Go语言技术文章
-
 Redis集群启动失败、节点无法握手、CLUSTERNODES显示fail或connecting,大概率是Bus端口(clientport+10000)被占用;需确保各节点clientport与其对应bus端口区间互不重叠,如7000→17000,则下一节点clientport至少为17001。275 收藏
Redis集群启动失败、节点无法握手、CLUSTERNODES显示fail或connecting,大概率是Bus端口(clientport+10000)被占用;需确保各节点clientport与其对应bus端口区间互不重叠,如7000→17000,则下一节点clientport至少为17001。275 收藏 -
 彻底禁用RDB自动触发需注释或设为save"",重启或CONFIGREWRITE后CONFIGGETsave返回["save",""],且rdb_changes_since_last_save持续增长即生效。272 收藏
彻底禁用RDB自动触发需注释或设为save"",重启或CONFIGREWRITE后CONFIGGETsave返回["save",""],且rdb_changes_since_last_save持续增长即生效。272 收藏 -
 Redis默认tcp-keepalive关闭(值为0),需主从双方redis.conf显式配置tcp-keepalive300并重启生效,且须与repl-timeout≥300协同调整,否则连接假活导致复制卡死。272 收藏
Redis默认tcp-keepalive关闭(值为0),需主从双方redis.conf显式配置tcp-keepalive300并重启生效,且须与repl-timeout≥300协同调整,否则连接假活导致复制卡死。