-

生产环境推荐pybloom_live:开箱即用,依赖bitarray;需合理设置capacity(预期最大元素数)和error_rate(默认0.01);注意类型一致、不可删除、pickle跨环境易失败、非进程安全。
-

直接用datetime或date对象相减得timedelta,.days属性即日历天数差;字符串或时间戳无法直接相减,需先解析为日期对象,且要注意时区、顺序和类型选择。
-

Python条件表达式写法为“值1if条件else值2”,用于一行内简单条件选择,不可省略else,不能执行语句,仅返回值,嵌套不宜超过一层。
-

TaskGroup是Python3.11引入的结构化并发机制,解决asyncio.gather()在错误传播、资源清理和取消语义上的根本缺陷,实现“一挂全收”,异常聚合后重抛,子任务生命周期统一管理。
-

random.sample不能重复抽样因其设计为无放回抽样,内部打乱索引后取前k个;重复值源于原列表本身含重复元素,非函数问题。
-

答案:Python中使用math模块进行三角函数计算,需先将角度转换为弧度。1.math.sin、cos、tan等函数接收弧度参数,可用math.radians和math.degrees转换单位;2.计算30度正弦值需先转弧度,结果为0.5000;3.π/4弧度等于45.0度;4.解直角三角形时,对边=斜边×sin(角),45度、斜边10得对边7.0711;5.注意输入为数字,反三角函数输入范围[-1,1],避免浮点误差。
-

用collections.deque实现层序遍历,避免list.pop(0);入队前判空,用popleft()和append();按层分组需快照len(queue);递归模拟非真BFS。
-

Python 的 input 总会返回字符串,直接交给 int 转换时,空值、字母和终端输入结束都会让交互变得难用。文章从用户实际输入出发,给出循环校验、范围限制、退出命令和 EOFError 边界的最小实现,并附上核对清单。
-

Python异步异常处理的核心在于:异常在await表达式处被重新抛出,且传播路径与同步代码逻辑一致,但需注意协程栈与事件循环的交互细节。await是异常传播的关键节点当一个协程中发生异常(如raiseValueError("oops")),该异常不会立即向上冒泡,而是被封装进返回的Awaitable对象(如Task或coroutine)。只有在调用方await该对象时,异常才真正抛出到当前协程上下文中。未被await的协程(比如只调用some_coro()而
-

扁平化嵌套列表的核心是根据嵌套深度和数据规模选择合适方法:递归适用于任意深度但受限于调用栈;生成器结合yieldfrom兼顾性能与内存;itertools.chain.from_iterable适合浅层嵌套且效率高;sum()方法简洁但性能差;列表推导式限于固定两层。处理混合类型时需用isinstance(item,list)排除字符串等可迭代对象,避免误拆。通用推荐为生成器方案,既高效又支持深层嵌套。
-

