python教程技术文章
-
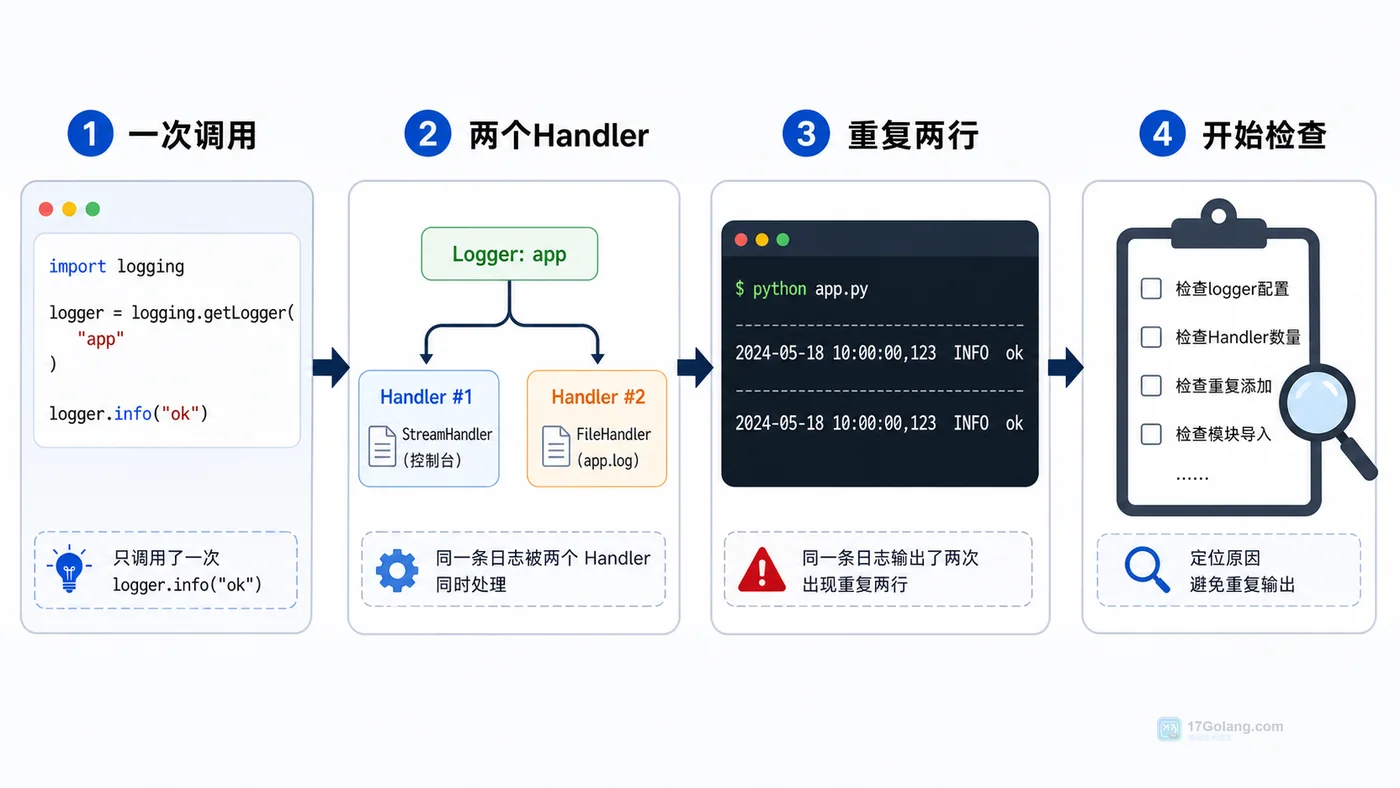 Python 项目里同一条日志重复出现两三次,常见原因是重复 addHandler 或子 logger 向根 logger 继续上抛。本文从复现现象开始,逐步检查 Handler 数量、logger 层级和 propagate 配置,整理一套稳定的日志初始化写法。299 收藏
Python 项目里同一条日志重复出现两三次,常见原因是重复 addHandler 或子 logger 向根 logger 继续上抛。本文从复现现象开始,逐步检查 Handler 数量、logger 层级和 propagate 配置,整理一套稳定的日志初始化写法。299 收藏 -
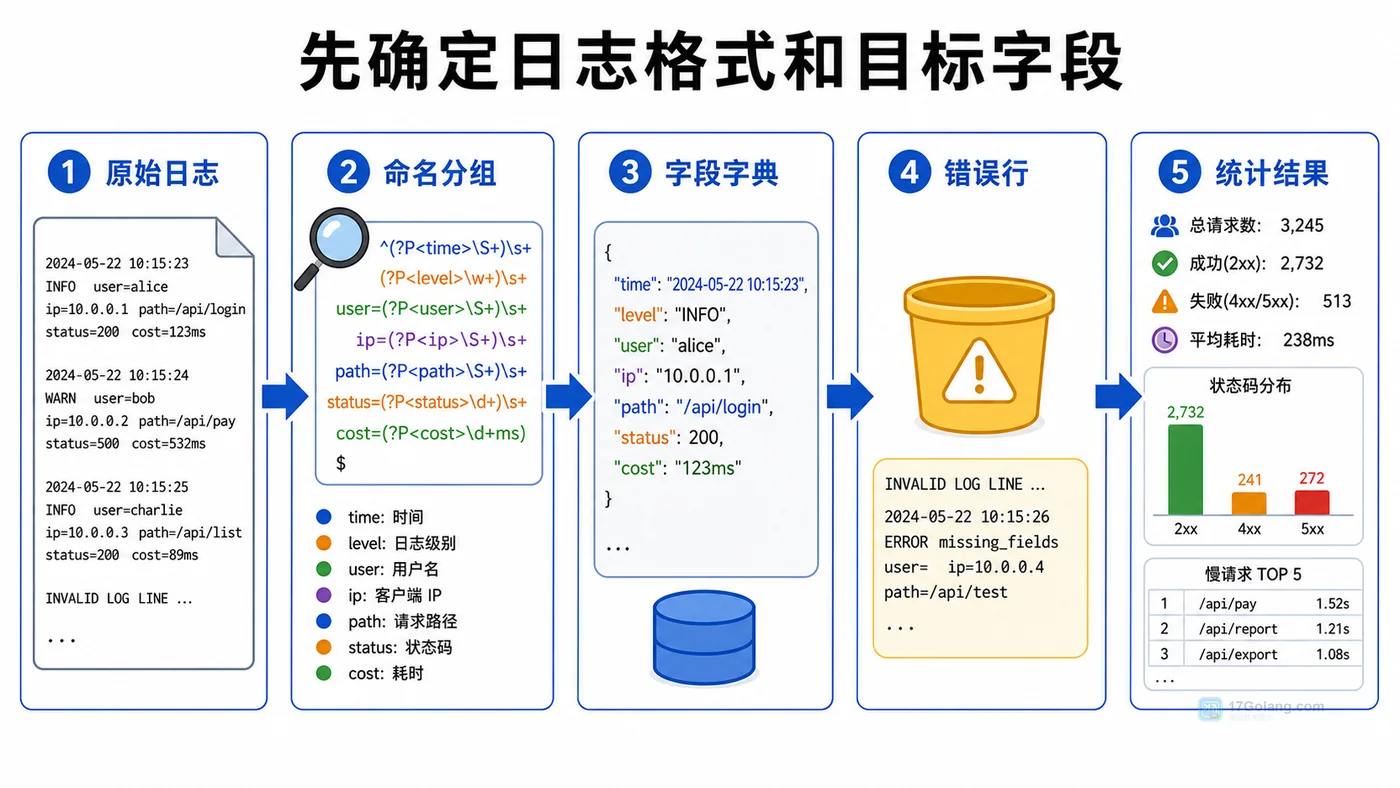 本文用 Python 解析访问日志的场景讲清正则命名分组:如何把原始日志拆成字段字典,如何处理格式不符合预期的错误行,最后统计接口访问次数、状态码分布和慢请求。308 收藏
