-

cosignverify报“nomatchingsignatures”通常因未用镜像digest验证或registry路径不一致;需用registry/repo@sha256:xxx格式,检查digest有效性、公钥格式、TLS配置及签名存储模式。
-

当Flask主程序(app.py)能正常导入flask_sqlalchemy,而通过subprocess启动的tracking.py却报ModuleNotFoundError时,根本原因是子进程未激活虚拟环境,导致Python解释器无法定位已安装的包。
-

np.array_split比np.split更适合分块大数组,因其能自动处理余数、不报错;它按axis=0默认行拆,需显式指定axis=1才列拆;返回子数组长度最多相差1,非严格均等。
-

面向失败的设计需预判故障点并确保系统可恢复,而非仅用try/except掩盖错误;每个except必须记录日志、告警或降级,区分I/O异常类型,HTTP失败时优先缓存或切备用接口,非法输入应抛具体异常而非返回None,测试须覆盖失败路径。
-

正确姿势是使用@pytest.mark.skip(reason="说明")跳过测试,必须带reason参数;跳过类加在class上;条件跳过用skipif;xfail用于预期失败且不影响setup/teardown。
-

KNeighborsClassifier预测不稳定主因是距离相等时按索引排序导致结果敏感;应固定train_test_split的random_state、优先用euclidean距离、避免StandardScaler后用manhattan,稀疏数据需brute+manhattan组合。
-

启用calamine引擎需满足pandas>=2.2.0且安装calamine-python;通过storage_options={"engine":"calamine"}隐式触发,不支持engine参数直传,仅加速读取、不支持写入与样式。
-
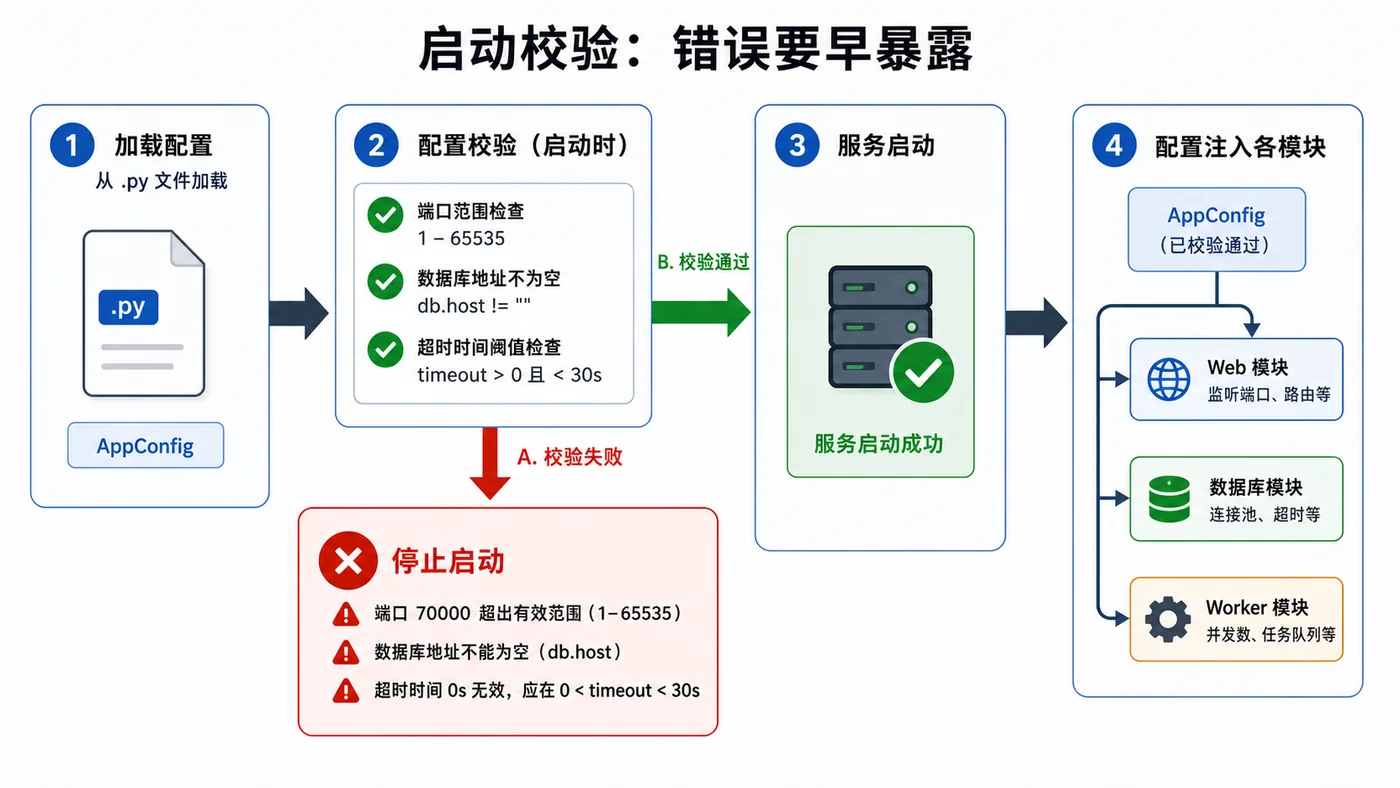
本文用标准库 dataclass 写一套轻量配置加载方案,演示默认值、环境变量覆盖、类型转换和启动校验,避免服务上线后才发现端口、数据库地址或超时参数写错。
-

人脸检测可通过Python的dlib库实现,需注意环境配置和模型选择。1.安装前需确认Python版本为3.6~3.9,并安装numpy、cmake,Windows用户还需VisualC++BuildTools。2.推荐使用pip安装dlib,若失败可下载预编译wheel文件安装。3.dlib提供HOG和CNN两种模型,HOG速度快精度低,CNN更准但需GPU支持,且需单独下载模型文件。4.检测流程包括读取图像、转灰度图(可选)、加载模型、检测并绘制人脸框。5.常见问题包括模型路径错误、图像格式不正确、C
-

应使用Pythonssl模块而非openssl命令获取证书信息,通过ssl.create_default_context()建立TLS连接,调用sock.getpeercert()获取字典格式证书,用ssl.cert_time_to_seconds()解析notAfter字段为Unix时间戳,结合超时控制、异常处理、安全邮件发送及生产级调度机制实现稳定监控。
-

lru_cache基于参数的hash()结果生成缓存键,而非对象身份或简单值比较;内置不可变类型按值哈希,自定义类默认按ID哈希,可变类型直接报错。
-

使用ReportLab或FPDF可将Python字符串生成PDF。1.ReportLab功能强大,支持复杂布局,安装后通过canvas模块设置坐标写入文本;2.FPDF更轻量,API简单,适合纯文本,需设置字体和页面后写入内容;3.处理中文需加载中文字体文件如simsun.ttc并正确配置。根据需求选择:简单文本用FPDF,复杂格式用ReportLab。
-

Flask需手动解析Range头并返回206响应:提取bytes范围,校验有效性,设置Content-Range;send_file在conditional=True且传入文件对象时可自动支持;大文件应使用流式Response生成器分块读取;反向代理常导致Range失效,需直连排查。
-

应使用布尔索引而非for循环进行NumPy条件过滤,因其利用向量化操作和底层C优化,避免Python解释器开销、保持内存连续性并返回ndarray;多条件需用&、|、~并加括号,二维需维度匹配。
-

Python中判断类型应优先用isinstance()而非type(),因前者支持继承和抽象基类、更符合鸭子类型;内置基本类型仅包括int、float、complex、bool、str、bytes、NoneType。