-
 hashlib不支持运行时OpenSSL后端切换,其底层实现由Python编译时是否链接OpenSSL决定;可通过检查hasattr(m,'_hash')为True且m.name正常来确认使用C扩展(通常即OpenSSL优化版本)。342 收藏
hashlib不支持运行时OpenSSL后端切换,其底层实现由Python编译时是否链接OpenSSL决定;可通过检查hasattr(m,'_hash')为True且m.name正常来确认使用C扩展(通常即OpenSSL优化版本)。342 收藏 -
文章 · python教程 | 6天前 | 性能优化 · fastapi · 生产实践 · Python教程 · Pydantic · Python 性能优化 FastAPI Pydantic v2 TypeAdapter validate_json
 从 FastAPI 生产接口 P95 升高场景讲清 Pydantic v2 TypeAdapter 复用、validate_json、strict、FailFast 和压测验证。342 收藏
从 FastAPI 生产接口 P95 升高场景讲清 Pydantic v2 TypeAdapter 复用、validate_json、strict、FailFast 和压测验证。342 收藏 -
 微信Signature校验需手动实现,关键参数为signature、timestamp、nonce、echostr;timestamp和nonce须从request.GET正确获取,三者字典序拼接后UTF-8编码SHA1比对,echostr原样返回;Django视图须@csrf_exempt且路由路径与公众号后台URL严格一致;Token应统一配置于settings.py,避免硬编码;时间差超5分钟会导致校验失败。341 收藏
微信Signature校验需手动实现,关键参数为signature、timestamp、nonce、echostr;timestamp和nonce须从request.GET正确获取,三者字典序拼接后UTF-8编码SHA1比对,echostr原样返回;Django视图须@csrf_exempt且路由路径与公众号后台URL严格一致;Token应统一配置于settings.py,避免硬编码;时间差超5分钟会导致校验失败。341 收藏 -
 Tkinter默认会在按键长按时持续触发<Key>事件,本文详解如何通过KeyPress/KeyRelease绑定、状态标记或事件去抖策略,精准捕获每次物理按键的首次按下,并附带组合键(如Shift+1、数字+±)的可靠检测方法。Tkinter默认会在按键长按时持续触发``事件,本文详解如何通过`KeyPress`/`KeyRelease`绑定、状态标记或事件去抖策略,精准捕获**每次物理按键的首次按下**,并附带组合键(341 收藏
Tkinter默认会在按键长按时持续触发<Key>事件,本文详解如何通过KeyPress/KeyRelease绑定、状态标记或事件去抖策略,精准捕获每次物理按键的首次按下,并附带组合键(如Shift+1、数字+±)的可靠检测方法。Tkinter默认会在按键长按时持续触发``事件,本文详解如何通过`KeyPress`/`KeyRelease`绑定、状态标记或事件去抖策略,精准捕获**每次物理按键的首次按下**,并附带组合键(341 收藏 -