本文用 Python 解析访问日志的场景讲清正则命名分组:如何把原始日志拆成字段字典,如何处理格式不符合预期的错误行,最后统计接口访问次数、状态码分布和慢请求。308 收藏 -
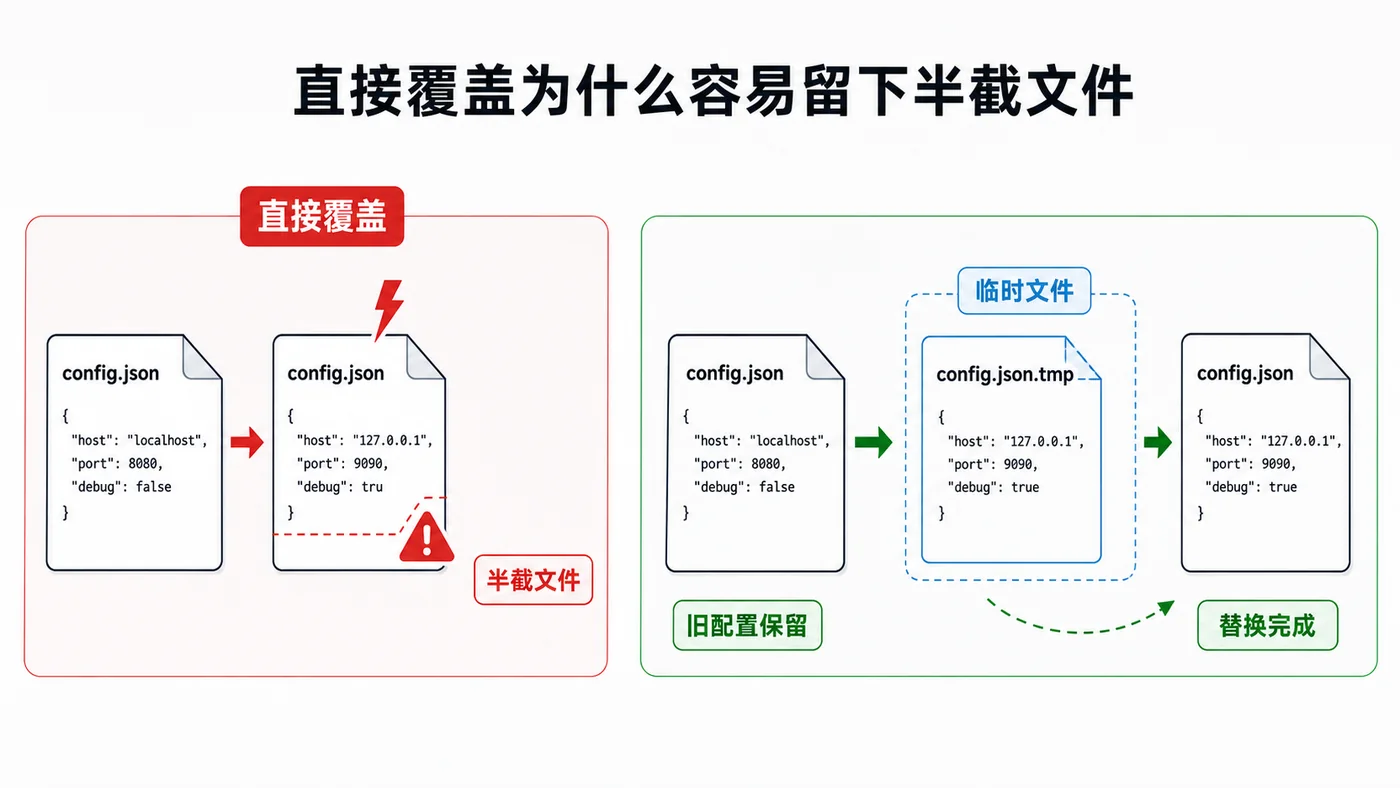 本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。209 收藏
本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。209 收藏 -
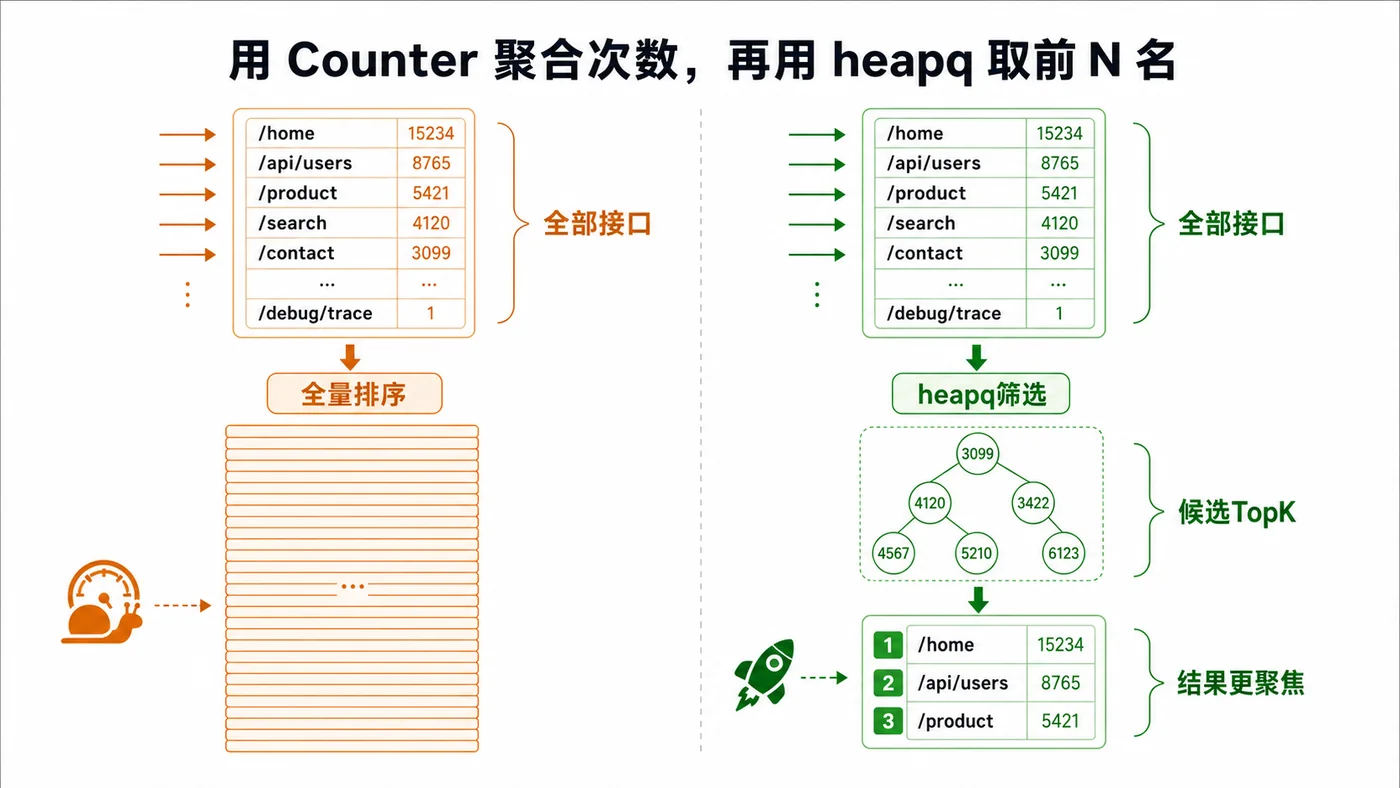 本文用 Python 标准库完成日志 TopK 统计:逐行读取大文件、用 Counter 聚合接口次数,再用 heapq 取出高频接口,适合快速排查访问热点和接口倾斜问题。329 收藏
