Go语言技术文章
-
 LATENCYDOCTOR无法诊断atop导致的毛刺,因其只监控Redis内部延迟(如事件循环、命令执行、AOF写入),而atop-R读取/proc/pid/smaps触发的内核页表锁争用发生在内核态,Redis用户态线程无法感知。243 收藏
LATENCYDOCTOR无法诊断atop导致的毛刺,因其只监控Redis内部延迟(如事件循环、命令执行、AOF写入),而atop-R读取/proc/pid/smaps触发的内核页表锁争用发生在内核态,Redis用户态线程无法感知。243 收藏 -
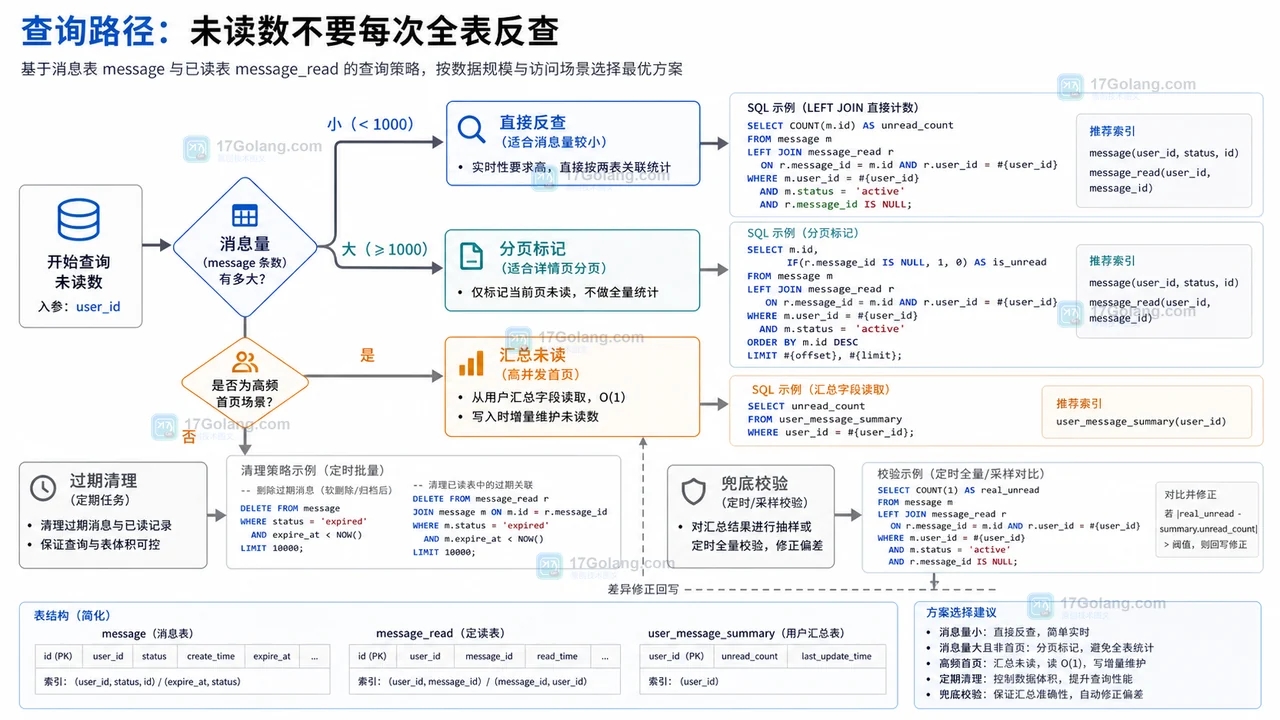 本文按数据生命周期说明 MySQL 消息已读表设计:消息如何产生,已读记录如何去重写入,未读数如何查询,重复点击和并发如何处理,以及历史数据如何清理。243 收藏
本文按数据生命周期说明 MySQL 消息已读表设计:消息如何产生,已读记录如何去重写入,未读数如何查询,重复点击和并发如何处理,以及历史数据如何清理。243 收藏 -
 命中率低于75%(即keyspace_hits:keyspace_misses<3:1)时应调整淘汰策略,因缓存已无法有效分担数据库压力;需结合evicted_keys增速与keyspace_misses增速同步上升来确认问题根源。242 收藏
命中率低于75%(即keyspace_hits:keyspace_misses<3:1)时应调整淘汰策略,因缓存已无法有效分担数据库压力;需结合evicted_keys增速与keyspace_misses增速同步上升来确认问题根源。242 收藏 -
数据库 · MySQL | 3星期前 | MySQL · InnoDB · 性能排查 · 故障复盘 · 长事务 · mysql PURGE 长事务 Undo history list length 写入延迟
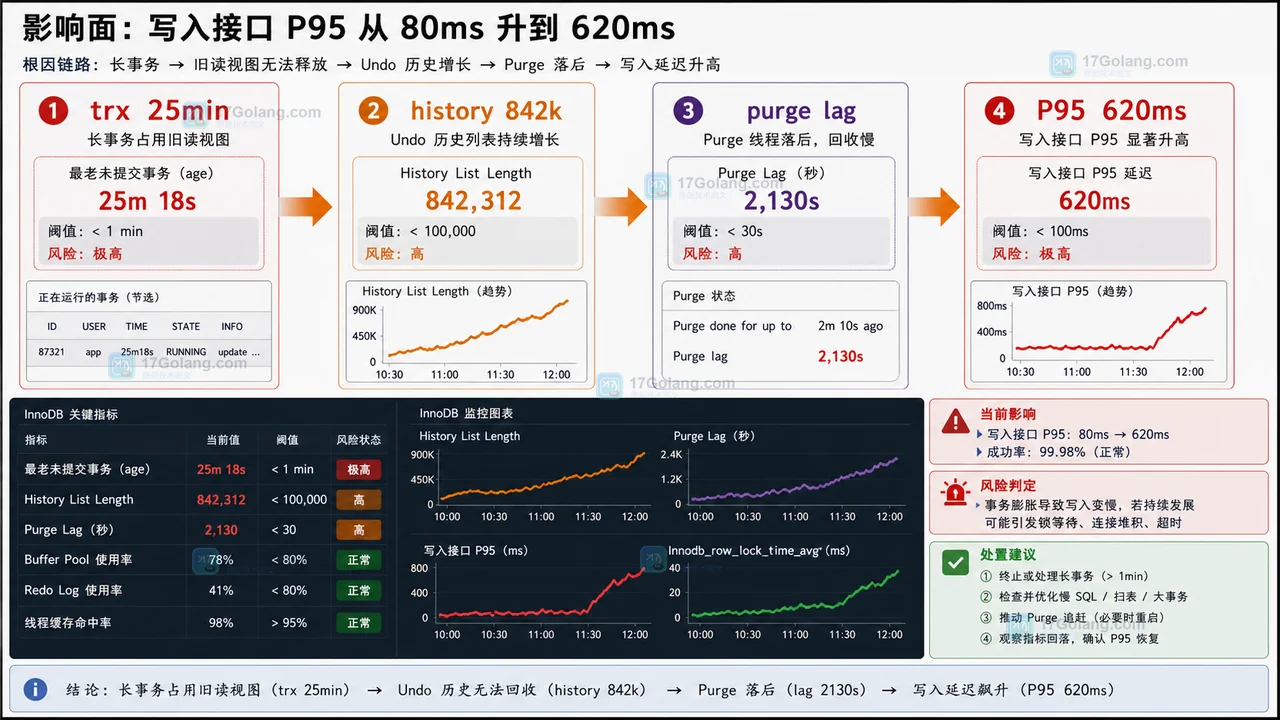 复盘一次 MySQL 写入延迟突然升高的问题:从影响面和时间线入手,通过 innodb_trx、history list length 和 purge 状态定位长事务拖住 undo 清理,并给出修复和防复发清单。242 收藏