 reversed(lst)返回轻量迭代器,不复制元素、不占额外内存,仅支持单次遍历;lst[::-1]立即生成新列表,内存开销约1.5–2倍;需索引或复用时选切片,仅遍历时选reversed。341 收藏
reversed(lst)返回轻量迭代器,不复制元素、不占额外内存,仅支持单次遍历;lst[::-1]立即生成新列表,内存开销约1.5–2倍;需索引或复用时选切片,仅遍历时选reversed。341 收藏 -
 os.stat返回的stat_result对象包含st_atime(最后访问时间)、st_mtime(最后修改时间)、st_ctime(Windows为创建时间,Linux/macOS为元数据变更时间,非创建时间)三个时间字段。341 收藏
os.stat返回的stat_result对象包含st_atime(最后访问时间)、st_mtime(最后修改时间)、st_ctime(Windows为创建时间,Linux/macOS为元数据变更时间,非创建时间)三个时间字段。341 收藏 -
 Python列表、字典、集合的底层机制决定其性能与安全性:列表为动态数组,索引O(1)但中间增删O(n);字典基于哈希表,键须可哈希,查找平均O(1);集合是无序去重结构,成员检测O(1),空集合须用set()。341 收藏
Python列表、字典、集合的底层机制决定其性能与安全性:列表为动态数组,索引O(1)但中间增删O(n);字典基于哈希表,键须可哈希,查找平均O(1);集合是无序去重结构,成员检测O(1),空集合须用set()。341 收藏 -
 Python项目应通过环境变量驱动配置加载,采用base+env分层结构,敏感信息外部化,配合pydantic校验启动检查,确保各环境可预期、可复现、可审计。341 收藏
Python项目应通过环境变量驱动配置加载,采用base+env分层结构,敏感信息外部化,配合pydantic校验启动检查,确保各环境可预期、可复现、可审计。341 收藏 -
 Python自动化运营报告的核心是构建稳定可维护的数据获取、清洗、分析、绘图、排版、导出六步流水线,通过对接数据库/API、动态指标配置、批量图表生成、Jinja2模板组装HTML/PDF及定时任务实现无人值守交付。340 收藏
Python自动化运营报告的核心是构建稳定可维护的数据获取、清洗、分析、绘图、排版、导出六步流水线,通过对接数据库/API、动态指标配置、批量图表生成、Jinja2模板组装HTML/PDF及定时任务实现无人值守交付。340 收藏 -
 Python存储数据方式按需求分三类:内存变量适合临时使用但程序退出即丢失;文件(文本/JSON/CSV)实现简单持久化;数据库(SQLite/MySQL/PostgreSQL)支持结构化查询与多用户共享,另有pickle、HDF5、Redis等专用方案。340 收藏
