-
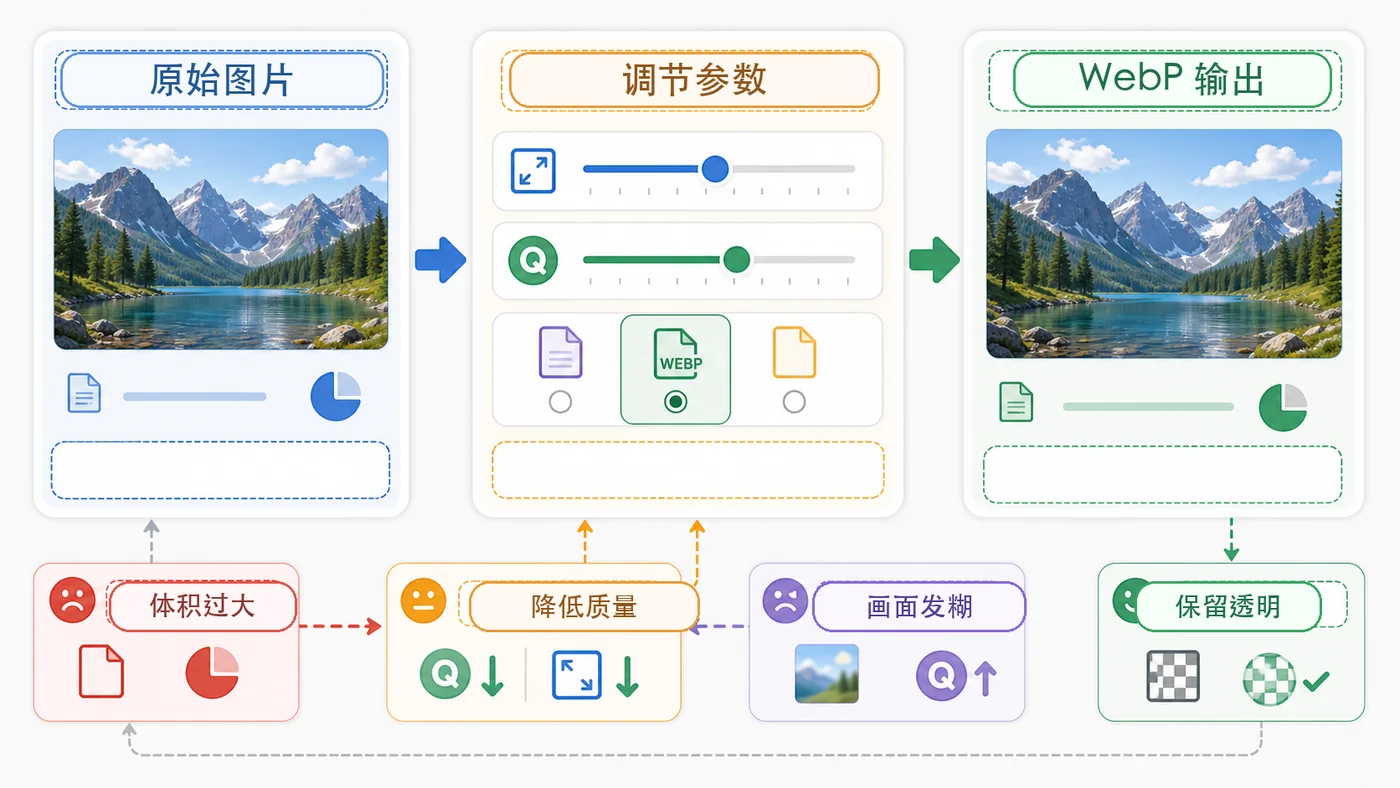
本文用 Python Pillow 实现图片批量压缩:从输入目录读取图片,按最大宽度等比缩放,输出 WebP,并生成压缩清单方便检查体积和清晰度。
-
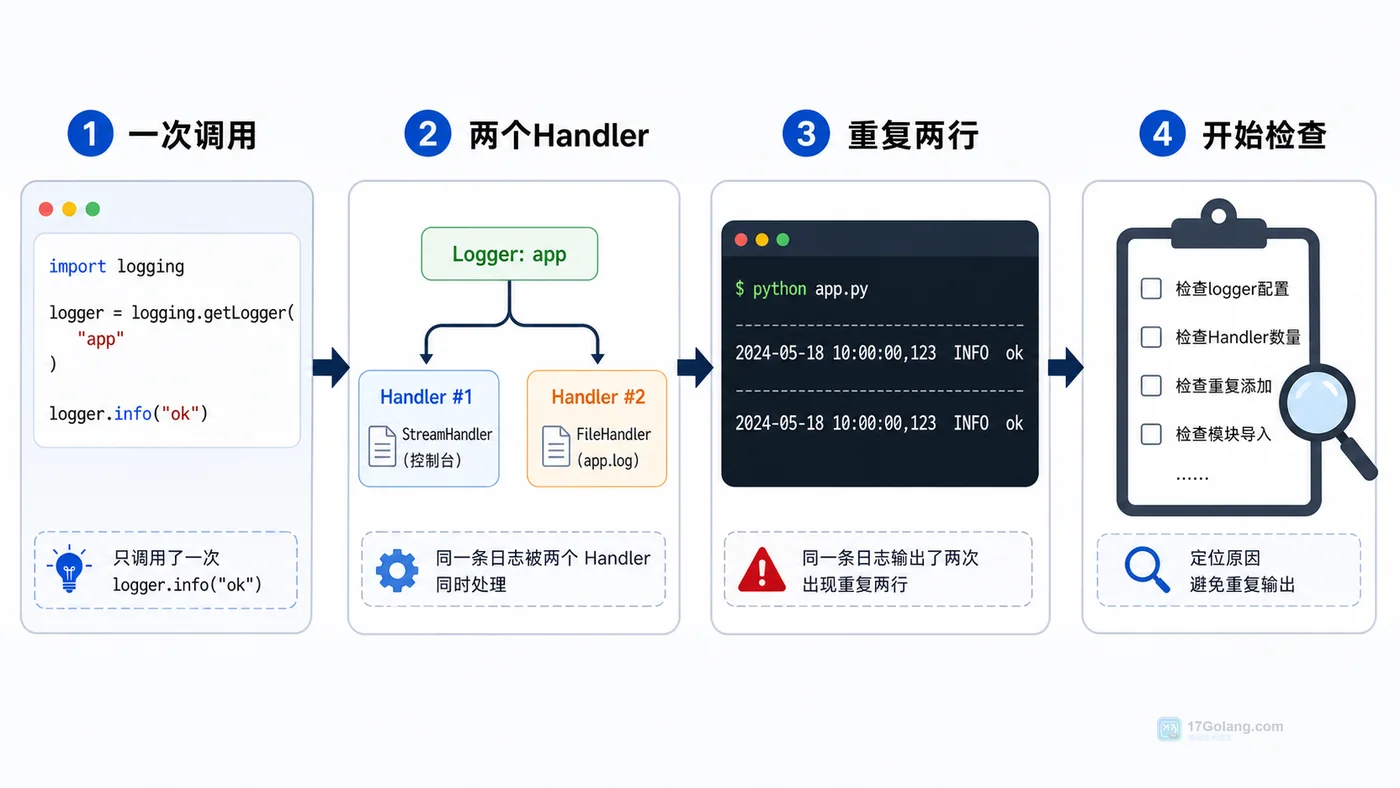
Python 项目里同一条日志重复出现两三次,常见原因是重复 addHandler 或子 logger 向根 logger 继续上抛。本文从复现现象开始,逐步检查 Handler 数量、logger 层级和 propagate 配置,整理一套稳定的日志初始化写法。
-

