-

如何获取Selenium的WebElement中的不可见文本?Selenium的WebElement.text...
-

倒序读取Windows系统日志EVTX文件要从最后读取EVTX文件,需要反向迭代该文件。这可以在Python...
-

minioSDK是否可用于阿里云OSS?minioSDK和阿里云OSS虽然都兼容S3...
-

Python识别HTTP和HTTPS在处理大量网络相关数据时,识别URL中使用的协议(HTTP或HTTPS)至关重要。对于像www.example.com...
-

Python进程池无法创建子进程的解决之道在多任务处理中,使用进程池能有效避免系统进程数量限制。然而,当特...
-

Python线程中加锁范围大小的选择在Python线程编程中,对于加锁范围的确定一直存在一个争论:是大范围加锁好还...
-

列表中append和"+"...
-

2024年数据分析专业人员的就业市场将蓬勃发展,各行业的需求将超过供应。随着企业不断实现运营数字化,对熟练数据分析师的需求从未如此强烈。行业增长和需求根据世界经济论坛的数据,数据分析师和科学家是预计未来几年需求量最高的前五名职位。公司越来越依赖数据驱动的见解来做出明智的决策,导致对数据分析专业人员的需求激增。需求的关键技能数据分析领域正在不断发展,雇主正在寻找兼具技术和软技能的专业人士。Python和R等编程语言的专业知识以及SQL的熟练程度至关重要。此外,Tableau和PowerBI等数据可视化工具对
-

鉴于此练习:(来自codewars.com)创建一个返回数字每位数字的平方的函数。例如,输入函数时,数字702应该返回4904,因为7的平方是49,0的平方是0,2的平方是4。如果函数接收到零,则必须返回0.此练习的根本挑战是逐位遍历整数并返回结果作为另一个整数。就像编程中的一切一样,可以通过多种方式解决这个练习。首先,让我们使用python中的数字操作属性来解决它,然后我将解释另一种更高级的方法?.defsquare_digits(num):ifnum==0:return0result=""whilen
-

优化的代码至关重要,因为它直接影响软件的效率、性能和可扩展性。编写良好的代码运行速度更快,消耗的资源更少,并且更易于维护,使其更适合处理更大的工作负载并改善用户体验。它还降低了运营成本,因为高效的代码需要更少的处理能力和内存,这在资源有限的环境中尤其重要,例如嵌入式系统或大型云应用程序。另一方面,编写糟糕的代码可能会导致执行时间变慢、能源消耗增加以及基础设施成本更高。例如,在web应用程序中,低效的代码可能会减慢页面加载速度,导致用户体验不佳,并可能导致用户流失。在数据处理任务中,低效的算法会显着增加处理
-
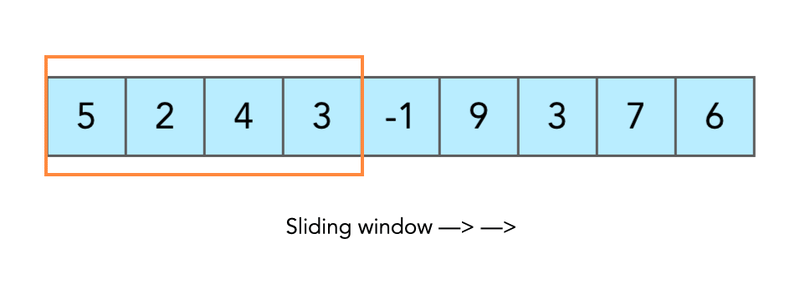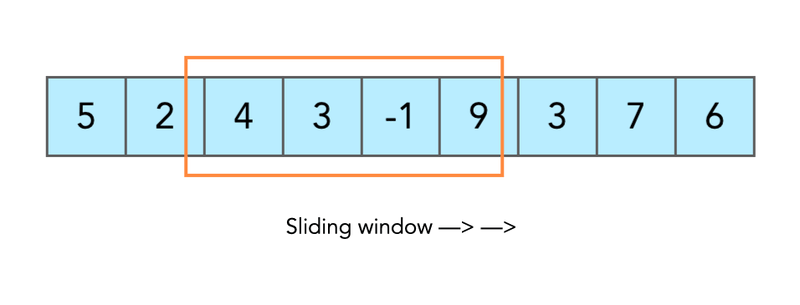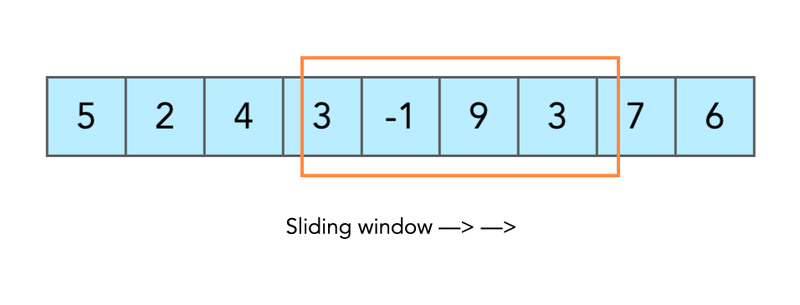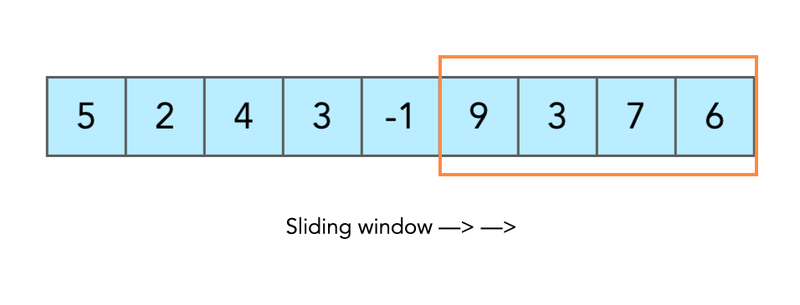
介绍今天我们将开始概述用于解决各种算法问题的概念。对某个概念的理解可能会给你一个直觉,从哪个角度开始思考潜在的解决方案。有不同但没有太多的概念。今天我将把你的注意力集中在滑动窗口概念上。滑动窗口滑动窗口的概念比乍一看要复杂一些。我将通过实际例子来证明这一点。现在,请记住,概念性的想法是我们将有一些必须移动的窗口。让我们立即从示例开始吧。假设您有一个整数数组和预定义的子数组大小。你被要求找到这样一个子数组(又名窗口),其值的总和将是最大的。array=[1,2,3]window_size=2#concept
-
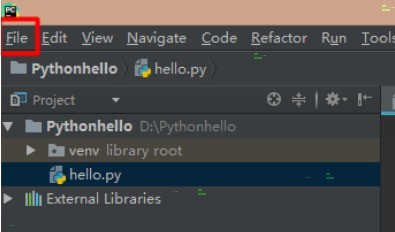
1、打开pycharm,点击右上角的file。2、在下拉菜单中点击settings。3、选择editor,点击右侧的font。4、在size中输入对应的数字,即可改变字体大小。
-