272 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · InnoDB · MySQL教程 · 数据库运维 · 高并发写入 · mysql innodb 批量写入 Change Buffer innodb_change_buffering
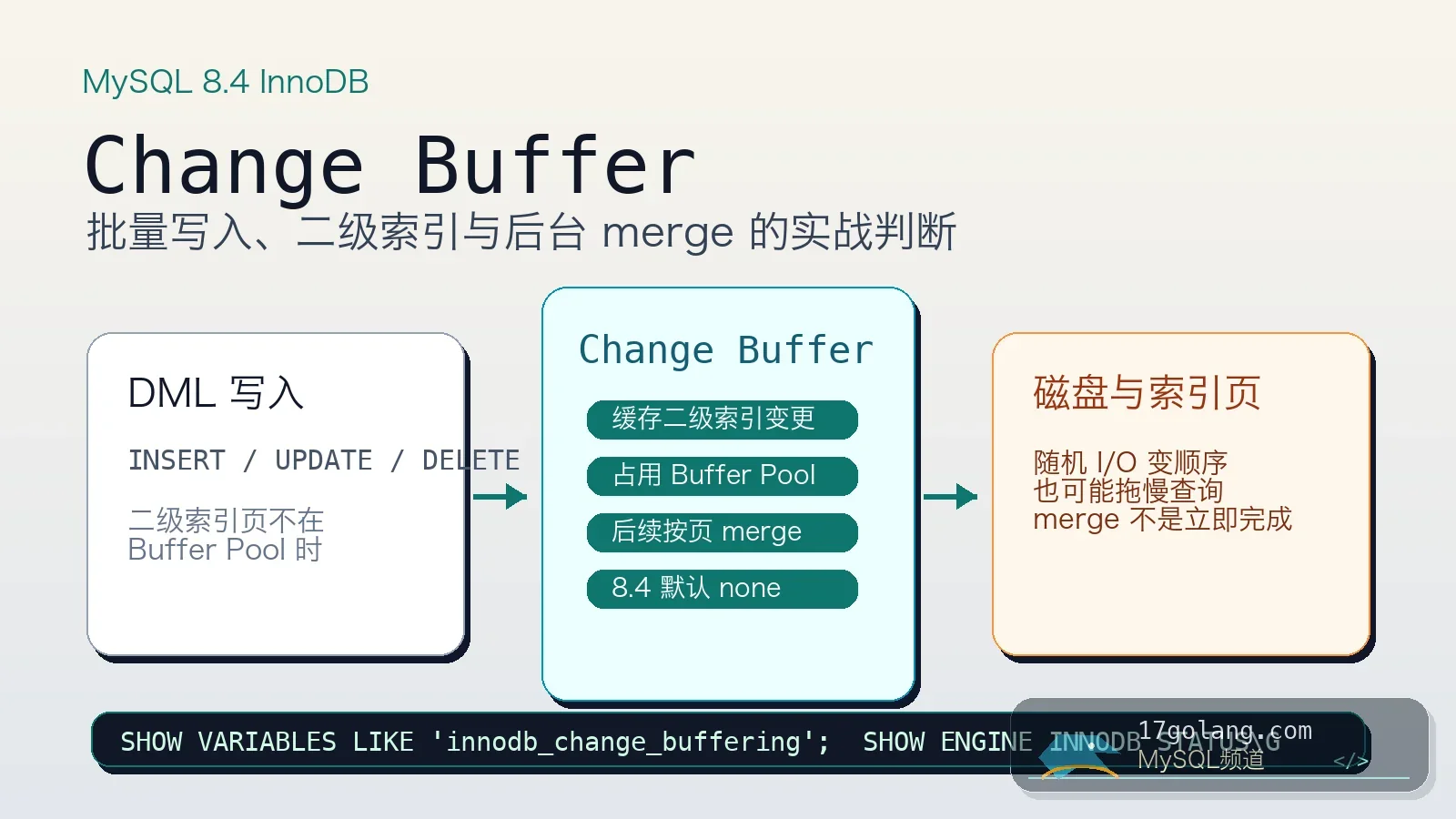 从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏
从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · 执行计划 · MySQL教程 · 慢查询治理 · 数据库运维 · mysql GROUP BY优化 TempTable 内部临时表 Created_tmp_disk_tables
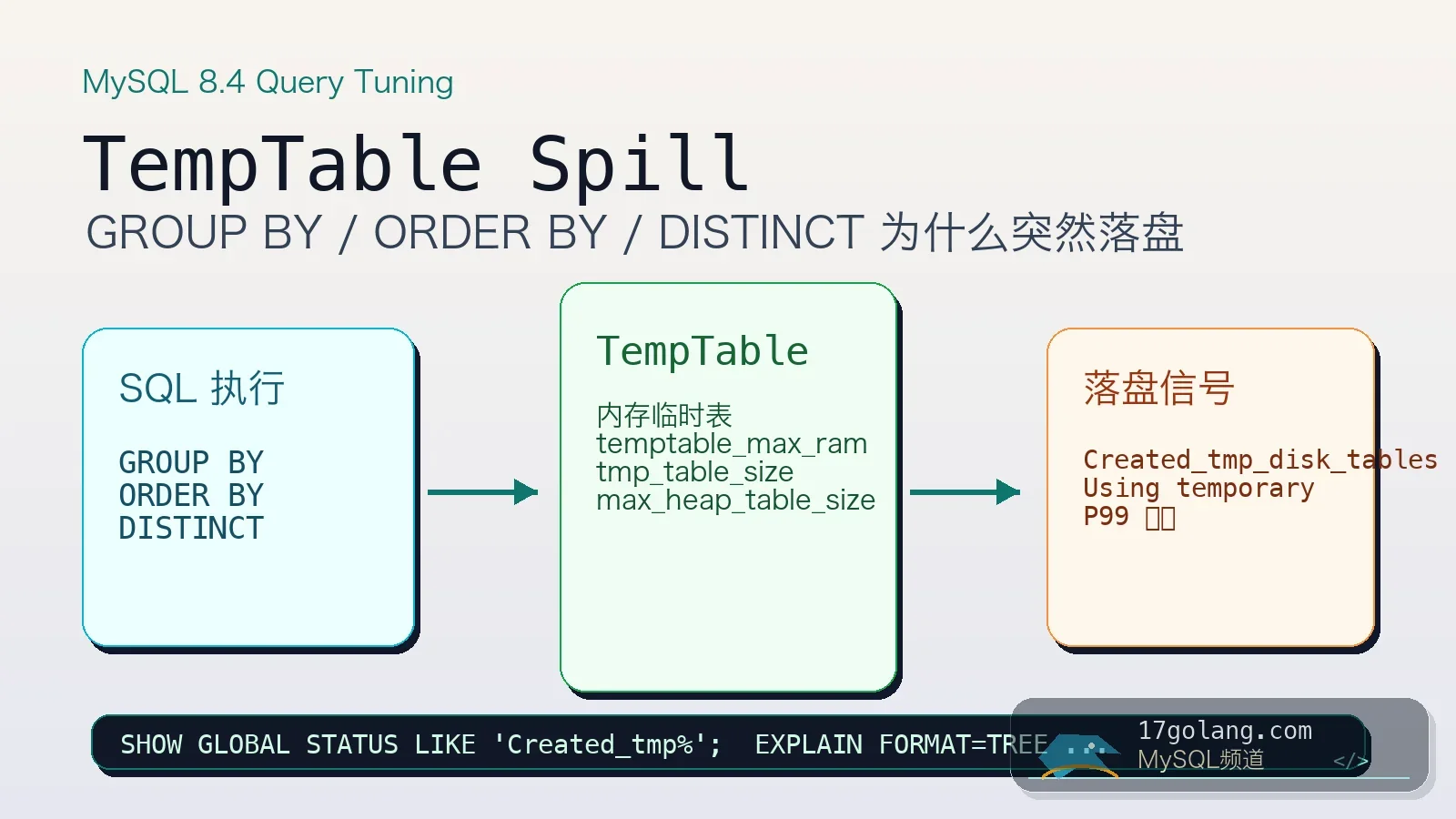 从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏
从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏 -
 serverCron每100ms检查一次,仅当无RDB/AOF子进程时,才根据saveparams(dirty+lastsave)触发RDB,或根据AOF状态、大小及增长率触发AOF重写;改配置不重置计时/计数,故不立即生效。265 收藏
serverCron每100ms检查一次,仅当无RDB/AOF子进程时,才根据saveparams(dirty+lastsave)触发RDB,或根据AOF状态、大小及增长率触发AOF重写;改配置不重置计时/计数,故不立即生效。265 收藏 -