Python存储数据方式按需求分三类:内存变量适合临时使用但程序退出即丢失;文件(文本/JSON/CSV)实现简单持久化;数据库(SQLite/MySQL/PostgreSQL)支持结构化查询与多用户共享,另有pickle、HDF5、Redis等专用方案。340 收藏 -
文章 · python教程 | 6天前 | sqlalchemy · 异步编程 · fastapi · 生产实践 · Python教程 · Python 连接池 FastAPI sqlalchemy asyncio AsyncSession
 从 FastAPI 生产接口连接池等待场景讲清 SQLAlchemy AsyncSession 并发使用、事务边界、连接池参数和上线检查。340 收藏
从 FastAPI 生产接口连接池等待场景讲清 SQLAlchemy AsyncSession 并发使用、事务边界、连接池参数和上线检查。340 收藏 -
文章 · python教程 | 1天前 | 异步编程 · 生产实践 · 后端工程 · Python教程 · Celery · 任务队列 · Python 故障排查 任务队列 异步任务 幂等 生产实践 Celery 5.4 retry_backoff acks_late
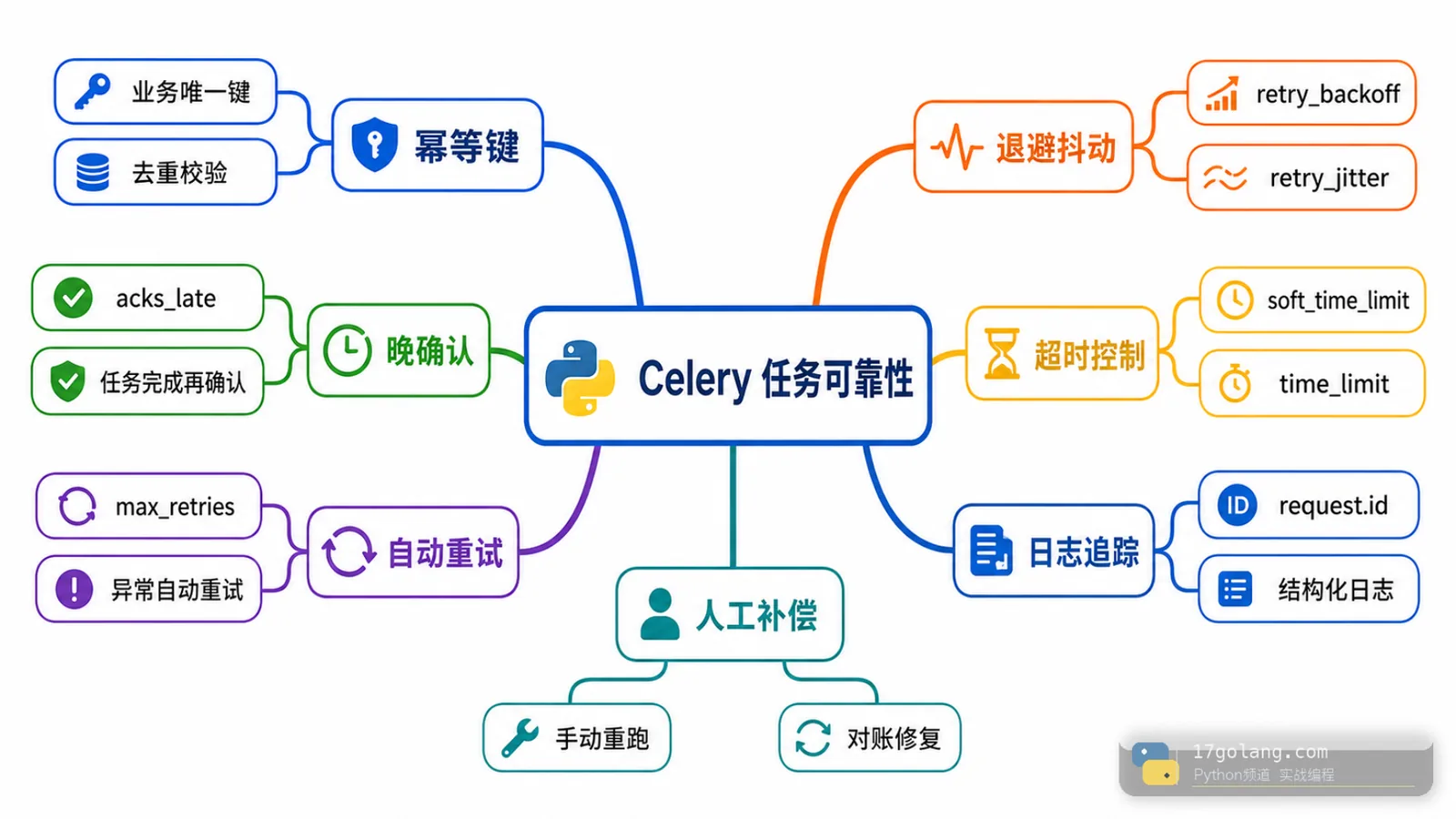 从 Python Celery 任务重复执行事故入手,实战讲解业务幂等键、acks_late、自动重试、指数退避、超时控制和上线观测。340 收藏
从 Python Celery 任务重复执行事故入手,实战讲解业务幂等键、acks_late、自动重试、指数退避、超时控制和上线观测。340 收藏 -
 Flask-Admin不能直接当CMS用,但可快速搭建CMS管理后台骨架;它仅提供模型驱动的CRUD界面,不包含前端展示、权限分级、内容路由和模板渲染等CMS核心功能。339 收藏
Flask-Admin不能直接当CMS用,但可快速搭建CMS管理后台骨架;它仅提供模型驱动的CRUD界面,不包含前端展示、权限分级、内容路由和模板渲染等CMS核心功能。339 收藏 -
 Python中实现异步上下文管理应使用@asynccontextmanager(Python3.7+)或手动实现__aenter__/__aexit__方法,禁用@contextmanager处理asyncwith;需确保协程调用、单次yield及异常传播正确。339 收藏
Python中实现异步上下文管理应使用@asynccontextmanager(Python3.7+)或手动实现__aenter__/__aexit__方法,禁用@contextmanager处理asyncwith;需确保协程调用、单次yield及异常传播正确。339 收藏 -
 Python网络程序高可用需从连接、重试、超时、熔断、监控五层面系统设计:连接管理用Session复用与分段超时;重试仅针对临时错误并指数退避;超时独立设置,配合熔断降级;监控覆盖指标、日志、链路与告警自愈。339 收藏
Python网络程序高可用需从连接、重试、超时、熔断、监控五层面系统设计:连接管理用Session复用与分段超时;重试仅针对临时错误并指数退避;超时独立设置,配合熔断降级;监控覆盖指标、日志、链路与告警自愈。339 收藏