本文用 Python 标准库完成日志 TopK 统计:逐行读取大文件、用 Counter 聚合接口次数,再用 heapq 取出高频接口,适合快速排查访问热点和接口倾斜问题。329 收藏 -
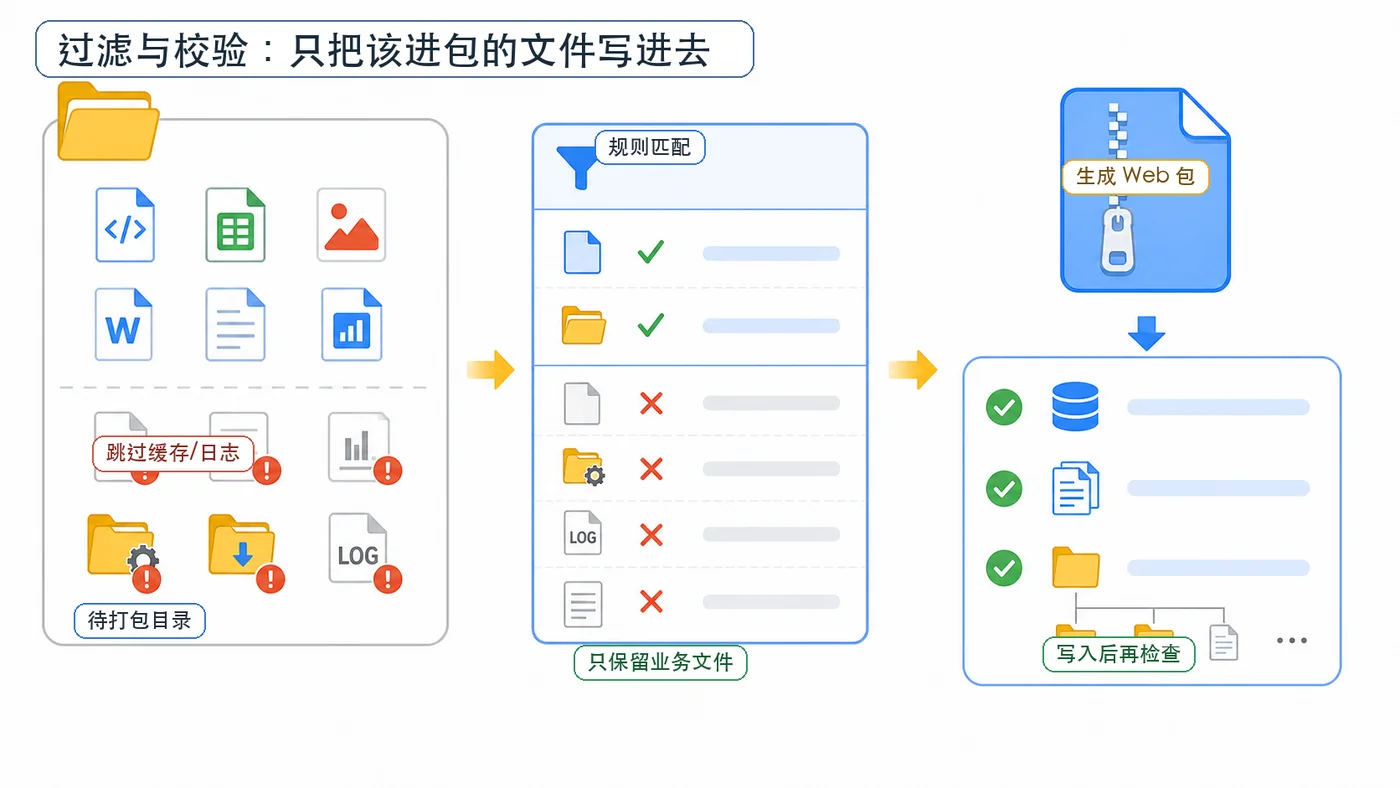 用 Python 标准库 zipfile 做一个可靠的批量打包脚本:遍历源目录、保留相对路径、跳过缓存和日志文件,写入压缩包后再校验文件数量、路径和 CRC 结果。437 收藏
用 Python 标准库 zipfile 做一个可靠的批量打包脚本:遍历源目录、保留相对路径、跳过缓存和日志文件,写入压缩包后再校验文件数量、路径和 CRC 结果。437 收藏 -
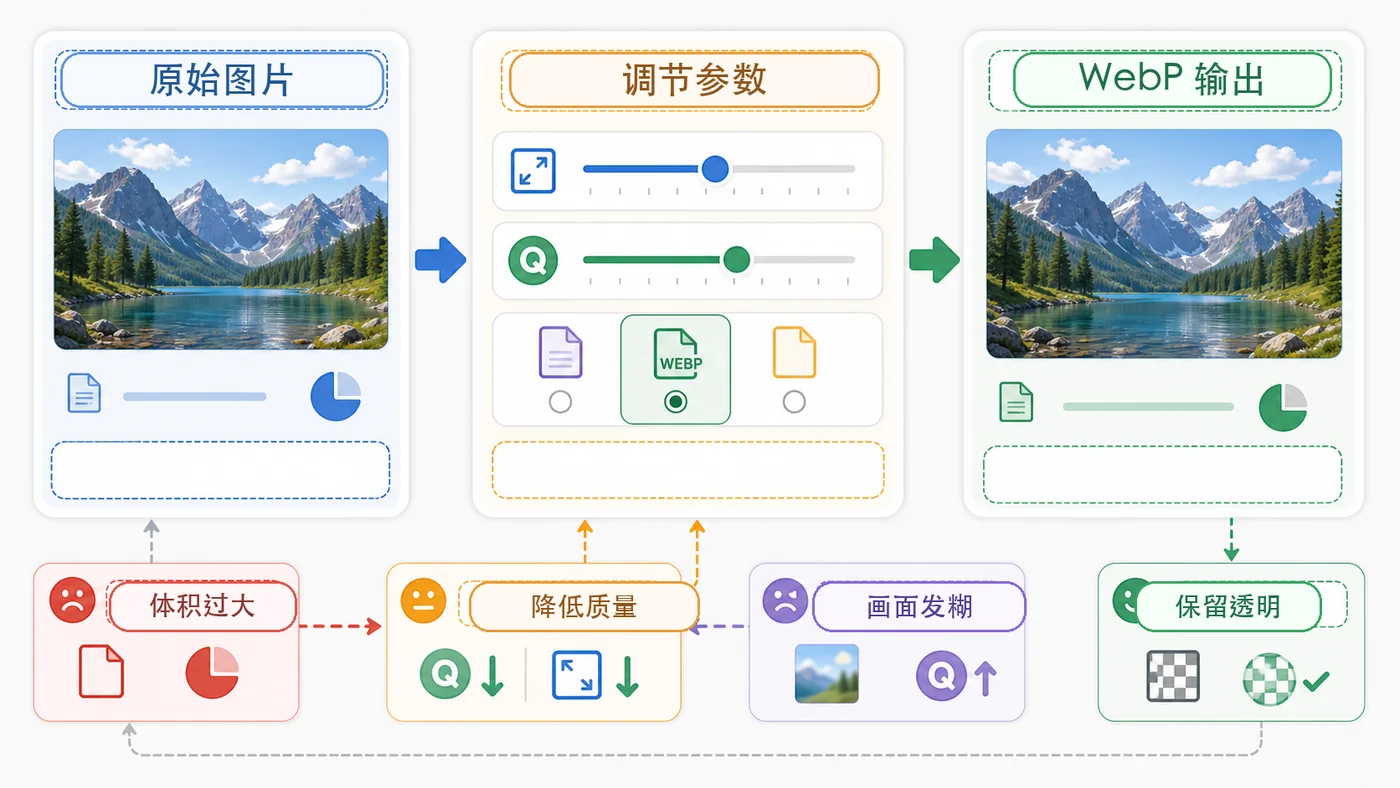 本文用 Python Pillow 实现图片批量压缩:从输入目录读取图片,按最大宽度等比缩放,输出 WebP,并生成压缩清单方便检查体积和清晰度。299 收藏
