-

Python是一种高级编程语言,它被广泛应用于科学计算领域。Python具有简单易学、功能强大、拥有丰富的第三方库等优势,因此在科学计算中有着重要的应用。下面将介绍Python在科学计算领域的几个主要应用领域。1.数据分析与可视化Python的数据分析库如Pandas、NumPy和SciPy等提供了丰富的数据处理和分析工具。科学家和研究人员可以利用这些库进
-

Django是基于Python语言开发的Web框架,它提供了强大的功能和易于使用的设计,可以让开发者快速地创建灵活且可扩展的Web应用程序。在本文中,我们将介绍Django的一些最新演示,让您更好地了解这一框架的强大特性。强大的ORMDjango内置了强大的ORM(对象关系映射),可以让开发人员轻松地访问和操作数据库。ORM将数据库中的数据映射到Python
-

遇到pip安装慢?试试这个pip国内源教程,需要具体代码示例概述:在使用Python进行开发的过程中,我们经常会使用pip命令来安装各种依赖包。然而,由于众所周知的原因,国外的pip源有时候会变得非常慢,甚至无法连接。针对这个问题,我们可以使用国内的pip源来加快下载速度。本文将介绍如何配置国内的pip源,并给出具体的代码示例。步骤一:备份原有源文件在开始配
-

Python运算符号技巧与实践:提高计算效率的秘籍引言:在Python编程中,对于大多数的任务来说,程序的效率通常不是最重要的考量因素。然而,在处理大规模数据集或计算密集型任务时,优化代码以提高计算效率变得非常重要。Python提供了一些强大的运算符号技巧,可以帮助我们写出更高效的代码。本文将介绍一些常用的运算符号技巧,并提供具体的代码示例,帮助读者理解和应
-

基于DjangoProphet的销售预测模型的创建和调优,需要具体代码示例引言:在现代商业中,销售预测一直是非常重要的一项工作。准确的销售预测可以帮助企业有效地进行库存管理、资源调配和市场规划等决策,从而提高企业的竞争力和盈利能力。传统的销售预测方法往往需要大量的统计和数学知识,且工作效率较低。然而,随着机器学习和数据科学的发展,预测模型的应用在销售预测中
-

如何用Python编写贝尔曼-福特算法?贝尔曼-福特算法(Bellman-FordAlgorithm)是一种解决带有负权边的单源最短路径问题的算法。本文将介绍如何使用Python编写贝尔曼-福特算法,并提供具体代码示例。贝尔曼-福特算法的核心思想是通过逐步迭代来优化路径,直到找到最短路径为止。算法的步骤如下:创建一个数组dist[],存储从源点到其他顶点的
-

企业招聘中,Python编程技能在面试中的影响力随着信息技术的快速发展,各行各业对于拥有编程能力的员工的需求日益增加。而在众多的编程语言中,Python作为一门简单易学、功能强大的语言,尤其受到企业招聘人员的青睐。本文将探讨Python编程技能在企业招聘中的影响力。首先,Python作为一门简单易学的编程语言,对于初学者而言容易上手。相比其他编程语言,Pyt
-
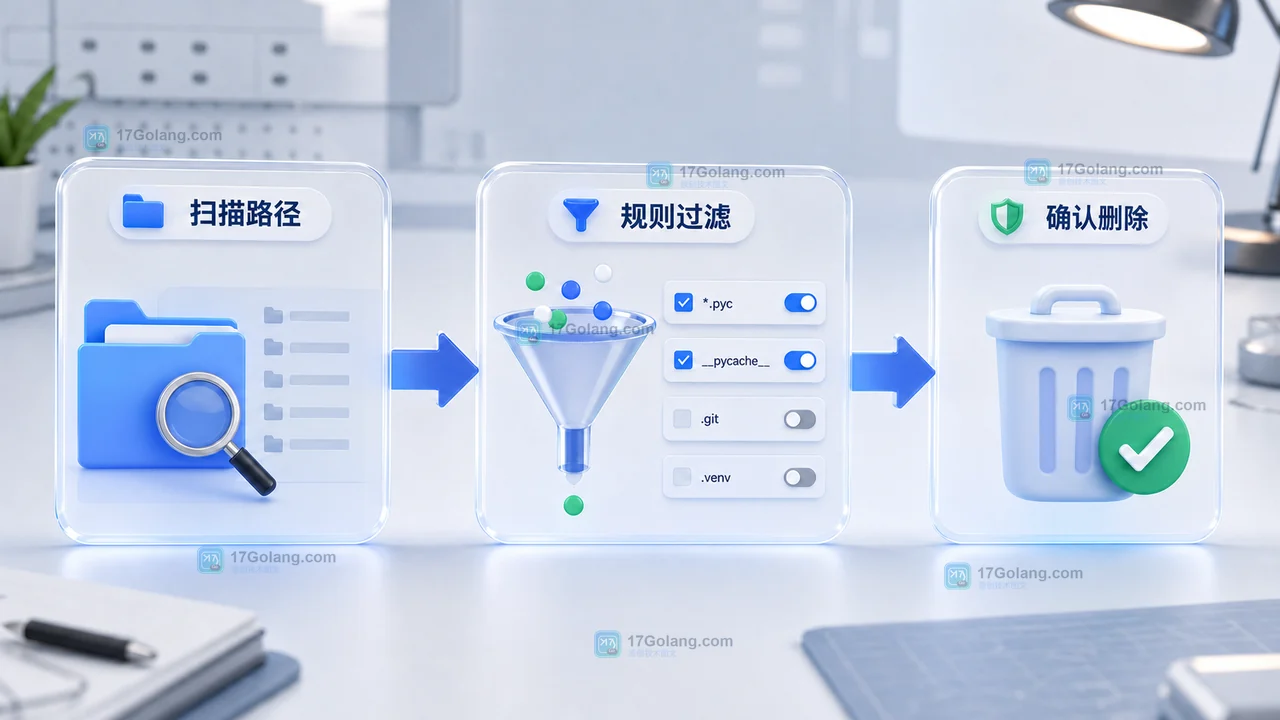
用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。
-

Canny边缘检测是OpenCV中目标边缘检测的核心方法,包含高斯滤波、梯度计算、非极大值抑制和双阈值滞后阈值化四步;需先灰度化、高斯去噪,合理设置双阈值,并辅以膨胀、轮廓提取等后处理提升实用性。
-

itertools.chain(*nested)是展开双层嵌套列表最省事的方法,不建中间列表、不递归、纯流式拼接,但需解包且要求子项为非字符串可迭代对象。
-

Python时间比较需确保类型一致、时区明确、精度合理:1.datetime与date不可直接比较,须统一类型;2.naive与awaredatetime不可比,应转为UTC-aware;3.浮点精度差异需归一化处理;4.timedelta仅可与timedelta比较,不可与datetime混用。
-

lambda只能写单个表达式,不能写语句;它是匿名函数,不支持return、if、for等语句,仅自动返回表达式结果,常见错误是语法非法或误用条件分支。
-

JSONDecoder默认不支持NaN和Infinity,因JSON标准禁止这些值;可通过object_hook或parse_float(需strict=False)实现兼容解析,但编码时仍需自定义处理。
-

sheet_name=None是读取Excel所有sheet的唯一正确方法,返回以表名为key、DataFrame为value的字典,不包含隐藏表,且需注意表名自动修正和内存占用问题。
-

plt.scatter画散点图时需将DataFrame列转为数组(如.values),c/s参数不接受Series;三维图须用ax.scatter(projection='3d');颜色尺寸映射需归一化或编码,NaN需预过滤。