-

CountVectorizer默认不支持词干提取,因其设计追求轻量、可复现、无语言依赖;需通过自定义tokenizer参数注入NLTKPorterStemmer实现词干化,同时注意停用词匹配与中英文适配问题。
-

答案:通过input获取用户输入的数字字符串,用split()分割并转换为浮点数列表,再用for循环累加求和,可加入try-except处理非数字输入,确保程序健壮性。
-

Referer防盗链需设为真实上级页面URL(如"https://example.com/article/123"),并配合匹配的User-Agent、必要Cookie及Accept等头字段,否则易返回403。
-

np.char.strip仅支持ndarray输入,不接受list/tuple;需先转为dtype=U的字符串数组,并显式处理全角空格等Unicode空白符。
-

aggregate()默认聚合全表数据,无需filter();支持多字段一次计算,返回单字典结果;空值返回None需手动处理;分组聚合须用values()+annotate()。
-

正则表达式中的|符号表示“或”,用于匹配左右任意一个表达式;1.基本用法是匹配多个字符串,如apple|orange可匹配“apple”或“orange”;2.配合括号分组可限制“或”的范围,如(cat|dog)food表示匹配“catfood”或“dogfood”;3.实际应用中需避免歧义、注意性能问题,并根据平台决定是否转义。
-

SMOTE并非万能开关,常因特征未标准化、k_neighbors过大或全局调用导致precision下降、F1降低;正确做法是在imblearn.Pipeline中前置StandardScaler、设k_neighbors=3,并在交叉验证内局部重采样。
-
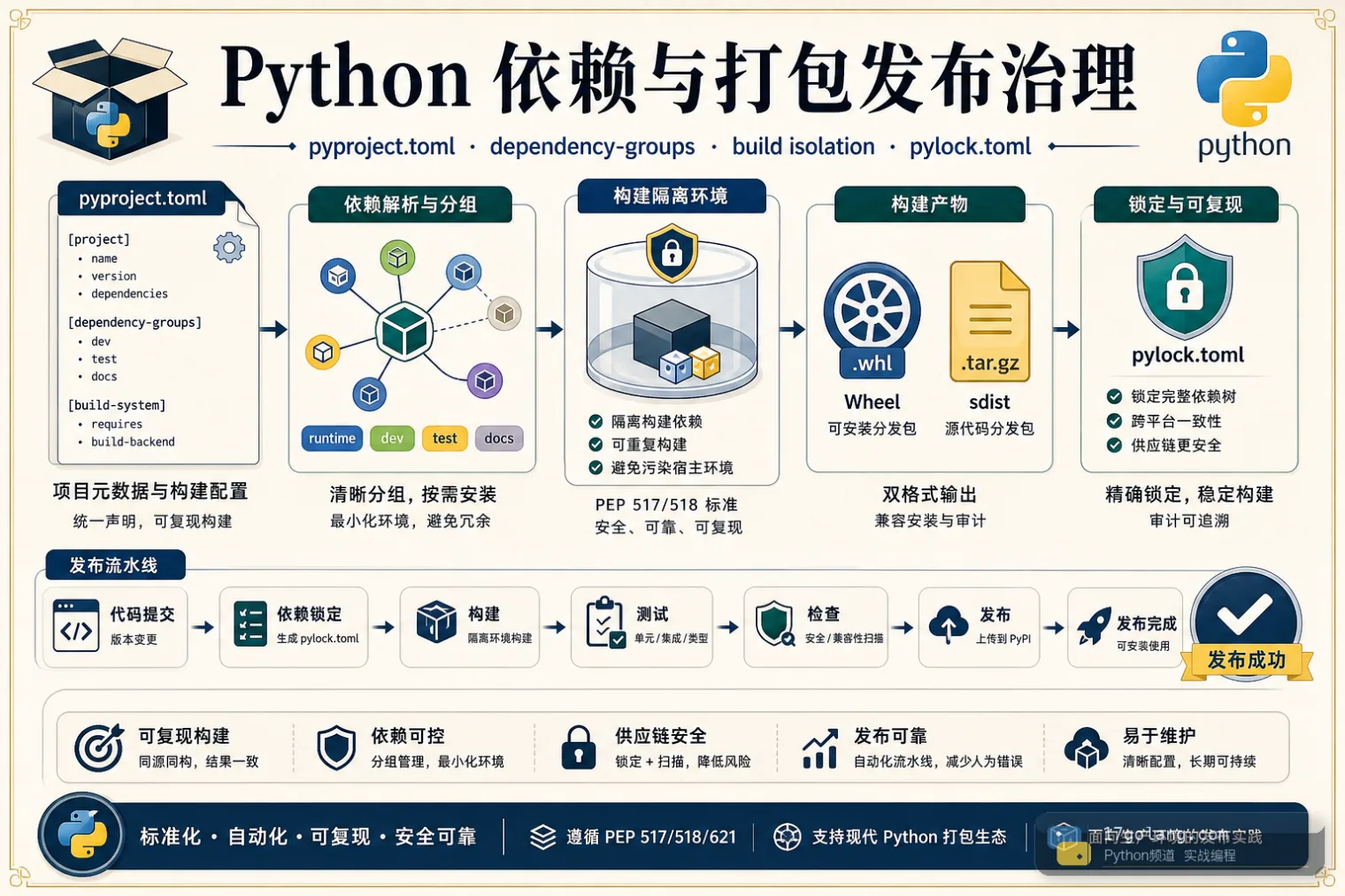
从 Python 内部包发布事故入手,讲清 pyproject.toml、dependency-groups、构建隔离、wheel/sdist 检查、锁文件和私有源 token 治理。
-