PySAL与geopandas组合是地理感知聚类的务实选择,能尊重地球曲率、构建空间权重、识别空间自相关;sklearn直接对经纬度聚类会因纬度差异导致距离失真,结果不可解释。
-
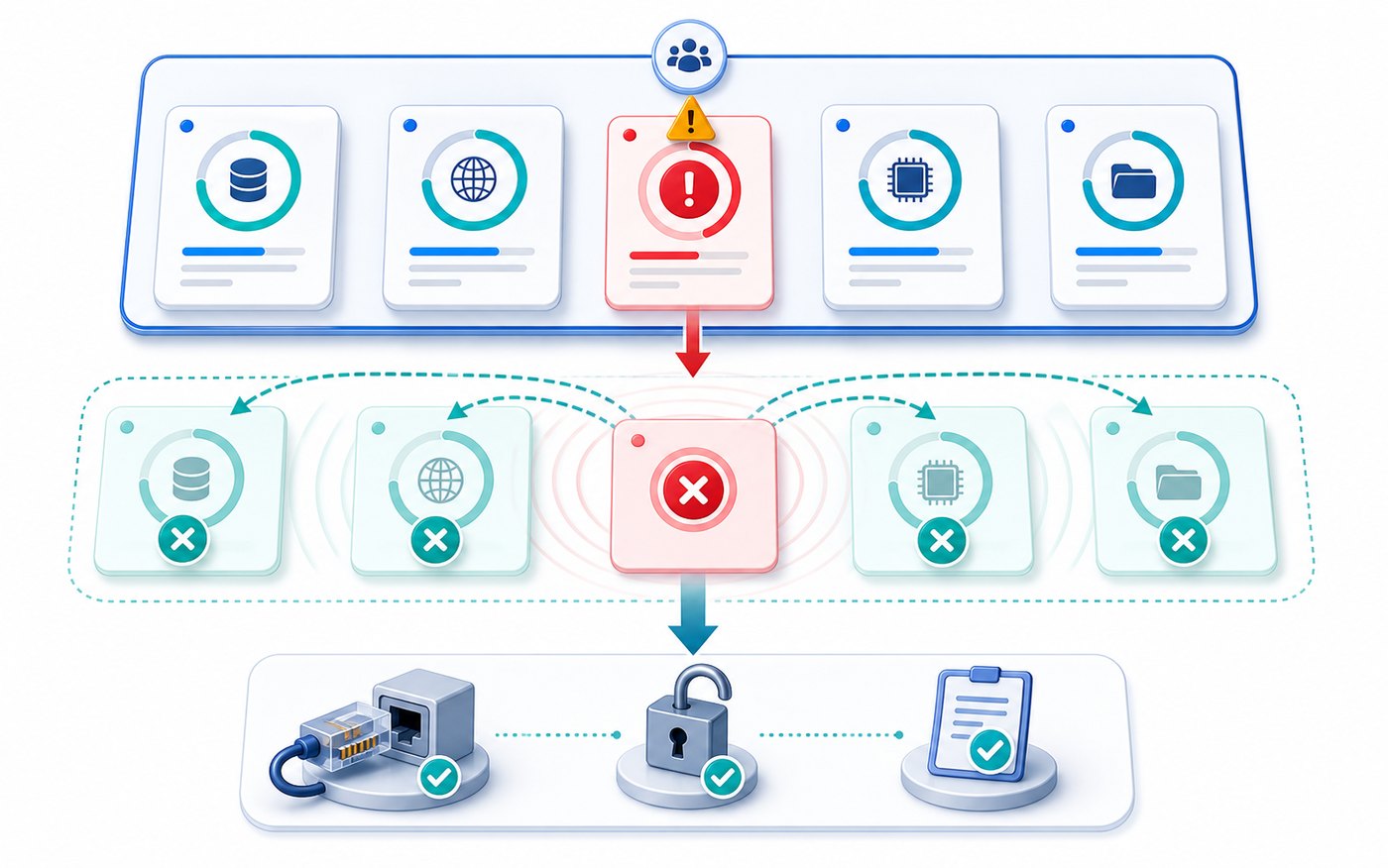
通过一个异步接口聚合案例,演示 asyncio.timeout、wait_for、TaskGroup、shield 和取消传播的用法,帮助 Python 项目把慢任务、半完成状态和资源清理管住。
-

本文介绍通过并发请求、请求节流与批量优化策略,将数十万地址的地理编码耗时从分钟级降至秒级,兼顾GoogleMapsAPI配额限制与稳定性。
-

Flask-SocketIO频繁掉线的本质是客户端、服务端及代理层的ping_interval与ping_timeout配置未对齐,导致心跳超时断连;需三方同步设置且单位一致(服务端秒、客户端毫秒),并确保Nginx等代理透传Upgrade头且proxy_read_timeout≥ping_interval+ping_timeout。
-

能,但需并发控制、连接复用和错误隔离:paramiko默认不复用连接,易触发socket和MaxStartups限制;exec_command()易截断输出;单点故障会导致全局阻塞;应使用invoke_shell()模拟终端、设超时、限流线程池、妥善处理密钥权限与认证。