本文用 Python Pillow 实现图片批量压缩:从输入目录读取图片,按最大宽度等比缩放,输出 WebP,并生成压缩清单方便检查体积和清晰度。299 收藏 -
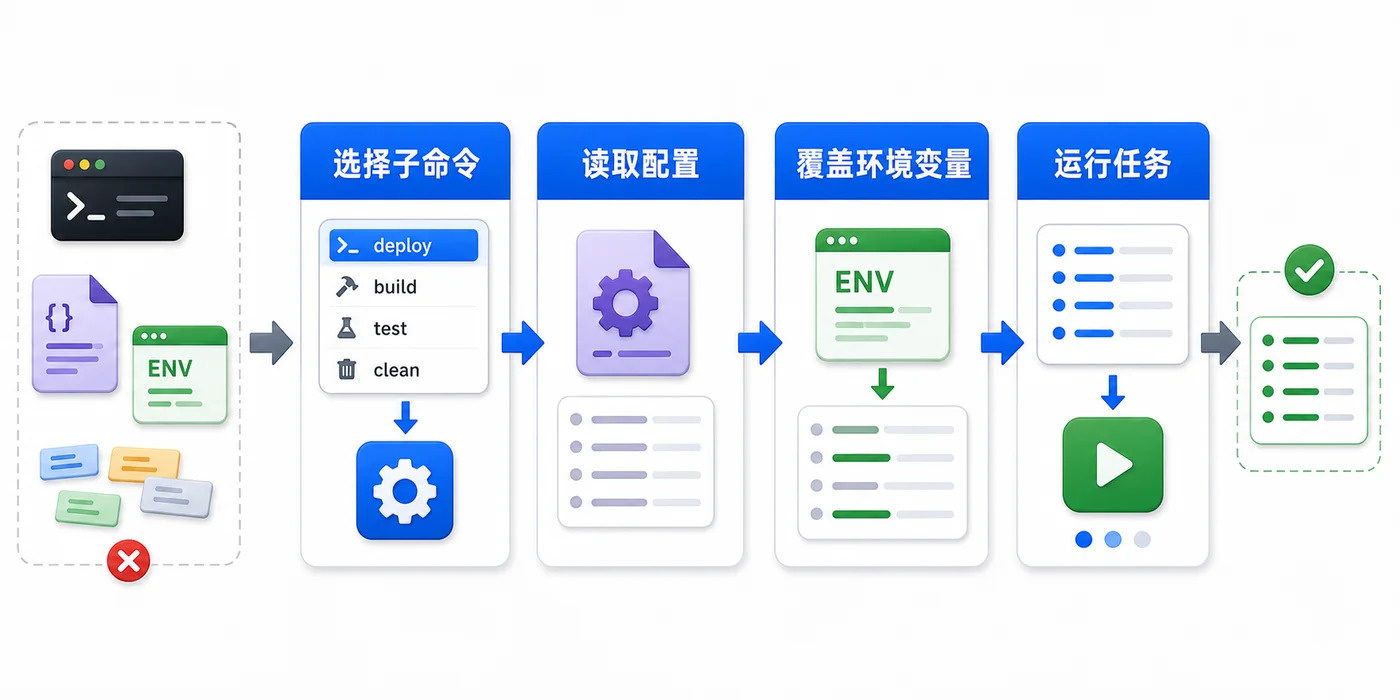 本文用日志清理工具做例子,演示 Python argparse 如何解析参数、校验类型、设计子命令,并把配置文件和环境变量合并成最终运行参数。241 收藏
本文用日志清理工具做例子,演示 Python argparse 如何解析参数、校验类型、设计子命令,并把配置文件和环境变量合并成最终运行参数。241 收藏 -
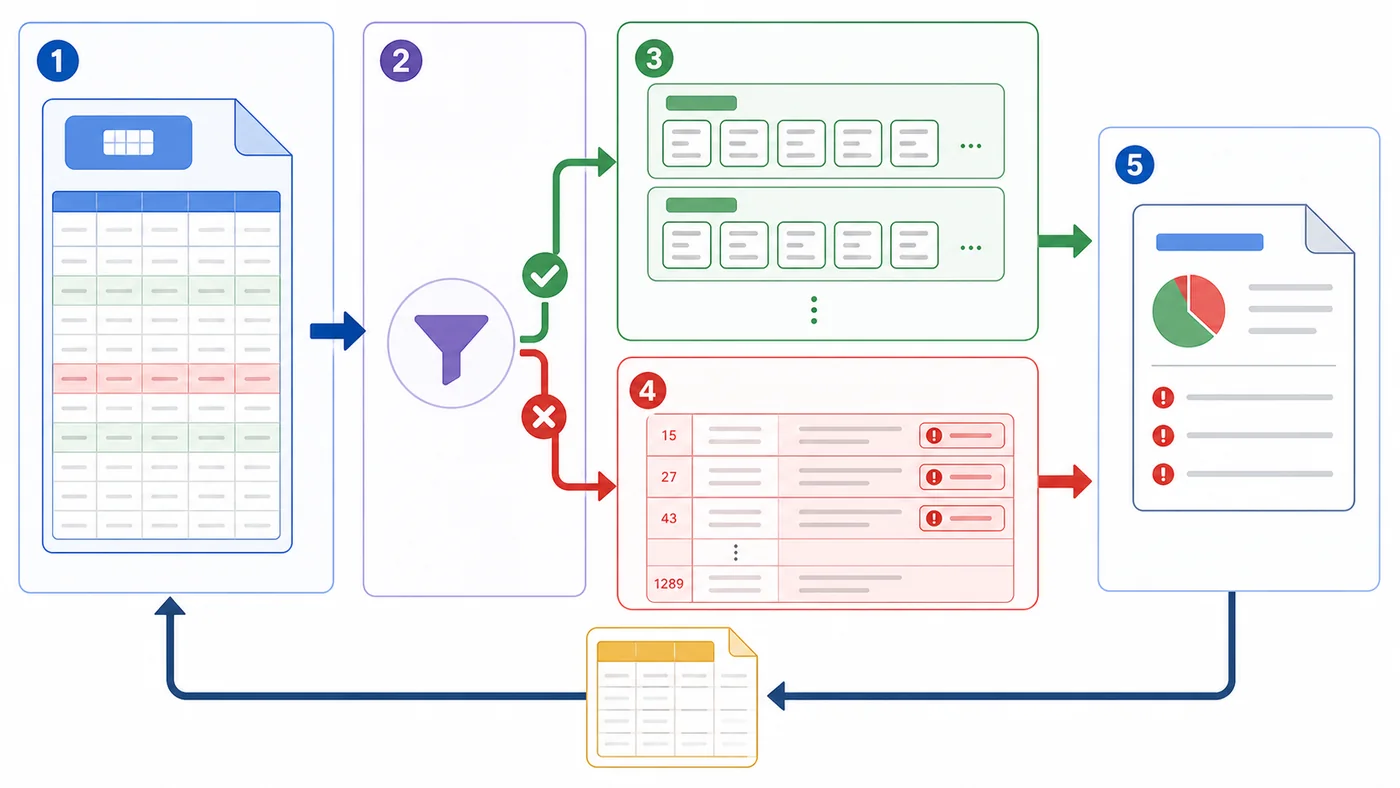 本文用用户 CSV 导入场景,演示如何边读边校验、按批次写入、收集错误行并生成失败明细,避免一次性读入和半成功数据污染。204 收藏