 Redis集群中requirepass无效,因其仅作用于客户端端口(如6379),不约束集群总线端口(如16379);节点间通信明文进行,需依赖网络隔离、ACL及正确配置cluster-announce-ip等措施保障安全。263 收藏
Redis集群中requirepass无效,因其仅作用于客户端端口(如6379),不约束集群总线端口(如16379);节点间通信明文进行,需依赖网络隔离、ACL及正确配置cluster-announce-ip等措施保障安全。263 收藏 -
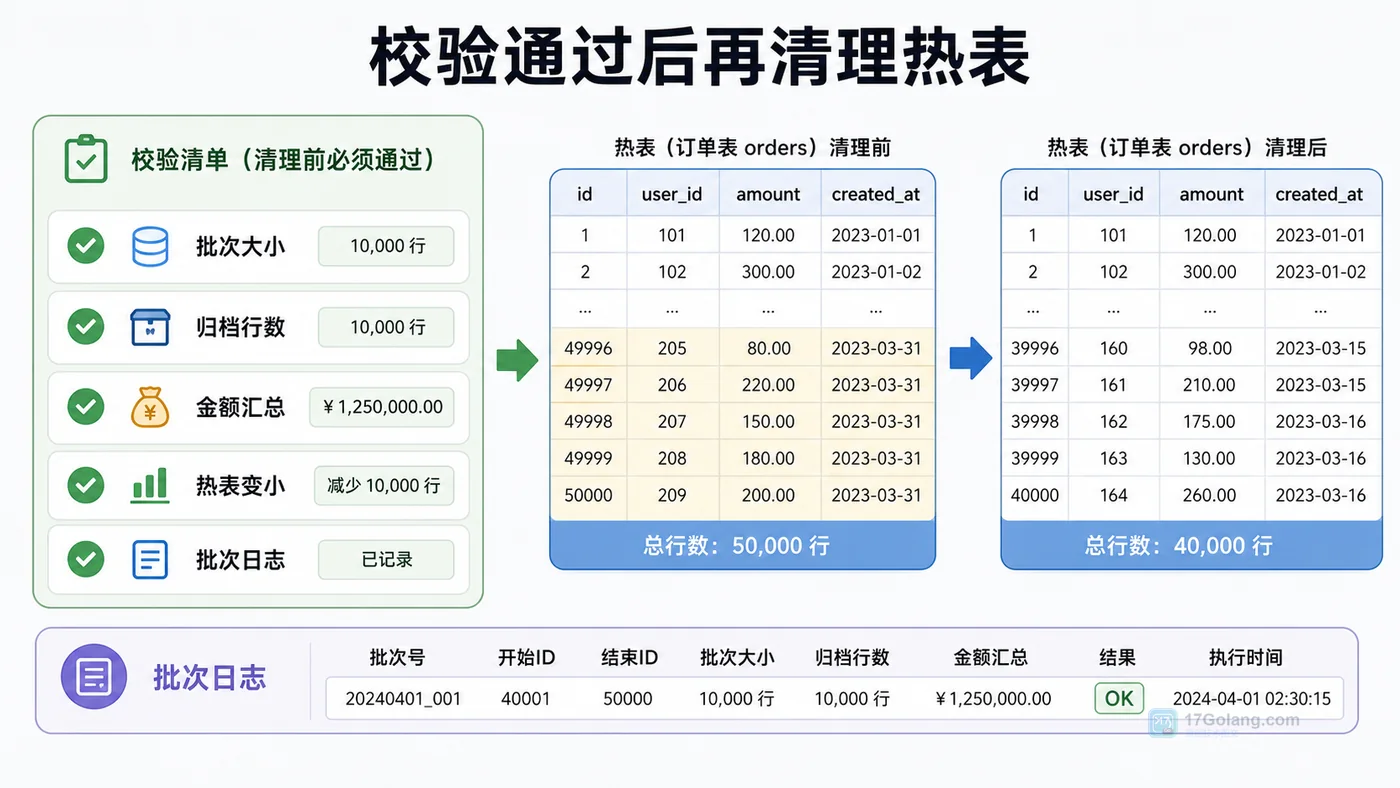 本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏
本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏 -
 空值缓存过期时间设太长会导致Redis内存耗尽。因空值key不被访问,LRU无法淘汰,且每个约占100–200字节,数量多时迅速撑满内存;安全TTL应为1–5秒,需匹配业务数据可见延迟,并配合布隆过滤器、前缀命名、LFU策略及监控告警综合防控。260 收藏
空值缓存过期时间设太长会导致Redis内存耗尽。因空值key不被访问,LRU无法淘汰,且每个约占100–200字节,数量多时迅速撑满内存;安全TTL应为1–5秒,需匹配业务数据可见延迟,并配合布隆过滤器、前缀命名、LFU策略及监控告警综合防控。260 收藏 -
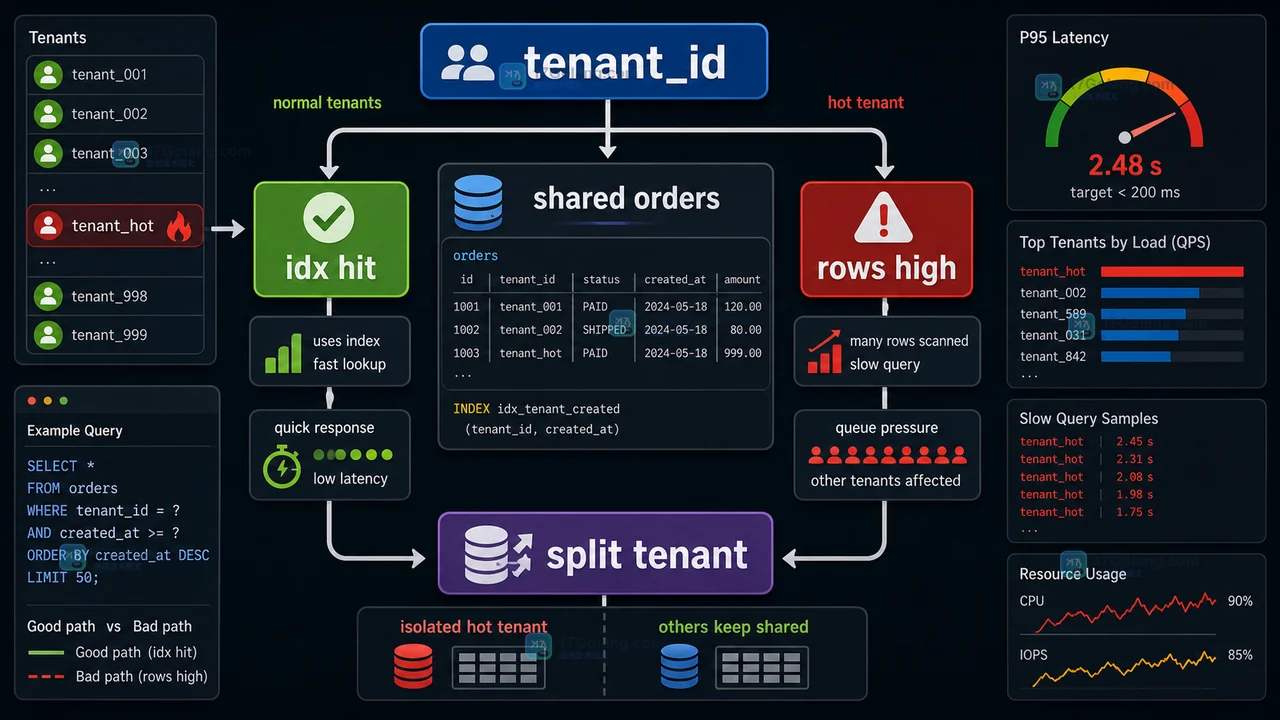 MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高 rows、慢日志和队列等待,再考虑租户路由、冷热分流或独立分片。259 收藏
MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高 rows、慢日志和队列等待,再考虑租户路由、冷热分流或独立分片。259 收藏 -
数据库 · Redis | 5天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT
 商品详情页把库存、价格和活动状态合成一次 MGET 后,在 Redis Cluster 里突然报 CROSSSLOT,根因往往不是客户端,而是同一业务实体的 Key 没有落到同一个槽位。本文用 CLUSTER KEYSLOT、Hash Tag 和迁移期检查拆出一条可复查的修复路径。259 收藏
商品详情页把库存、价格和活动状态合成一次 MGET 后,在 Redis Cluster 里突然报 CROSSSLOT,根因往往不是客户端,而是同一业务实体的 Key 没有落到同一个槽位。本文用 CLUSTER KEYSLOT、Hash Tag 和迁移期检查拆出一条可复查的修复路径。259 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · 高并发 · InnoDB · MySQL教程 · 数据库运维 · mysql innodb AUTO_INCREMENT 高并发写入 innodb_autoinc_lock_mode
 从 MySQL 8.4 AUTO_INCREMENT 锁模式入手,讲清高并发 INSERT、批量导入、复制格式和上线回滚检查。254 收藏
从 MySQL 8.4 AUTO_INCREMENT 锁模式入手,讲清高并发 INSERT、批量导入、复制格式和上线回滚检查。254 收藏 -
