python教程技术文章
-
 axis=0插入行,axis=1插入列;axis指被操作的维度,与插入位置无关,只决定新增数据方向。429 收藏
axis=0插入行,axis=1插入列;axis指被操作的维度,与插入位置无关,只决定新增数据方向。429 收藏 -
 Flask-Mail初始化失败主因是未在应用上下文中调用send(),需确保绑定app且发信时处于app_context;SMTP配置需匹配端口与加密方式;异步发信应使用flask-executor或Celery并手动管理上下文。429 收藏
Flask-Mail初始化失败主因是未在应用上下文中调用send(),需确保绑定app且发信时处于app_context;SMTP配置需匹配端口与加密方式;异步发信应使用flask-executor或Celery并手动管理上下文。429 收藏 -
 pack_forget()并未销毁组件,仅临时移除布局;组件对象、事件绑定和属性均保持有效,与destroy()的不可逆性有本质区别。429 收藏
pack_forget()并未销毁组件,仅临时移除布局;组件对象、事件绑定和属性均保持有效,与destroy()的不可逆性有本质区别。429 收藏 -
 vars()本质是obj.__dict__的安全封装,仅对拥有__dict__的对象有效;无__dict__时(如__slots__类、内置类型)会抛TypeError,此时应改用hasattr检查或dir()+getattr组合获取属性。429 收藏
vars()本质是obj.__dict__的安全封装,仅对拥有__dict__的对象有效;无__dict__时(如__slots__类、内置类型)会抛TypeError,此时应改用hasattr检查或dir()+getattr组合获取属性。429 收藏 -