本文用用户 CSV 导入场景,演示如何边读边校验、按批次写入、收集错误行并生成失败明细,避免一次性读入和半成功数据污染。204 收藏 -
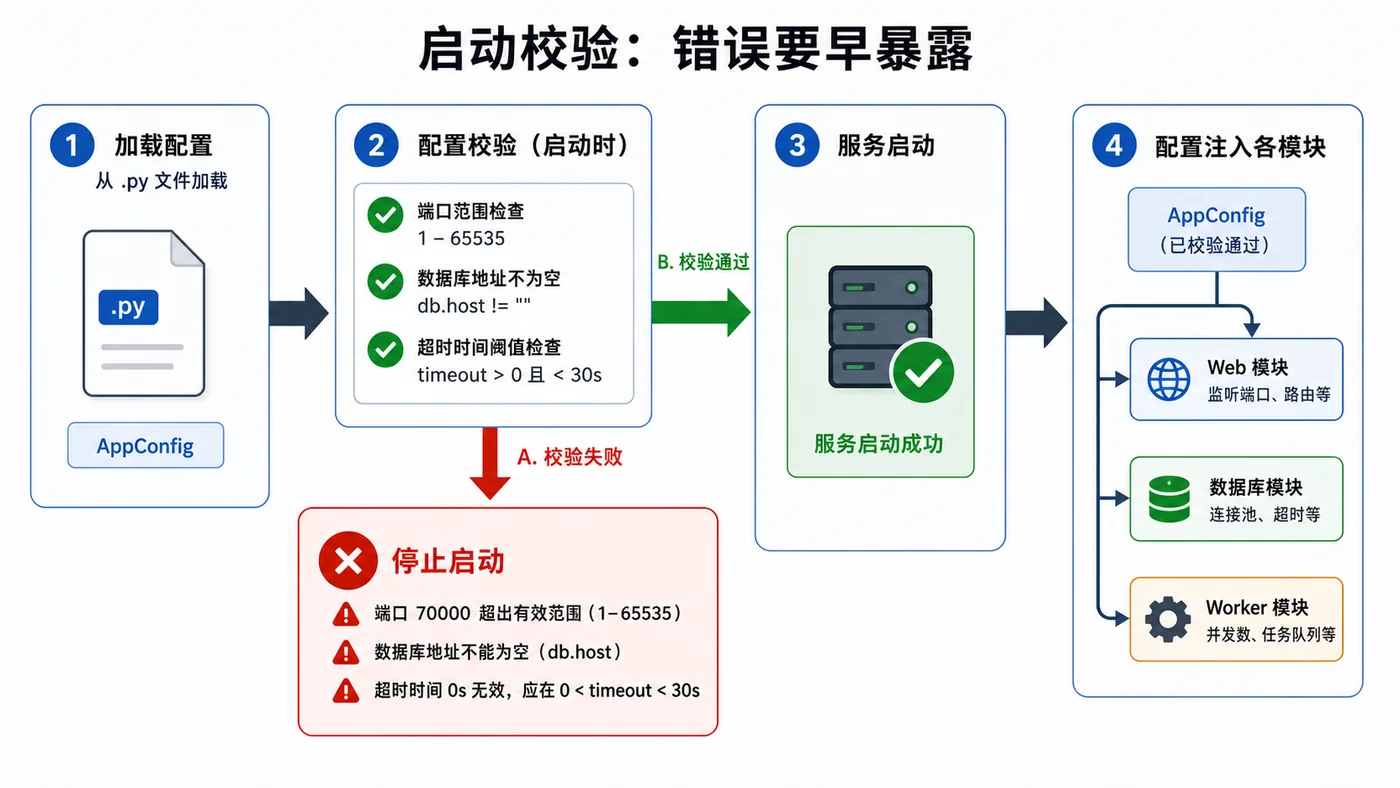 本文用标准库 dataclass 写一套轻量配置加载方案,演示默认值、环境变量覆盖、类型转换和启动校验,避免服务上线后才发现端口、数据库地址或超时参数写错。131 收藏
本文用标准库 dataclass 写一套轻量配置加载方案,演示默认值、环境变量覆盖、类型转换和启动校验,避免服务上线后才发现端口、数据库地址或超时参数写错。131 收藏 -
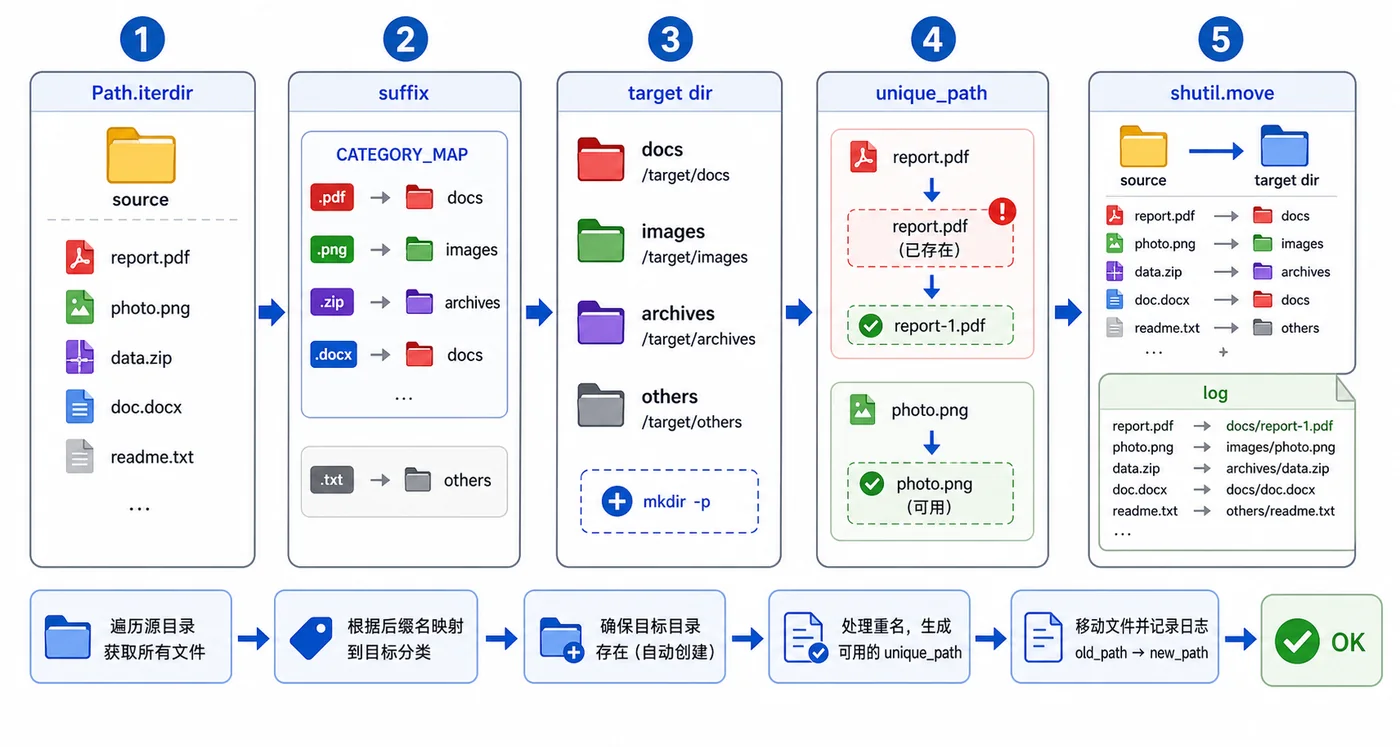 用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。166 收藏
用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。166 收藏 -