 Redis7.0的io-threads仅加速socketread/write/RESP解析,不执行命令;盲目开启或多设线程数反致延迟上升、吞吐下降,需先确认瓶颈确在IO层而非主线程或内存带宽。251 收藏
Redis7.0的io-threads仅加速socketread/write/RESP解析,不执行命令;盲目开启或多设线程数反致延迟上升、吞吐下降,需先确认瓶颈确在IO层而非主线程或内存带宽。251 收藏 -
 Redis 7.0 起,EXPIRE 可用 NX、XX、GT、LT 为过期时间加条件。NX 只给没有 TTL 的 key 首次设置过期,XX 只更新已有 TTL 的 key,GT 只允许延长,LT 只允许缩短。它们互斥;TTL 返回 -1 表示 key 存在但没有过期时间,-2 表示 key 不存在。把条件写清楚,才能避免续期任务意外把缓存窗口改乱。250 收藏
Redis 7.0 起,EXPIRE 可用 NX、XX、GT、LT 为过期时间加条件。NX 只给没有 TTL 的 key 首次设置过期,XX 只更新已有 TTL 的 key,GT 只允许延长,LT 只允许缩短。它们互斥;TTL 返回 -1 表示 key 存在但没有过期时间,-2 表示 key 不存在。把条件写清楚,才能避免续期任务意外把缓存窗口改乱。250 收藏 -
 根本原因是sentineldown-after-milliseconds阈值过短,而主库执行耗时Lua脚本导致PING响应超时,哨兵误判为主观下线;典型表现为INFOreplication正常但日志频繁出现+sdown又快速恢复。247 收藏
根本原因是sentineldown-after-milliseconds阈值过短,而主库执行耗时Lua脚本导致PING响应超时,哨兵误判为主观下线;典型表现为INFOreplication正常但日志频繁出现+sdown又快速恢复。247 收藏