 Python迭代器协议核心是__iter__和__next__两个方法:前者返回迭代器对象(可为self或新实例),后者返回下一项或抛StopIteration;遵守该协议即支持for循环等操作,无需继承或装饰。429 收藏
Python迭代器协议核心是__iter__和__next__两个方法:前者返回迭代器对象(可为self或新实例),后者返回下一项或抛StopIteration;遵守该协议即支持for循环等操作,无需继承或装饰。429 收藏 -
 dataclass能省略__init__和__repr__是因为@dataclass在类构造期自动生成这些方法,而非继承或运行时patch;若手动定义了__init__,则装饰器跳过生成。429 收藏
dataclass能省略__init__和__repr__是因为@dataclass在类构造期自动生成这些方法,而非继承或运行时patch;若手动定义了__init__,则装饰器跳过生成。429 收藏 -
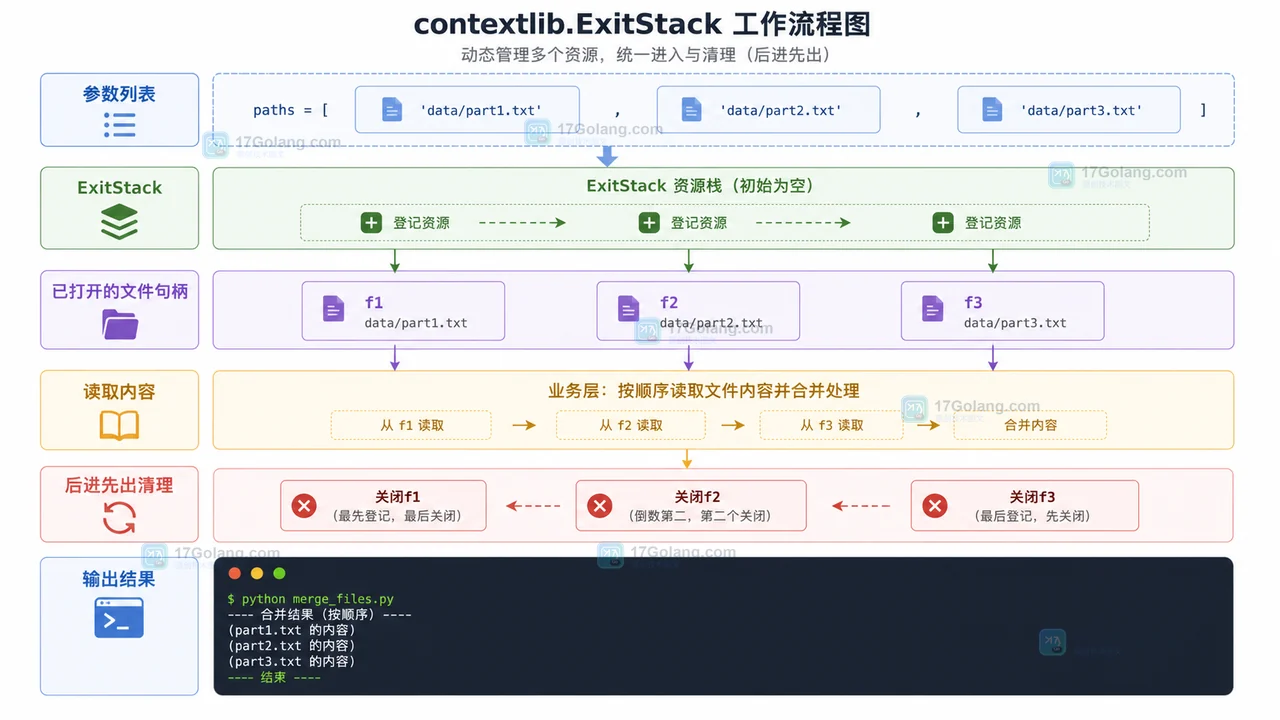 用 Python 标准库 contextlib 写一套资源清理小配方,从自定义上下文管理器、suppress 到 ExitStack,解决文件、临时目录和多资源关闭顺序问题。429 收藏
用 Python 标准库 contextlib 写一套资源清理小配方,从自定义上下文管理器、suppress 到 ExitStack,解决文件、临时目录和多资源关闭顺序问题。429 收藏 -
 itertools.chain(*nested)是展开双层嵌套列表最省事的方法,不建中间列表、不递归、纯流式拼接,但需解包且要求子项为非字符串可迭代对象。428 收藏
itertools.chain(*nested)是展开双层嵌套列表最省事的方法,不建中间列表、不递归、纯流式拼接,但需解包且要求子项为非字符串可迭代对象。428 收藏 -