这里我们开发一个print_datetime函数来打印当前的时间,同时也将print_time函数作为我们需要一直保持执行的任务。#Importingthedatetimemodule.importdatetimedefprint_time(message=None):"""Itprintsthecurrenttime,optionallyprecededbyamessage.:parammessage:Themessagetoprint"""print(message,datetime.datetime
-
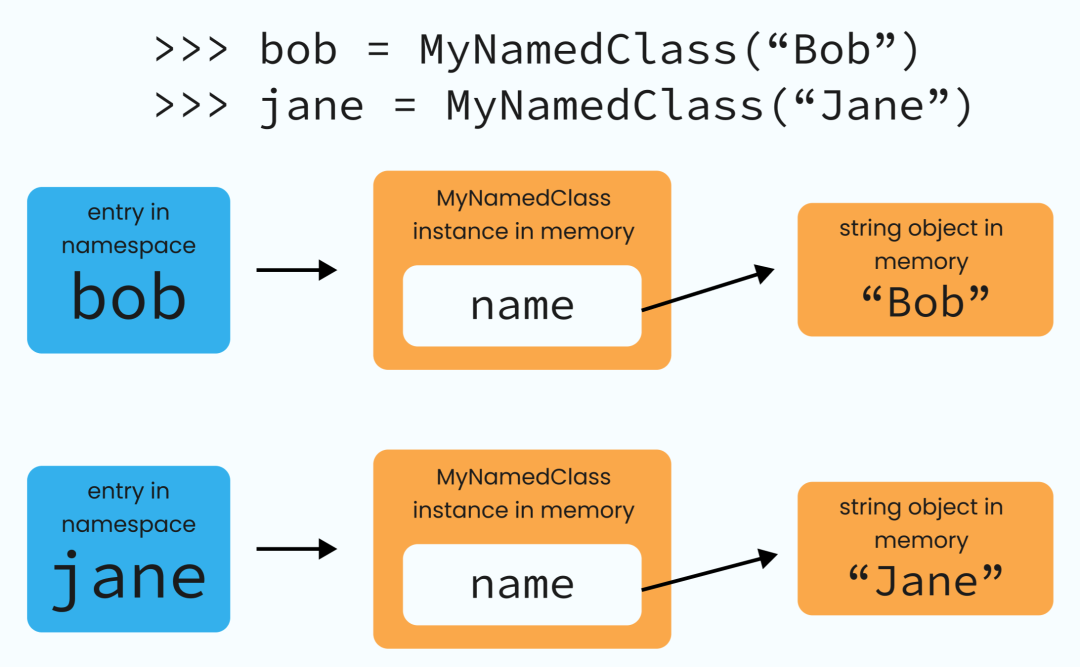
Python中的__del__魔法方法,也被称为对象的终结者,是一个在对象即将被从内存中移除之前被调用的方法。它实际上并不做从内存中删除对象的工作,我们将在后面看到它是如何发生的。相反,这个方法是用来做任何在对象被移除前需要发生的清理工作。例如,关闭对象在创建时打开的任何文件。在本节中,我们将使用下面这个类作为例子。classMyNameClass:def__init__(self,name):self.name=namedef__del__(self):print(
-

定义品牌定位确定品牌的价值观、使命和目标。识别目标受众并了解他们的需求和期望。清晰定义品牌的声音、语调和视觉识别。建立一致的品牌形象在所有接触点上保持一致的品牌形象,包括标识、网站、社交媒体和广告。使用高质量的视觉效果和文字内容来提升品牌形象。确保品牌体验在所有渠道上保持一致。创造引人入胜的内容开发相关、有价值的内容,以吸引目标受众。通过博客、文章、视频和社交媒体帖子建立思想领导地位。利用内容营销来推广品牌并吸引潜在客户。建立社群参加行业活动并与影响者建立联系。利用社交媒体建立与客户的紧密联系。创建忠诚度