-

追加操作在大文件和小文件上的速度差异在文件系统中,追加写是一种写入操作,它会在文件末尾追加内容,而...
-

LeapCell:PythonWeb托管、异步任务和Redis的最佳无服务器平台本文探讨PythonWeb应用中ASGI协议与Uvicorn服务器的关系。初学者常疑惑为何FastAPI开发需要Uvicorn,本文将解答此疑问。Uvicorn的作用以下是一个简单的HTTP请求示例,使用Uvicorn运行:importjsondefconvert_bytes_to_str(data):ifisinstance(data,bytes):
-

几年前,我重新实现了一种最初为工作中的规则引擎设计的领域特定语言(dsl)。该玩具重新实现是用javascript编写的(最初是用python编写的),并发布到github。我没想到它能做太多事情,因为它是专门为一个非常具体的用例而设计的,我不应该透露。bing副驾驶吐的一张有点可爱的照片设计的主要目标是可以轻松序列化。图灵完备性不是问题,因为我只需要它做两件事:简单的布尔比较(如果x==到y)从字典/哈希中的字段获取值我首先开始用python编写匿名函数。然而,当我尝试将工作分散到一组线程/进程时,解释
-

pyinstaller生成可视化界面,ffmpeg命令窗口弹出你使用pyinstaller将可视化界面程序生成为exe,但在运行时仍然在生�...
-

pydantic库validator的per参数问题问题:在使用pydantic库的validator装饰器时,将per参数设置为True...
-

请我喝杯咖啡☕*备忘录:我的帖子解释了flatten()和ravel()。我的帖子解释了unflatten()。flatten()可以通过从零个或多个元素的0d或多个d张量中选择维度来移除零个或多个维度,得到零个或多个元素的1d或多个d张量,如下所示:*备忘录:初始化的第一个参数是start_dim(optional-default:1-type:int)。初始化的第二个参数是end_dim(可选-默认:-1-类型:int)。第一个参数是输入(必需类型:int、float、complex或bool的张量)
-

Django和DjangoREST是Python中的高级框架,可能会争论它们是否不同,所以它们是吗?DjangoREST用于构建API(应用程序编程接口),而Django用于Web应用程序。尽管如此,我们还是会得出结论,所以让我们进一步探索。姜戈是什么?它是一个遵循模型-视图-模板(MVT)模式的高级框架。它处理前端和后端开发,为标准Web应用程序提供功能。利用对象关系映射(ORM)简化数据库交互并遵守DRY(不要重复自己)原则。处理URL路由、模板渲染、数据库管理。它与django模板紧密结合。什么是D
-

如何利用递归实现字符串分割算法在计算机编程中,递归是一种常用的技术,它允许函数调用自身以解决问题。...
-

如何在请求失败后将URL压入队列并重试?在Python...
-

长话短说本质上,这允许您为您创建的每个python应用程序创建一个隔离的环境。这意味着每个应用程序可以使用不同的库,甚至同一库的不同版本,而不会互相干扰。什么是venvpython虚拟环境或venv是一个轻量级的独立目录树,其中包含特定版本python的python安装,以及许多附加包。您创建的每个python应用程序都可以使用自己的虚拟环境。这解决了应用程序之间需求冲突的问题。venv模块用于创建虚拟环境。如何安装venvpipinstallvirtualenv创建虚拟环境python-mvenv/pa
-

要获取元组中的数据,可以通过索引号或切片来访问元组中的元素。通过索引号访问元组中的元素:my_tuple=(1,2,3,4,5)print(my_tuple[0])#输出1print(my_tuple[3])#输出4通过切片访问元组中的元素:my_tuple=(1,2,3,4,5)print(my_tuple[1:4])#输出(2,3,4)print(my_tuple[:3])#输出(1,2,3)print(my_tuple[2:])#输出(3,4,5)可以使用负数索引号来从元组的末尾开始计算索引,例如-
-

在数据获取方面,Web爬虫已成为一个必不可缺的工具。然而,对于那些刚开始学习和掌握Web爬虫技术的新手们来说,选择合适的工具和框架可能会让他们感到困惑。在众多Web爬虫工具中,Scrapy是一种非常流行的工具。Scrapy是一个开源的Python框架,它提供了一套灵活的方法来处理和提取数据。在这篇文章中,我将向大家介绍Scrapy的基础知识,并介绍如何在Sc
-

简单易用的PythonLinux脚本操作指南在Linux环境下,Python脚本是一种异常强大且易于使用的工具。Python的简洁语法和丰富的库使得编写脚本变得快捷和高效。本文将为您介绍一些简单易用的PythonLinux脚本操作,并提供具体的代码示例,帮助您更好地使用Python进行Linux系统管理和操作。文件和目录操作Python提供了一系列用于文
-

