-

在Python中编写for循环使用for关键字和可迭代对象,如列表、字符串或范围。1)基本用法:foritemin[1,2,3,4,5]:print(item)。2)高级用法:结合enumerate和zip函数。3)注意陷阱:避免修改正在遍历的列表,使用列表副本。4)性能优化:使用列表推导式和内置函数如map、filter。
-

值得关注的Python技术大会和活动包括:1.PyCon,全球最有影响力的Python大会,提供从初学者到资深开发者的各种讲座和工作坊;2.EuroPython,欧洲最大的Python大会,涵盖Web开发到科学计算的多样化主题;3.PyData,专注于Python在数据科学和分析方面的应用;4.DjangoCon,专为Django框架的Web开发者设计;5.PyCascades,小而精的美国西海岸Python大会;6.PythonWebConf,专注于Python在Web开发中的在线会议。
-

使用Pandas处理百万级爬取数据的步骤包括:1)分块读取数据,2)处理缺失值和重复值,3)使用向量化操作和高级函数进行复杂处理,4)优化数据类型和使用并行处理。Pandas通过其高效的底层优化和丰富的函数库,使得大规模数据清洗变得更加高效和可控。
-

Python路径分割:轻松提取字符串中文件夹名称在处理文件路径时,我们经常需要提取路径中的各个文件夹名称。...
-

文章介绍了Python数值字段异常值处理方法。1.使用箱线图直观识别离群点;2.利用Z-score方法,基于标准差判断异常值;3.使用IQR方法,基于四分位距识别异常值,该方法对数据分布不敏感。处理策略包括删除、替换和转换,需结合实际情况选择。需注意阈值选择、数据分布和异常值类型,最终选择合适的策略取决于数据和任务。
-

如何采集类似HTML代码的图片地址给定的HTML...
-

python...
-

玩游戏是让大脑从一天的压力中放松下来的一种方式,或者只是从工作中休息一下。然而,有时,游戏本身就会带来压力,所以我认为“wordcookies”就是这样,这是一款有趣的益智游戏,你会得到一组打乱的字母,并被要求解决其中包含的单词。随着我在游戏中的进展,解决问题变得越来越困难,几乎没有资源可以帮助我,我多次陷入困境。但是等一下,我用python编写代码,为什么我找不到出路呢?这就是python语言大放异彩的地方。现在我如何使用python来解决混乱的问题。我需要一种方法来检查乱序字母中的单词,我将实现分解为
-
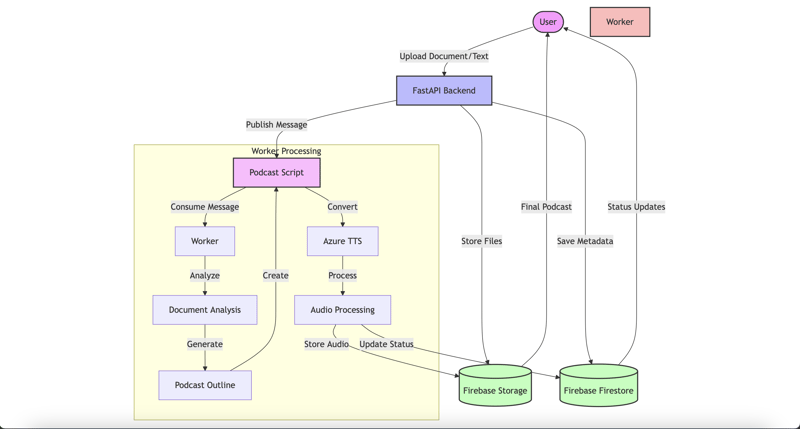
随着音频内容消费的日益普及,将文档或书面内容转换为真实音频格式的能力最近已成为趋势。虽然google的notebooklm在这个领域引起了人们的关注,但我想探索使用现代云服务构建一个类似的系统。在本文中,我将向您介绍如何创建一个可扩展的云原生系统,该系统使用fastapi、firebase、googlecloudpub/sub和azure的文本转语音服务将文档转换为高质量的播客。这里有一个展示,您可以参考该系统的结果:mypodifyshowcase挑战将文档转换为播客并不像通过文本转语音引擎运行文本那么
-

错误的astype返回值问题示例代码中使用了astype方法来将图像数组转换为float32...
-

Pythonpandas不同结构的DataFrame整列复制在pandas中,我们经常需要对不同结构的DataFrame...
-

pyspark如何帮助您像专业人士一样处理庞大的数据集pytorch和tensorflow等机器学习框架非常适合构建模型。但现实是,当涉及到现实世界的项目时(处理巨大的数据集),您需要的不仅仅是一个好的模型。您需要一种有效处理和管理所有数据的方法。这就是像pyspark这样的分布式计算可以拯救世界的地方。让我们来分析一下为什么在现实世界的机器学习中处理大数据意味着超越pytorch和tensorflow,以及pyspark如何帮助您实现这一目标。真正的问题:大数据您在网上看到的大多数机器学习示例都使用小型
-

什么是rag?rag代表检索增强生成,这是一种强大的技术,旨在通过以文档形式为大型语言模型(llm)提供特定的相关上下文来增强其性能。与纯粹根据预先训练的知识生成响应的传统法学硕士不同,rag允许您通过检索和利用实时数据或特定领域的信息,使模型的输出与您期望的结果更紧密地结合起来。rag与微调虽然rag和微调的目的都是提高llm的性能,但rag通常是一种更高效且资源友好的方法。微调涉及在专门的数据集上重新训练模型,这需要大量的计算资源、时间和专业知识。另一方面,rag动态检索相关信息并将其合并到生成过程中
-

人工智能和机器学习的整合人工智能(ai)和机器学习(ML)技术与python的集成正在改变数据分析。通过使用算法和模型,分析师可以自动化任务、提高预测准确性并从大型数据集识别模式。这种整合使数据分析更加高效和洞察力。大数据和云计算大数据和云计算平台使分析师能够处理和存储庞大的数据集。Python与hadoop、spark和云服务(如AWS、Azure和GCP)的集成,使分析师能够扩展其分析能力,处理实时数据并从分布式系统中提取见解。交互式数据可视化交互式数据可视化工具,如Plotly、Bokeh和Tabl
-

GIL(全局解释器锁)是python解释器的核心部件,它确保同一时间只有一个线程执行Python字节码。虽然GIL提供了线程安全性,但它也限制了Python在并发编程方面的潜力,因为线程只能串行执行。为了克服GIL的限制,出现了各种技术来规避其锁定并实现并发。这些技术包括:多线程:多线程是一种利用多个CPU线程来并行执行代码的技术。在Python中,使用threading模块可以创建和管理线程。然而,GIL限制了每个线程同时执行Python代码的能力。importthreadingdeftask():#执