复盘一次 MySQL 写入延迟突然升高的问题:从影响面和时间线入手,通过 innodb_trx、history list length 和 purge 状态定位长事务拖住 undo 清理,并给出修复和防复发清单。242 收藏 -
 可行但仅适用于轻量场景;必须用EVAL执行Lua脚本原子完成“取+删”或“取+标记”,避免LPOP+DEL竞态导致重复消费或消息丢失。241 收藏
可行但仅适用于轻量场景;必须用EVAL执行Lua脚本原子完成“取+删”或“取+标记”,避免LPOP+DEL竞态导致重复消费或消息丢失。241 收藏 -
数据库 · MySQL | 6天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移
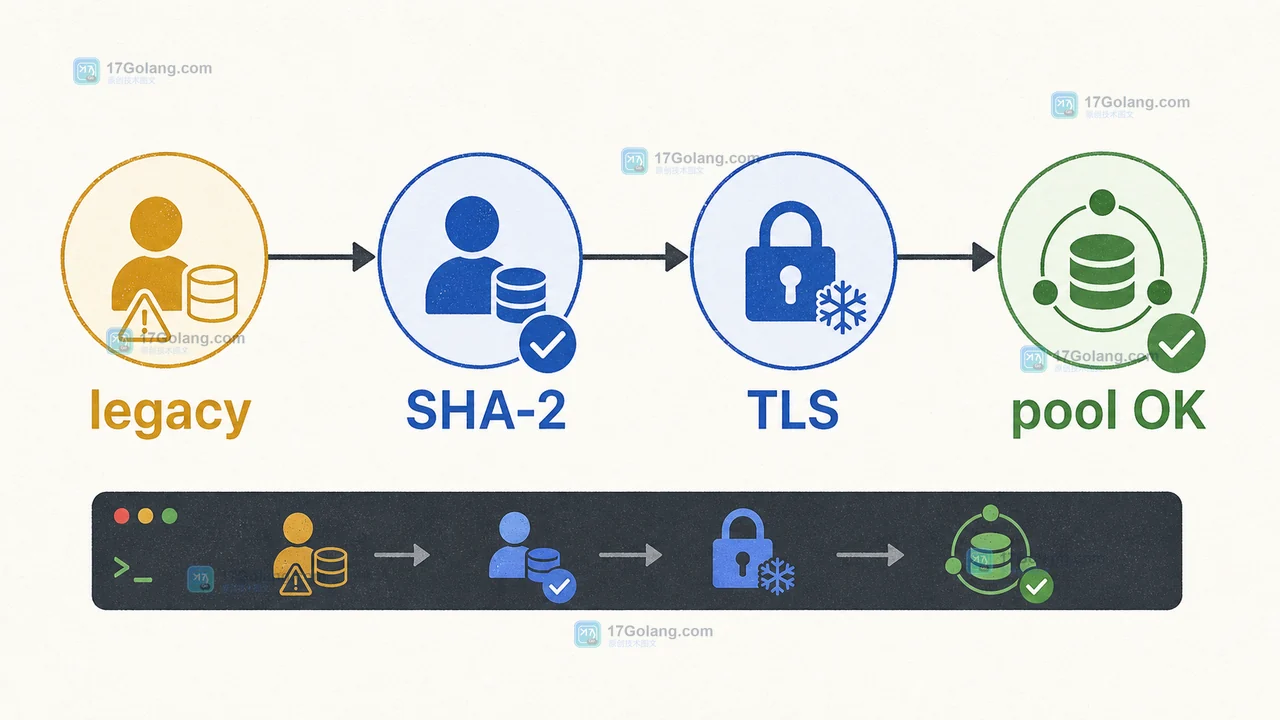 MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏
MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏 -
 本文从热点 Key 过期导致数据库 QPS 飙升的现场出发,排查 Redis 缓存击穿原因,并用互斥锁、旧值兜底和缓存重建流程修复。235 收藏
本文从热点 Key 过期导致数据库 QPS 飙升的现场出发,排查 Redis 缓存击穿原因,并用互斥锁、旧值兜底和缓存重建流程修复。235 收藏 -
 String类型在LRU驱逐场景下内存效率低,因其每个key和value均独立占用redisObject+SDS结构,导致对象头冗余高、驱逐粒度粗;而Hash等结构共享key对象头、支持ziplist压缩,内存利用率高40%~60%。233 收藏
