码。GIL对多线程编程的影响GIL对多线程编程的主要影响是降低了并行性。在多线程编程中,当一个线程被GIL阻塞时,其他线程只能等待,无法同时执行。这可能会导致程序性能下降,特别是当程序需要执行大量的计算密集型任务时。释放多线程编程潜能的技巧为了释放多线程编程的潜
-

在使用Python进行开发时,我们经常会用到各种第三方库。而要安装这些库,我们需要使用pip包管理工具。然而,在Windows系统下安装pip并不如在Linux系统下那么简单。在本文中,我们将会一步步教你在Windows上安装pip,并附上详细的代码示例。Step1:下载Python首先,你需要安装Python。你可以到Python官网下载最新版本的Pyt
-

快速上手:pip换源方法详解,需要具体代码示例引言:在Python开发过程中,使用pip安装第三方库是非常常见的操作。然而,由于网络的原因,有时我们会遇到pip安装速度缓慢的问题。这是因为pip默认使用的是官方源,而官方源有时候会受到网络的限制。为了解决这个问题,我们可以通过更换pip源来提高安装速度。本文将详细介绍如何快速上手,通过更换pip源来提高安装速
-

快速了解numpy中常用的函数集合,需要具体代码示例随着数据科学和机器学习的兴起,numpy成为了Python中最常用的科学计算库之一。numpy不仅提供了强大的多维数组对象,还提供了丰富的函数集合,可以进行数学运算、数组操作、统计分析和线性代数等操作。为了快速了解numpy中常用的函数集合,下面将介绍一些常用的函数,并提供具体的代码示例。创建数组numpy
-

Python运算符详解:引领初学者走入高级使用者行列引言:Python作为一门简洁、强大且广泛应用的编程语言,其运算符号的使用无疑是每个Python学习者必须掌握的基本知识。运算符号不仅可以进行基本的数学计算,还可以进行字符串的操作、逻辑判断等等。本文将从初学者到高级使用者,详细讲解Python运算符,并附有具体的代码示例,帮助各位读者更好地理解和应用运算符