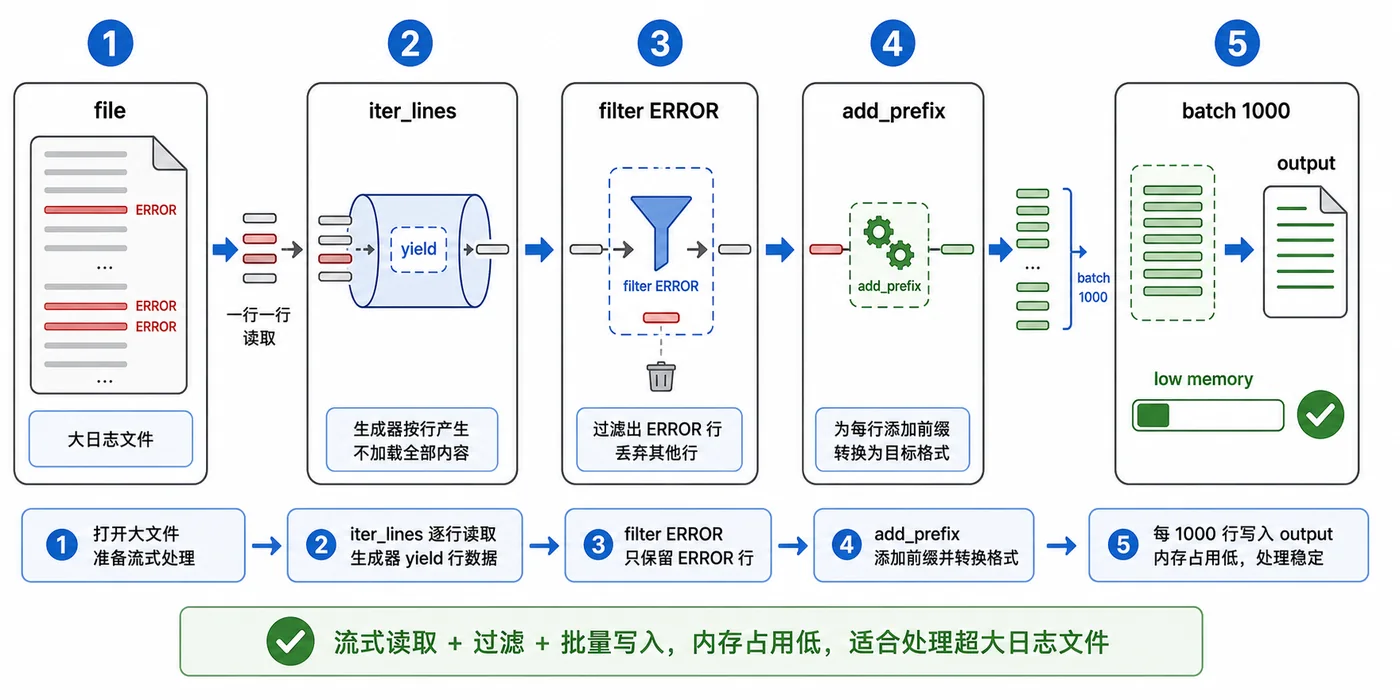 用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。311 收藏
用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。311 收藏 -
文章 · python教程 | 1个月前 | 日志 · 链路追踪 · Python教程 · contextvars · Python logging contextvars 日志追踪 trace_id 异步上下文
 通过一个接口请求日志案例,演示如何用 contextvars 保存 trace_id,并通过 logging Filter 自动写入每条日志,适合同步和异步 Python 项目排查问题。370 收藏
