-

PyCharm的激活界面可以通过以下方法打开:1.首次启动PyCharm时会自动弹出激活窗口。2.对于已使用一段时间的PyCharm,点击左上角“Help”菜单,选择“Register”或“ManageLicense”进入激活界面。
-

sum函数在Python中用于计算可迭代对象的总和。1)基本用法是sum(iterable,start=0),可用于数字和字符串。2)处理嵌套列表时,可用列表推导式。3)浮点数求和需注意精度问题,可用decimal模块。4)大数据集可使用numpy优化。5)结合生成器表达式可实现复杂计算,如平方和。
-

要快速进入PyCharm的编程界面并掌握进入编程模式的技巧,可以按照以下步骤进行:1.打开PyCharm后,选择“Open”或“NewProject”进入编程界面。2.熟悉快捷键,如Ctrl+Shift+A快速查找功能。3.设置舒适的编程环境,调整字体和主题。4.使用插件扩展功能,如代码格式化插件。5.创建代码模板以节省时间。6.保持项目结构清晰,利用PyCharm的项目管理功能。7.利用版本控制系统,如Git。8.定期休息以保持高效编程状态。通过这些技巧,你可以快速进入编程界面并提高编程效率。
-

<p>在Python中使用if语句的方法包括:1.基本用法:if条件:#代码块;2.多条件判断:使用elif和else;3.嵌套使用:形成复杂逻辑;4.优化建议:避免过度嵌套,使用逻辑运算符和字典映射条件。通过这些方法,可以编写出逻辑清晰、易于维护的代码。</p>
-

这篇文章提供了100道Python编程练习题,旨在帮助读者全面提升Python编程能力。1.基础知识回顾:Python支持多种数据类型,控制流包括条件语句和循环,函数支持高级用法,模块和包便于代码组织。2.核心概念解析:通过基本语法练习,如变量赋值、条件语句、循环和函数定义,巩固基础。3.算法与数据结构:介绍了排序算法和数据结构如栈的实现。4.使用示例:从基本用法如计算和判断,到高级用法如二分查找和图结构的实现。5.常见错误与调试:介绍了语法、逻辑、类型和索引错误的调试技巧。6.性能优化与最佳实践:建议使
-

在Python中遍历列表、元组、集合和字典的方法包括:1.列表和元组:使用for循环直接遍历。2.集合:使用for循环遍历,但顺序可能不同。3.字典:可以遍历键、值或键值对。4.高级用法:使用enumerate获取索引,或对字典值排序。
-

Python代码的基本结构包括模块、函数、类、语句和表达式。1.模块是代码组织的基本单位。2.函数是可重用的代码块,用于执行特定任务。3.类定义对象的属性和方法,支持面向对象编程。4.语句和表达式是代码的基本执行和计算单位。
-

如何定义和使用类的属性和方法?在类中定义属性和方法是编写类的核心任务。1)定义类的属性和方法:属性可以是任何数据类型,方法是类中的函数。2)使用类的属性和方法:通过对象访问和操作属性和方法,属性的访问和修改可以通过直接访问或通过getter和setter方法实现,方法的调用通过对象执行。
-

在Python中遍历列表、元组、集合和字典的方法包括:1.列表和元组:使用for循环直接遍历。2.集合:使用for循环遍历,但顺序可能不同。3.字典:可以遍历键、值或键值对。4.高级用法:使用enumerate获取索引,或对字典值排序。
-

Python程序在IDLE运行正常,但在桌面双击运行却出现问题:答案解析许多初学者在学习Python时,常常会遇到这样�...
-

在python中处理异常时,经常会遇到需要重新引发错误的情况。有两种主要方法可以做到这一点:raise和raisee。虽然乍一看似乎很相似,但这两种形式以不同的方式处理回溯,从而影响错误的记录方式以及最终的调试方式。在这篇文章中,我们将分解raise和raisee之间的区别,并讨论何时使用它们来进行更清晰、更可维护的错误处理。异常处理的基础知识在深入探讨差异之前,让我们回顾一下python中异常处理的工作原理。当try块中发生错误时,代码会跳转到except块,我们可以在其中优雅地处理错误或重新引发错误以
-

简化自动化脚本开发的库和框架推荐编写桌面端自动化脚本时,人们通常面临着操作繁复和开发耗时的挑战。本...
-

批量修改JSON文件中的指定内容作为一名Python初学者,您希望找到一种方法来批量修改目录中特定JSON...
-

Python中关联文件打开方式在编写加密文件程序时,你遇到一个难题:如何将打开方式设置为该加密程序。为了帮...
-
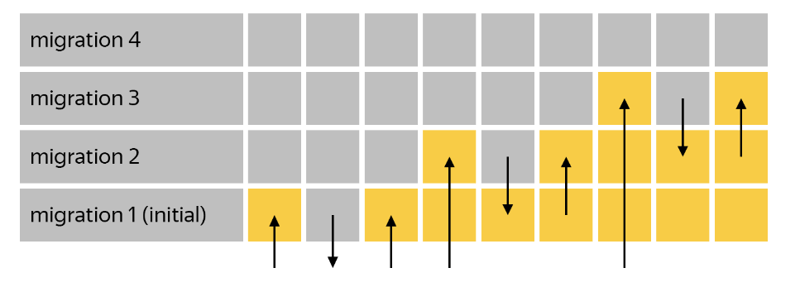
在本文中,我将简要介绍一些最佳实践,这些最佳实践在使用alembic和sqlalchemy时帮助保持项目有序、简化数据库维护并防止常见陷阱。这些技巧不止一次地让我摆脱了麻烦。以下是我们将介绍的内容:命名约定按日期对迁移进行排序表、列和迁移注释无模型迁移中的数据处理迁移测试(楼梯测试)运行迁移的服务对模型使用mixins1.命名约定sqlalchemy允许您设置命名约定,在生成迁移时自动应用于所有表和约束。这使您无需手动命名索引、外键和其他约束,从而使数据库结构可预测且一致。要在新项目中进行设置,请向基类添