普通dataclass的hash为False,因为Python默认生成的__hash__为None;即使设hash=True,含可变字段(如list)时也会被静默忽略,因哈希值需在对象生命周期内恒定。
-

最直接有效的解法是让「刚写完就查」的SELECT显式路由至主库,在请求粒度精准控制数据源为master_db,避免依赖延时、锁或全局开关,并辅以1.5秒本地缓存兜底。
-

必须先创建.venv是因为全局pipinstall会导致所有项目共享site-packages,引发版本冲突;而python-mvenv.venv可生成完全隔离的Python环境,确保依赖互不干扰。
-

典型现象是Flask应用长时间空闲后首次请求报OperationalError(2013,'Lostconnection...'),本质为MySQL服务端主动断连而SQLAlchemy连接池未感知;须同时配置pool_pre_ping=True(每次取连接前探活)和pool_recycle=3600(设为比wait_timeout小至少10秒)才可靠。
-

Scrapy是Python中高效抓取网页数据的流行框架,适合各类爬虫项目。首先在虚拟环境中创建并激活环境,使用python-mvenvscrapy_env命令创建,再根据系统运行相应激活命令。接着执行pipinstallscrapy安装框架,并通过scrapyversion验证安装成功。然后使用scrapystartprojectmyspider创建项目,生成标准目录结构,包含spiders、items.py和settings.py等核心文件。进入spiders目录后,运行scrapygenspidere
-

WSGI是一个约定application(environ,start_response)函数签名的协议,要求响应体为bytes可迭代对象、响应头为二元组列表,且必须先调用start_response再返回响应体。
-
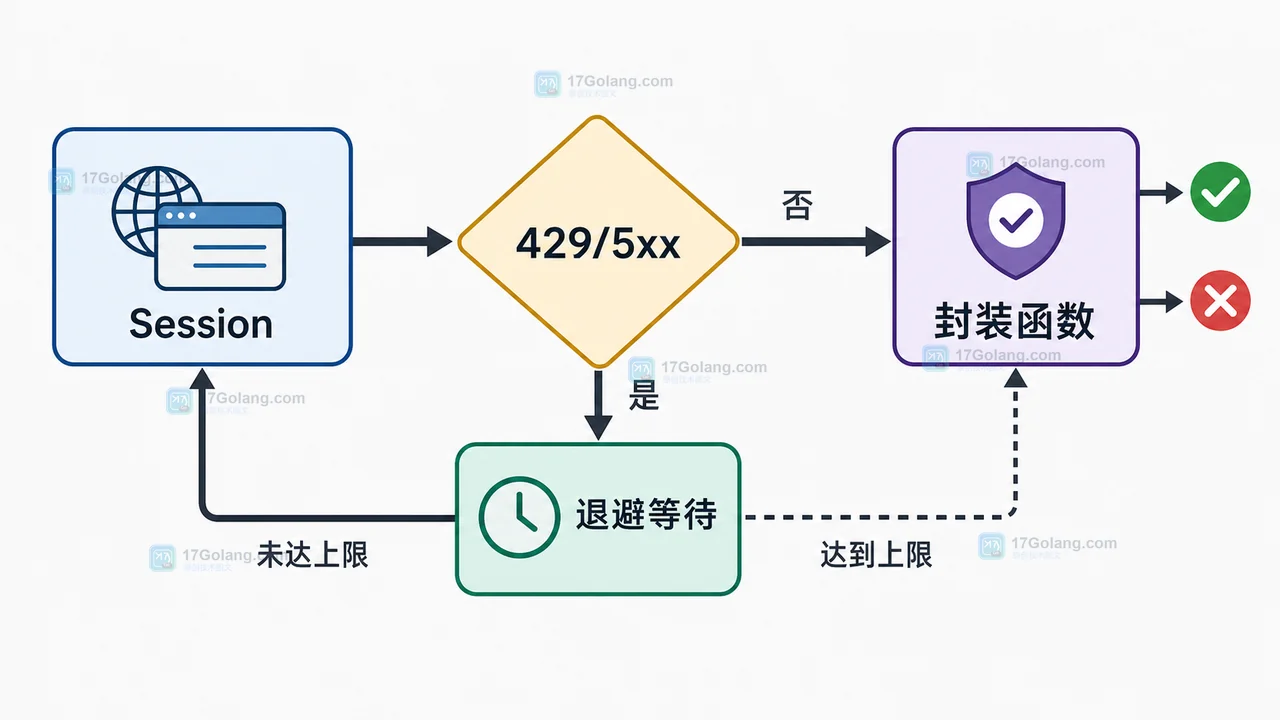
用一个最小 requests 配方解决 HTTP 请求卡住、慢接口无响应和偶发 5xx 问题:分开设置连接/读取超时,用 Session 统一重试,再封装业务请求函数。