 Canny边缘检测是OpenCV中目标边缘检测的核心方法,包含高斯滤波、梯度计算、非极大值抑制和双阈值滞后阈值化四步;需先灰度化、高斯去噪,合理设置双阈值,并辅以膨胀、轮廓提取等后处理提升实用性。428 收藏
Canny边缘检测是OpenCV中目标边缘检测的核心方法,包含高斯滤波、梯度计算、非极大值抑制和双阈值滞后阈值化四步;需先灰度化、高斯去噪,合理设置双阈值,并辅以膨胀、轮廓提取等后处理提升实用性。428 收藏 -
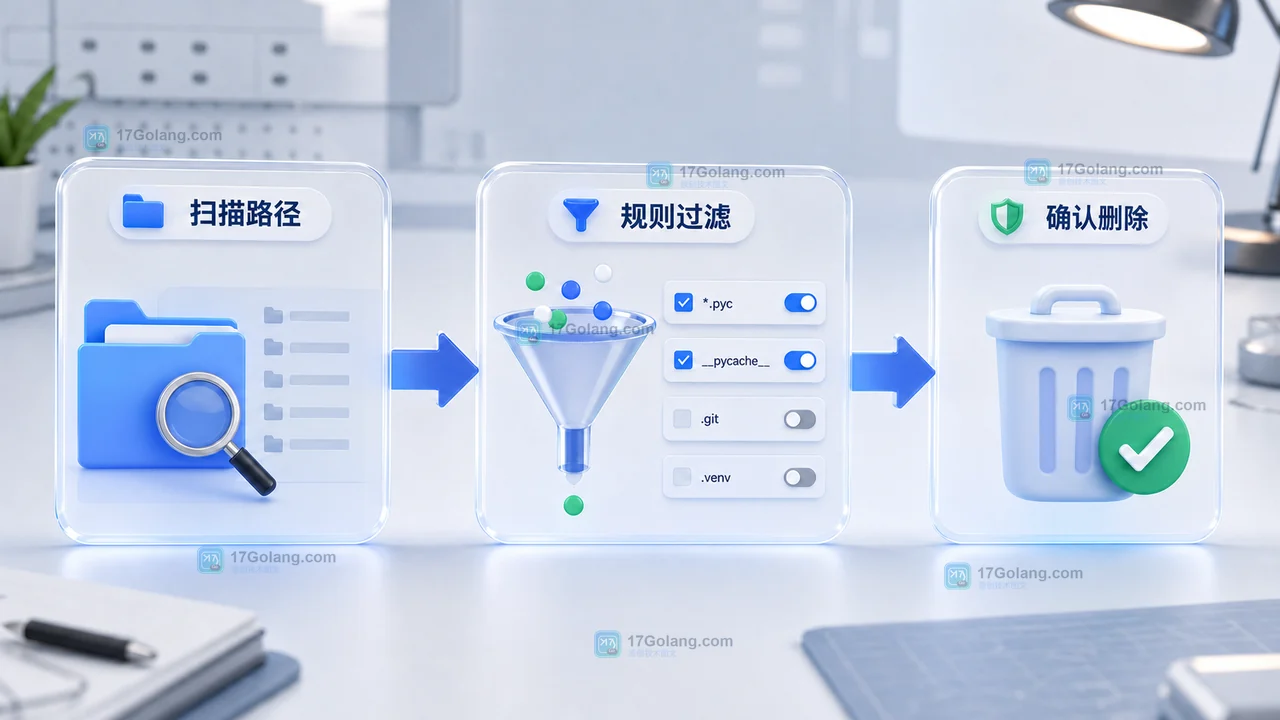 用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。428 收藏
用 Python 做临时文件夹清理,重点不在递归删除本身,而在边界、阈值、白名单和试运行。本文从一个小工具项目出发,带你完成扫描、过滤、预览、删除确认和运行验收,适合处理 __pycache__、旧日志、构建缓存等可清理文件。428 收藏 -
 本文介绍使用Python自动化提取含指定PL编号的完整数据块(从Name行到下一个Name行前),并按PL值分别保存为独立文件,适用于数千条记录的批量处理场景。427 收藏
本文介绍使用Python自动化提取含指定PL编号的完整数据块(从Name行到下一个Name行前),并按PL值分别保存为独立文件,适用于数千条记录的批量处理场景。427 收藏 -
 nlargest比排序更快是因为它仅维护大小为k的最小堆,时间复杂度O(nlogk),避免全量排序O(nlogn);当k接近n时优势消失,且返回结果不保证内部有序。427 收藏
nlargest比排序更快是因为它仅维护大小为k的最小堆,时间复杂度O(nlogk),避免全量排序O(nlogn);当k接近n时优势消失,且返回结果不保证内部有序。427 收藏 -