通过一个接口请求日志案例,演示如何用 contextvars 保存 trace_id,并通过 logging Filter 自动写入每条日志,适合同步和异步 Python 项目排查问题。370 收藏 -
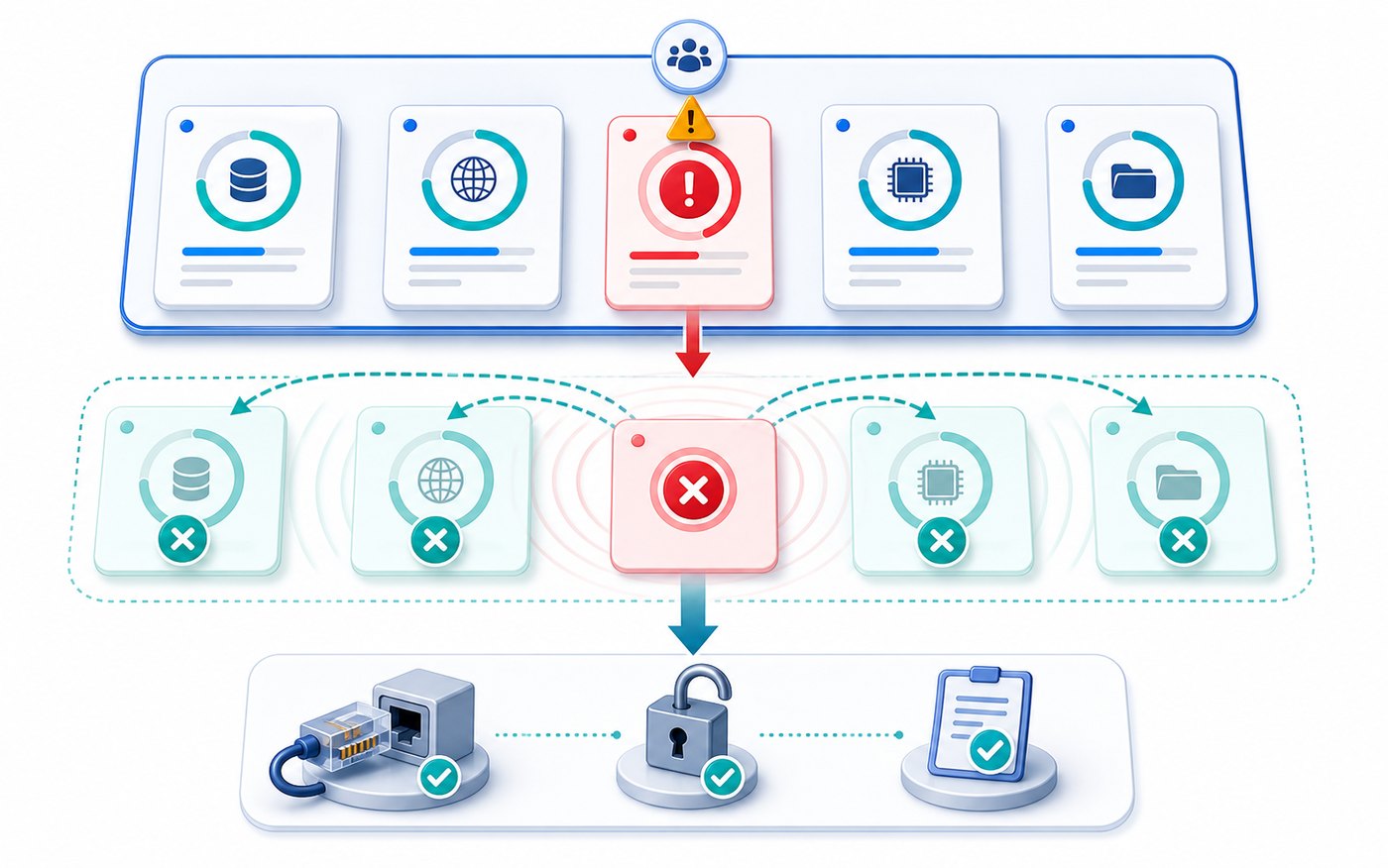 通过一个异步接口聚合案例,演示 asyncio.timeout、wait_for、TaskGroup、shield 和取消传播的用法,帮助 Python 项目把慢任务、半完成状态和资源清理管住。457 收藏
通过一个异步接口聚合案例,演示 asyncio.timeout、wait_for、TaskGroup、shield 和取消传播的用法,帮助 Python 项目把慢任务、半完成状态和资源清理管住。457 收藏 -
 通过外部 API 调用场景,演示 Python requests 如何设置 connect/read 超时、复用 Session 连接池、配置重试策略,并记录日志定位慢请求。105 收藏
