-

Fernet不能直接加密大文件,因为它要求整个明文一次性加载进内存,导致2GB文件易触发MemoryError或系统卡顿;应改用AES-CTR或AES-GCM流式分块加密,并妥善管理nonce、tag与密文拼接。
-

fake-useragent仅随机生成User-Agent字符串,不校验有效性、不更新、不处理Sec-Ch-Ua等配套头字段,也无法解决行为特征识别问题。
-

先检查nvidia-smitopo-p2pr输出是否大量显示N/A或PHB而非PIX/SYS,若P2P未通则all_reduce降速3–5倍;确认硬件拓扑、BIOS设置,禁用CUDA_VISIBLE_DEVICES并显式绑定设备,backend必须设为"nccl",再通过nvidia-smidmon-su-d1观察PCIe带宽是否饱和。
-

asyncio.run()无法直接捕获create_task启动的任务异常,需在任务内处理或通过await、gather(return_exceptions=True)、task.exception()显式获取;retrying不支持异步。
-

本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如Overtake(v1))必然为真,从而实现确定性行为推理。本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如`Overtake(v1)`)必然为真,从而实现确定性行为推理。在自动驾驶或形式化安全推理场景中,仅满足约束是不够的——我们需要
-
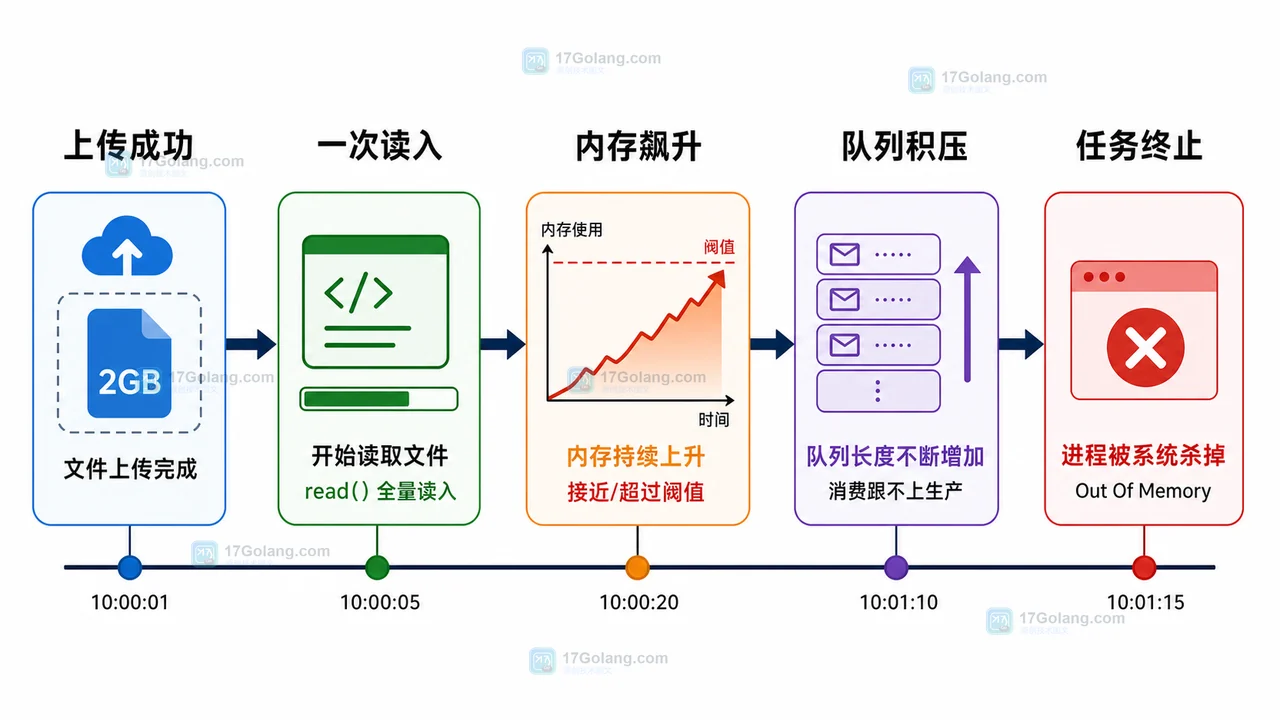
复盘一次 Python 大文件导入导致内存飙升的问题,按影响面、时间线、触发条件、根因、修复动作和防复发清单讲清 read() 一次读入与分块迭代的差异。
-

应使用正则提取数字结构再标准化分隔符:先用r'[-+]?\d{1,3}(?:[.,]\d{3})*(?:[.,]\d+)?'捕获有效数字,再依位置判断并替换小数点/逗号,最后转float。
-

浅拷贝copy.copy()在对象含可变嵌套对象(如list、dict)且被原地修改时出问题,导致新旧对象共享同一内存;深拷贝开销在于递归遍历、处理循环引用及不可序列化对象;自定义类需重写deepcopy控制资源字段;浅拷贝适用于仅含不可变字段或能确保不触发共享副作用的场景。
-

PyCharm支持Poetry环境但需手动配置:先终端执行poetryinit和install,再用poetryenvinfo-p获取路径,在Settings中选SystemInterpreter指向bin/python或Scripts\python.exe,禁用IDE自建虚拟环境,并每次依赖变更后重载项目。
-

弱引用不能自动避免内存泄漏,其生效前提是目标对象除弱引用外无其他强引用;典型用途包括WeakValueDictionary缓存、观察者模式解耦等,但需注意key生命周期、线程安全及finalize的不确定性。
-

Adam与SGD解决不同问题:Adam开箱即用但泛化弱,SGD需搭配warmup和重置的余弦退火才能稳定收敛;推荐AdamW优先,或分阶段先Adam后SGD微调。
-

base.html必须定义block才能让子模板覆盖内容,否则未设block的区域彻底锁死;至少需{%blocktitle%}{%endblock%}和{%blockcontent%}{%endblock%},且{%extends%}必须首行、路径准确、区分大小写。
-

mypy通过静态语法和类型规则推断类型:局部变量依初始化值定型,函数类型依赖标注或上下文,容器类型随操作动态细化,泛型和上下文触发双向推断。
-

pandasdatetime64[ns]内存更省,每元素仅8字节;arrow.Arrow实例约64+字节,100万条可多占40MB以上,且无共享结构、GC压力大。
-

推荐系统核心是精准匹配用户技术语境与需求,通过实时解析编辑器/CLI上下文提取语言、依赖、错误等特征,结合三层结构知识库与规则+向量混合匹配,辅以闭环反馈持续优化。