 必须使用requests.Session()复用连接池以避免重复TCP/TLS握手,配合aiohttp.AsyncResolver和超时拆分(connect/read)可显著降低高频请求延迟。427 收藏
必须使用requests.Session()复用连接池以避免重复TCP/TLS握手,配合aiohttp.AsyncResolver和超时拆分(connect/read)可显著降低高频请求延迟。427 收藏 -
 使用Git进行版本控制,通过初始化仓库、添加文件、提交更改和推送远程仓库实现协作;创建功能分支开发避免主干污染;规范提交信息并结合PullRequest进行代码审查;配置.gitignore忽略缓存与敏感文件;使用虚拟环境隔离依赖并导出requirements.txt确保环境一致。427 收藏
使用Git进行版本控制,通过初始化仓库、添加文件、提交更改和推送远程仓库实现协作;创建功能分支开发避免主干污染;规范提交信息并结合PullRequest进行代码审查;配置.gitignore忽略缓存与敏感文件;使用虚拟环境隔离依赖并导出requirements.txt确保环境一致。427 收藏 -
文章 · python教程 | 1个月前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志
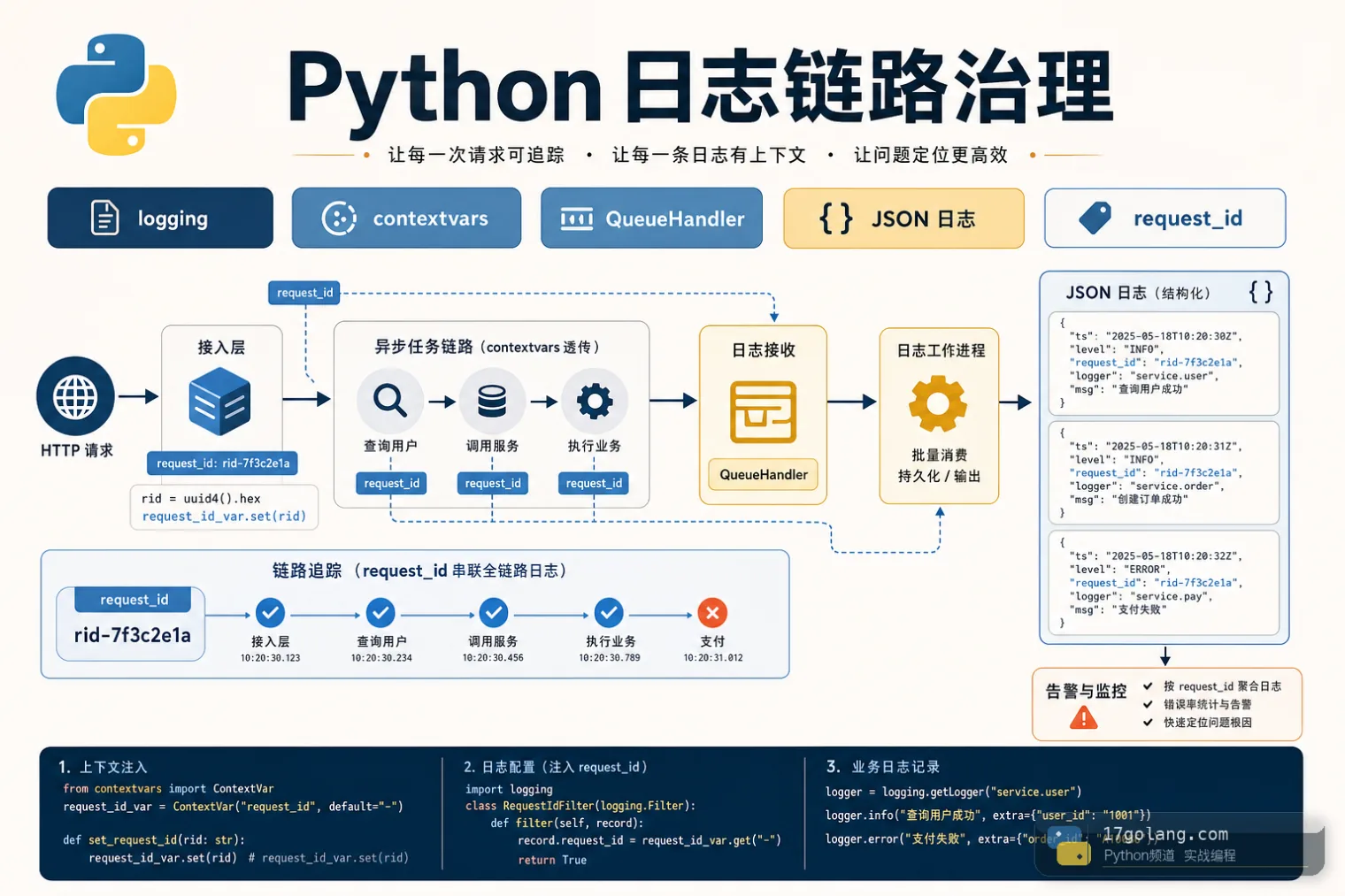 从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。427 收藏
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。427 收藏