在Python中操作Parquet文件的核心工具是pyarrow。1.使用pyarrow.parquet模块的read_table和write_table函数实现Parquet文件的读写;2.利用pa.Table.from_pandas()和to_pandas()实现与Pandas的高效转换;3.处理大型文件时,可通过分块读取(iter_batches)控制内存使用;4.使用谓词下推(filters)和列裁剪(columns)提升查询效率;5.通过pyarrow.dataset模块统一管理分区数据集,并支
-

异常适用于真正出错、不该被忽略的意外情况,如文件缺失、网络不可达、严重参数错误;返回值适用于失败常见且需主动处理的场景,如字典取键、用户输入解析、查询无结果。
-

只有含yield表达式(如received=yieldvalue)的生成器才能用throw()触发except捕获;yield语句无法中断执行,throw()将直接终止生成器。
-

sklearn.TransformerMixin不能直接用,因仅继承它不强制实现fit/transform且不校验返回值形状,需同时继承BaseEstimator和TransformerMixin,并确保fit返回self、transform返回同形ndarray或DataFrame。
-

fileinput.input()更适合批量读取,因其自动管理文件打开/关闭、流式逐行处理避免内存溢出和句柄耗尽;返回可迭代对象而非列表,支持跨文件无缝读取,并可通过fileinput.filename()和isfirstline()获取来源文件信息。
-

文本清洗需分层过滤、可复用逻辑与内存友好设计。一、轻量预筛:去HTML、URL、非法字节及超长词;二、中文专治:统一标点、压缩空白、清除水印、慎去重字;三、批量平衡:分块处理、编译正则、内置方法提速;四、可验证回溯:统计变化、抽样核验、日志留痕。
-

安装cv2需执行pipinstallopencv-python,因cv2是模块名而opencv-python为包名;常见问题包括权限不足、numpy冲突、网络超时等,可通过虚拟环境、更新依赖、使用镜像源解决;根据需求选择opencv-python、headless或contrib版本;安装后通过importcv2并运行图像处理示例验证功能完整性。
-

本文介绍一种比暴力组合更高效的SubsetProduct求解思路——不从空集出发枚举乘积,而是从目标值N出发,通过反复除以候选因子反向构造可达路径,天然剪枝、无需预设组合长度、自动规避超限冗余。
-

groupby().head()返回空或结果错误,因它按原始行序取每组前N行而非按指标排序;需先sort_values再groupby().head(),或改用apply(nlargest)并注意NaN、索引、并列处理。
-

Python中可哈希对象需满足“相等对象哈希值相同”且哈希值生命周期内不可变;内置不可变类型(如int、str、tuple)默认可哈希,可变类型(如list、dict)默认不可哈希;自定义类需同时实现__hash__和__eq__方法,并确保参与哈希的属性逻辑不可变。
-

应使用pandas.read_csv的na_values和keep_default_na在读取阶段识别自定义缺失标识;设keep_default_na=False避免误判,配合dtype预声明列类型、fillna的limit/method控制填充边界、dask替代处理超大文件、SimpleImputer实现跨chunk一致填充,并通过业务逻辑校验区分真实缺失与有效标记。
-

requests请求超时必须显式设置,推荐用(timeout_connect,timeout_read)元组如(3,10),避免默认不设超时导致卡死;底层urllib3连接池和aiohttp异步超时需单独配置,全局设timeout风险大。
-

该进,但必须和代码解耦。架构图应作为衍生品由代码自动生成,只存生成逻辑(如generate_arch.py)和模板(如arch.dot.j2),不存PNG/SVG文件;通过AST静态分析提取依赖关系,用DOT渲染并上传至带版本标记的存储,以ARCH_VERSION.json为版本锚点。