通过外部 API 调用场景,演示 Python requests 如何设置 connect/read 超时、复用 Session 连接池、配置重试策略,并记录日志定位慢请求。105 收藏 -
文章 · python教程 | 1个月前 | 异步编程 · 生产实践 · 后端工程 · Python教程 · Celery · 任务队列 · Python 故障排查 任务队列 异步任务 幂等 生产实践 Celery 5.4 retry_backoff acks_late
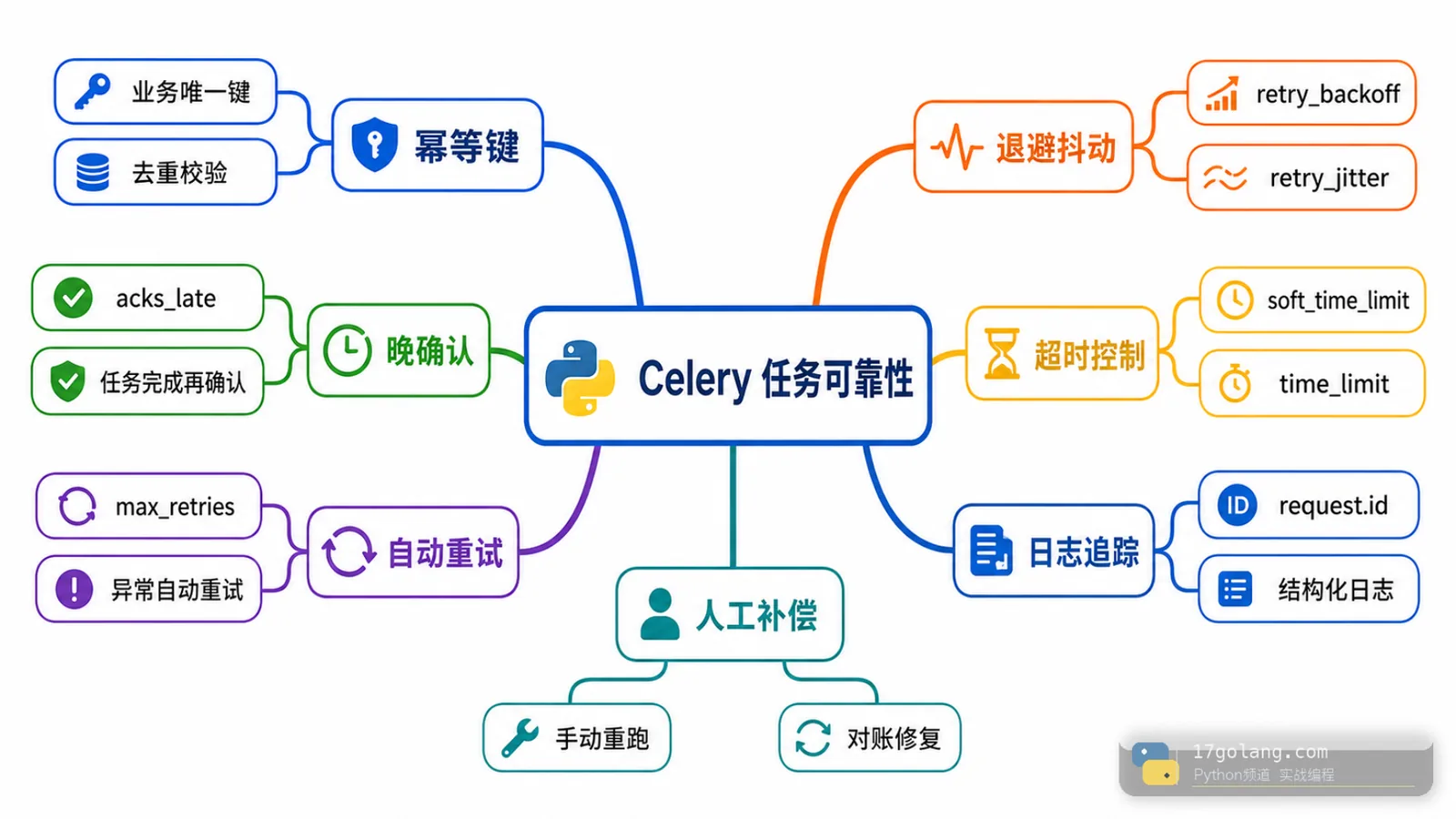 从 Python Celery 任务重复执行事故入手,实战讲解业务幂等键、acks_late、自动重试、指数退避、超时控制和上线观测。340 收藏
从 Python Celery 任务重复执行事故入手,实战讲解业务幂等键、acks_late、自动重试、指数退避、超时控制和上线观测。340 收藏