-

^运算符计算对称差集时要求操作数必须均为set,否则报TypeError;symmetric_difference()方法更灵活,可接受任意可迭代对象。
-

PoissonRegressor自sklearn1.3起为稳定接口,专用于非负整数计数数据建模;它通过内置对数链接与泊松似然确保预测≥0、适配方差随均值增长的特性,优于会产生负预测和违反同方差假设的LinearRegression。
-

Python函数docstring自动校验需统一格式、覆盖参数Args、返回值Returns、异常Raises三要素,并与类型标注双向对齐;推荐pydocstyle+darglint双工具协同校验,集成至pre-commit和CI强制执行。
-

最直接且推荐的方法是在激活虚拟环境后使用python--version或python-V命令来确认当前Python版本,这能确保你检查的是该虚拟环境内部的Python解释器而非系统全局版本,避免版本冲突和依赖问题,从而保障开发环境的隔离性、依赖兼容性与项目可复现性,该操作应始终在环境激活状态下进行,且可通过whichpython(macOS/Linux)或wherepython(Windows)、sys.executable和sys.version等方法进一步验证解释器路径和详细版本信息,确保开发环境准确
-

答案:==比较值是否相等,is比较对象内存地址是否相同。例如列表内容相同则==为True,但is为False除非指向同一对象;小整数因缓存可能is也为True,但大整数不一定;推荐用is判断是否为None。
-
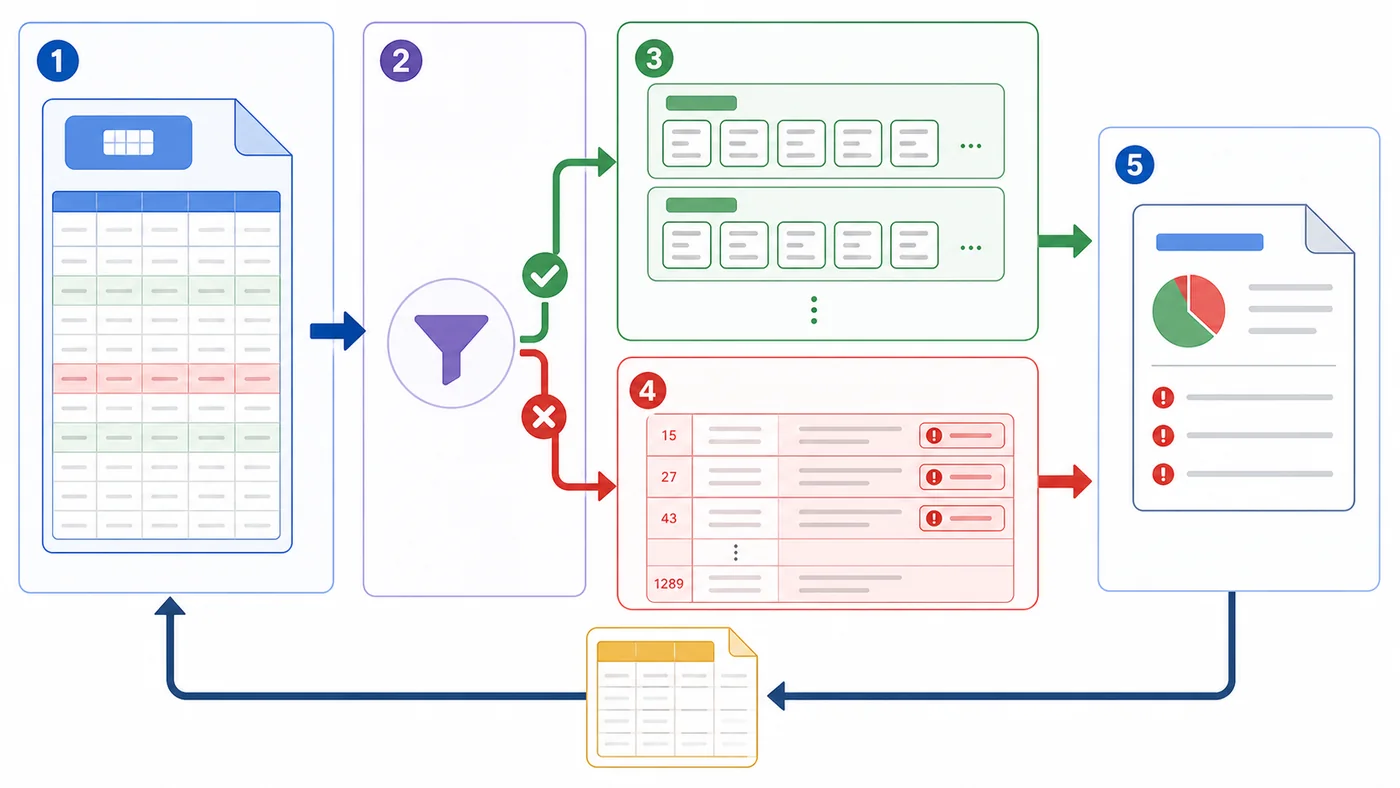
本文用用户 CSV 导入场景,演示如何边读边校验、按批次写入、收集错误行并生成失败明细,避免一次性读入和半成功数据污染。
-

configparser报NoSectionError因.ini要求至少一个[section]头;解决需加显式section、用RawConfigParser预处理或改用JSON/YAML;环境变量优先级高于配置文件;多源配置推荐pydantic-settings安全合并。
-

在PyQt6中通过QSlider控制QMediaPlayer音量时,需注意QAudioOutput.setVolume()接收的是0.0–1.0的浮点数(非0–100整数),直接传入滑块值会导致静音;本文详解线性映射与符合人耳感知的对数音量转换方案。
-

Python中用_csv模块读取CSV文件,本质是调用C语言实现的底层解析器,性能高、内存占用低,适合处理大文件或对效率有要求的场景。但注意:_csv是内部模块,不推荐直接导入使用;标准做法是导入csv模块——它正是对_csv的封装,接口稳定且功能完整。用csv.reader读取普通CSV文件适用于结构清晰、无复杂引号或换行符的CSV数据。先用open()以文本模式打开文件(Python3默认utf-8,如有乱码需显式指定encoding)传入文件对象给csv.reader(),返回一个可迭代对象逐行遍
-

np.argmax(axis=1)返回每行最大值的列索引;结果为int64一维数组,长度等于行数;遇并列取最左位置,含NaN时需改用np.nanargmax。
-

不能只看平均CV分数,因其掩盖各折波动;箱线图可揭示中位数偏态、IQR稳定性及离群折;需用StratifiedKFold与cross_val_score获取每折原始分,再用matplotlib.boxplot绘图并处理nan。
-

分布式系统中应为每条日志自动添加请求ID以实现链路追踪:通过中间件在请求入口生成唯一trace_id并绑定至contextvars,日志Filter动态注入,Formatter引用;异步/多线程需显式传递;推荐集成OpenTelemetry自动获取并格式化trace_id。
-

答案是Python的re模块通过结合正则表达式和映射字典实现数字与英文单词的相互转换,具体使用re.sub()配合回调函数完成替换操作。
-

itertools.batched()更安全,因其不预加载全部数据、内存占用恒定;手写切片易致全量展开,引发OOM或阻塞。
-

手机号掩码不能仅用re.sub(r'(\d{3})\d{4}(\d{4})',r'\1****\2',phone),因未清理非数字字符、未校验长度、未锚定边界,易漏掩或误掩;应先提纯数字并验11位,再精准替换。