-

构建Bing壁纸自动下载器:准备工作与代码实现本指南将引导您创建一个简单的Python脚本,自动下载Bing的每日壁纸。我们将分析Bing壁纸网页元素和API,并提供完整的代码示例。一、关键组件分析Bing壁纸API:Bing提供了一个JSONAPI接口,用于访问壁纸元数据,包括图像URL、标题和描述。主要API端点如下:https://www.bing.com/hpimagearchive.aspx?format=js&idx=0&n=1&mkt=en-usidx:壁纸索引(0代
-

1.打印此号码:1234554321no=1top=5direction=1whileno>0:print(no,end='')ifno==top:print(no,end='')direction=-1no=no+direction12345543212.猜数字游戏:importrandomsystem_no=random.randint(1,20)whiletrue:guess=int(input("entertheno."))ifguess==system_no:print("hurray!i
-

解决无项目困境,提升软件开发能力作为一名刚入职一年的毕业生,无法获得项目经验的情况并不少见。当公司...
-

如何使用Python控制“另存为”对话框问题:在使用Python和SeleniumWebdriver...
-

Python转码UTF-8后仍出现“'gbk'编解码器无法解码位置8的字节...
-

合理创建机器学习训练数据在机器学习中,构建用于训练模型的学习数据至关重要。然而,有时我们面临数据量...
-

什么是langgraph?langgraph是专为llm应用程序设计的工作流编排框架。其核心原则是:将复杂任务分解为状态和转换管理状态转换逻辑任务执行过程中各种异常的处理想想购物:浏览→添加到购物车→结账→付款。langgraph帮助我们有效地管理此类工作流程。核心概念1.国家状态就像任务执行中的检查点:fromtypingimporttypeddict,listclassshoppingstate(typeddict):#currentstatecurrent_step:str#cartitemscar
-

Scrapy管道数据库连接出错在学习Scrapy...
-

Python...
-

flask确实提供了多种将数据转换为响应的工具,从将python对象转换为json到创建结构化http响应。在这篇文章中,我们将探讨jsonify()、to_dict()、make_response()和serializermixin,它们是在flask中处理数据响应的四个有用的函数和工具。了解这些工具将有助于创建更好的api和有效的数据管理。jsonify()它是一个内置的flask函数,可将python数据结构转换为json格式,这是一种广泛用于apiweb开发的轻量级数据交换格式。该函数自动将响应c
-

api开发是现代软件应用程序的基石,从移动应用程序到web平台和微服务。然而,随着用户需求的增长,有效处理高负载请求的挑战也随之增加。python是一种多功能且功能强大的语言,经常因其在高负载场景下的性能限制而受到审查。但通过正确的技术,python可以顺利处理大规模api请求。已解决的端到端项目在本文中,我们将探索优化pythonapi的最佳实践和技术,以高效地每秒处理数百万个请求,最大限度地减少延迟并提高整体性能。python在api开发中的作用python因其简单性、丰富的生态系统以及快速原型设计和
-

Python中安装NumPy的详细教程NumPy(NumericalPython)是Python中重要的科学计算库之一,它提供了高性能的多维数组对象以及相关工具,可以用于进行各种数值计算和数据分析。本文将介绍如何在Python环境中安装NumPy,并提供具体的代码示例。一、检查Python版本首先,我们需要确保Python版本在2.7或3.4以上。可以通过
-
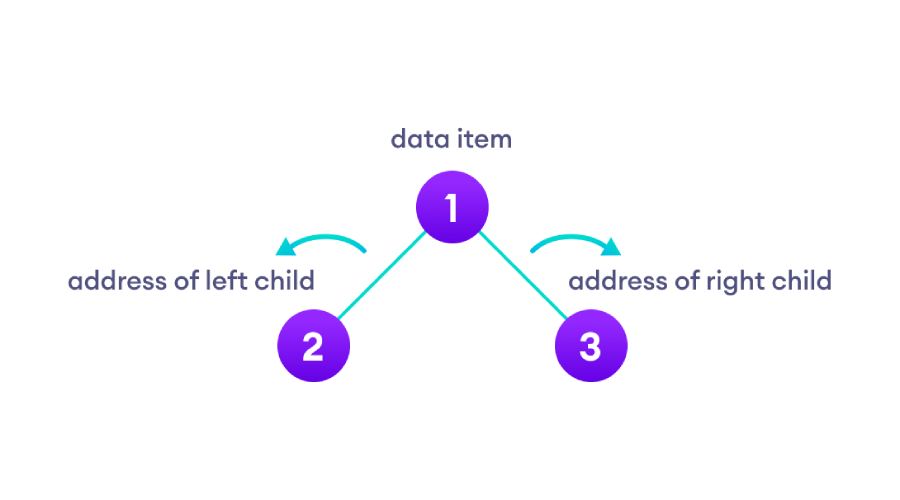
二叉树是一种树状数据结构,其中每个父节点最多可以有两个子节点。二叉树的类型完全二叉树完全二叉树是一种特殊类型的二叉树,其父节点存在2种情况,要么有2个子节点,要么没有子节点,详情如下图:完全二叉树定理1、叶数为i+12、节点总数为2i+13、内部节点数为(n–1)/24、叶数为(n+1)/25、节点总数为2l–16、内部节点数为l–17、叶子的数量最多2^λ-1Python判断完整二叉树classNode:def__init__(self,item):self.item=itemself.leftChil
-

想要升级Python库?先了解一下pip升级命令是什么!Python是一种非常流行的编程语言,有着丰富的库和扩展模块。使用Python开发项目时,经常需要安装和使用各种库。为了保证项目的稳定性和安全性,及时进行库的升级是很重要的。而pip是Python的官方包管理工具,通过它可以轻松地安装、升级和删除第三方库。为了更好地理解pip的升级命令,我将详细介绍pi
-

利用pandas进行数据清洗和预处理的方法探讨引言:在数据分析和机器学习中,数据的清洗和预处理是非常重要的步骤。而pandas作为Python中一个强大的数据处理库,具有丰富的功能和灵活的操作,能够帮助我们高效地进行数据清洗和预处理。本文将探讨几种常用的pandas方法,并提供相应的代码示例。一、数据读取首先,我们需要读取数据文件。pandas提供了许多函数