-

本文详解如何正确遍历坐标列表,驱动Turtle依次前往每个坐标点;重点纠正对iter()的误用,推荐简洁可靠的for循环与切片方案,并提供可直接运行的示例代码。
-

应避免使用urlretrieve,改用urlopen+手动写文件,并设置timeout、User-Agent、Cookie等;下载后需校验文件完整性,优先用zipfile.is_zipfile()或MD5比对。
-

能实现,但关键在上下文传递完整:FastAPI需调用FastAPIInstrumentor.instrument_app()并预设带ServiceName的TracerProvider,HTTP跨服务调用必须用instrumented客户端(如httpx.AsyncClient+HTTPXClientInstrumentor),否则traceparent头无法自动注入。
-

外键字段用db.ForeignKey('表名.字段名')指向被引用表的主键字段,如db.ForeignKey('users.id');relationship推荐用back_populates双边定义;外键必须放在“多”的一侧模型中;SQLite需手动开启PRAGMAforeign_keys=ON,MySQL需使用InnoDB引擎。
-

df.dropna(how='all',axis=1)可删除全为空值(NaN/None)的列,但空字符串需先用replace转为NaN;thresh参数更灵活,如thresh=5保留非空值≥5行的列。
-

用Enum定义常量最安全可读,需显式赋值(推荐auto()),IntEnum支持整数比较但易混淆类型,StrEnum适合字符串场景;枚举不支持直接JSON序列化,需自定义default或用Pydantic。
-

PydanticBaseModel提供自动类型转换、多级校验与错误聚合:str用min_length=1拦截空白符,int自动转类型并报错,嵌套结构逐层校验;Query/Path/Body需分入口校验;业务规则用@field_validator或@model_validator统一处理,避免路由中手动try/except。
-
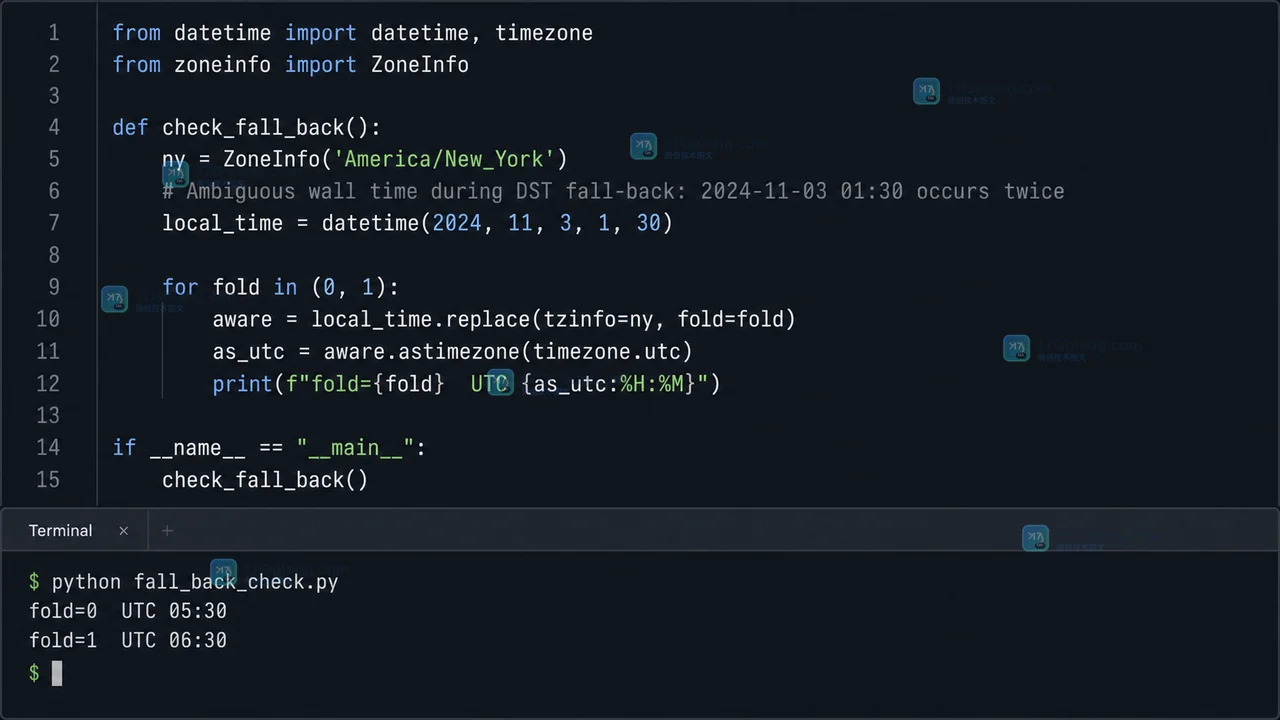
预约、提醒和活动排期里,用户输入的本地时间不能直接当 UTC 保存。本文用一个小型预约转换器说明 Python zoneinfo 的最小用法:保留时区键、把带时区时间转成 UTC,并在夏令时回拨造成的重复时间里明确记录 fold 选择。
-

sklearn1.2需调用sklearn.set_config(transform_output="pandas")在创建transformer前启用,仅对新建实例生效;支持类需实现_get_feature_names_out(如StandardScaler、OneHotEncoder),输入须为带列名的DataFrame,ColumnTransformer和Pipeline可自动拼接输出。
-

应分层捕获FileNotFoundError、PermissionError等具体异常,优先使用with语句管理文件,关键数据写入采用临时文件+原子重命名,编码错误需显式指定errors参数或用二进制模式。
-

@lru_cache缓存失效时机包括参数哈希不一致、LRU容量驱逐、手动clear、解释器重启或函数重定义;不可哈希参数报错,类型差异视为不同调用,外部状态变更不自动失效。
-

本文详解如何通过send_poll方法创建Telegram测验型投票,设置type='quiz'和correct_option_id参数,确保仅一个选项被识别为正确答案,且无需InlineKeyboard,完全符合官方Quiz交互规范。
-

本文详解WebSocket客户端在接收SIGINT(Ctrl+C)中断信号后无法正常发送关闭消息的问题,提供基于asyncio.CancelledError捕获、asyncwith自动资源管理及异常分层处理的完整解决方案。
-

Python3.9安装opencv-contrib-python报“Nomatchingdistribution”主因是旧版pip未识别cp39轮子,需升级pip≥21.3并换清华源;conda环境勿混用pip与conda安装,应选conda-forge渠道或彻底卸载后pip安装;contrib模块不可用常因版本禁用SIFT等算法,建议降级至4.4.0.46;WindowsDLL失败需装VC++运行时。
-

高可用是“挂了也能扛住”,需主动设计失败路径:对所有外部调用设timeout和有策略的retry;状态存储必须用Redis/PostgreSQL,禁用本地内存或文件;/health端点须检查关键依赖且超时≤1s。