PythonforNLP:如何从PDF文件中提取并分析正文和引用文本?引言:与日俱增的文本数据使得自然语言处理(NaturalLanguageProcessing,简称NLP)在各个领域中日益重要。现在,很多学术研究和行业项目使用PDF文件作为主要的文本来源。因此,从PDF文件中提取和分析正文和引用文本变得非常关键。本文将介绍如何使用Python来实
-
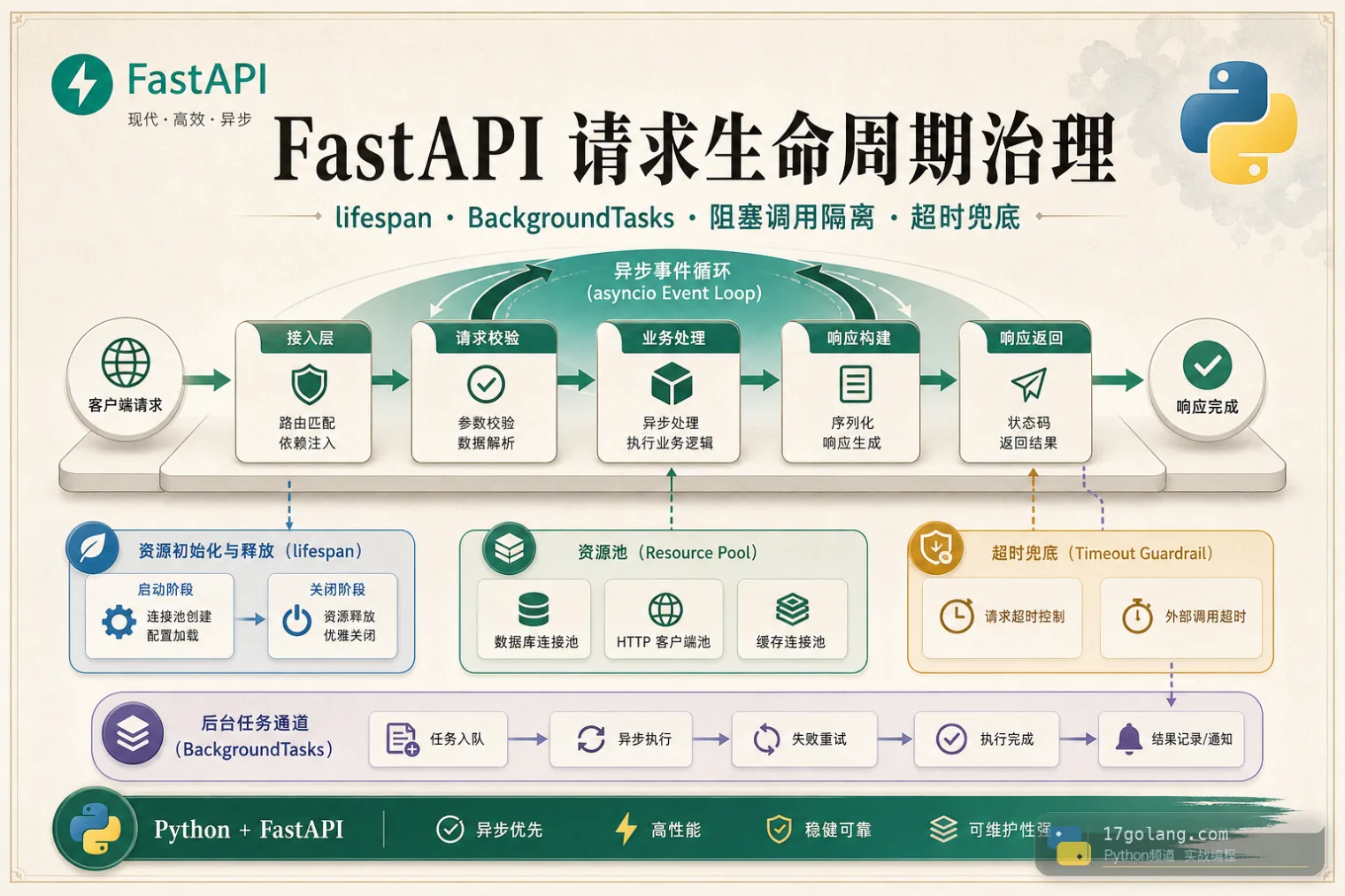
从 Python FastAPI 线上慢请求和后台任务丢失入手,讲清 lifespan 资源管理、阻塞调用隔离、BackgroundTasks 边界、超时和上线检查。