String类型在LRU驱逐场景下内存效率低,因其每个key和value均独立占用redisObject+SDS结构,导致对象头冗余高、驱逐粒度粗;而Hash等结构共享key对象头、支持ziplist压缩,内存利用率高40%~60%。233 收藏 -
 应立即将maxmemory-policy从allkeys-lru切回volatile-lru,但需先停写、确认内存未满,再执行CONFIGSET与REWRITE,并配合RDB恢复关键数据,否则残留无TTLkey将持续引发淘汰。232 收藏
应立即将maxmemory-policy从allkeys-lru切回volatile-lru,但需先停写、确认内存未满,再执行CONFIGSET与REWRITE,并配合RDB恢复关键数据,否则残留无TTLkey将持续引发淘汰。232 收藏 -
 Redis的String类型加剧内存碎片是因为频繁SET/GET/APPEND导致jemalloc中大小不一的内存块反复分配释放,旧块无法复用而残留为碎片,表现为mem_fragmentation_ratio>1.5且used_memory_rss远大于used_memory。230 收藏
Redis的String类型加剧内存碎片是因为频繁SET/GET/APPEND导致jemalloc中大小不一的内存块反复分配释放,旧块无法复用而残留为碎片,表现为mem_fragmentation_ratio>1.5且used_memory_rss远大于used_memory。230 收藏 -
 缓存空值、布隆过滤器和业务层校验是防御缓存穿透的三层策略:空值需设短过期并避免null值;布隆过滤器须预估容量、全局单例且配合写库更新;业务层应优先校验参数合法性。229 收藏
缓存空值、布隆过滤器和业务层校验是防御缓存穿透的三层策略:空值需设短过期并避免null值;布隆过滤器须预估容量、全局单例且配合写库更新;业务层应优先校验参数合法性。229 收藏 -
 RedisPub/Sub不适合生产实时报警系统,因其消息零持久化、无消费确认与重试机制,订阅者断线或处理失败即导致报警永久丢失。227 收藏
RedisPub/Sub不适合生产实时报警系统,因其消息零持久化、无消费确认与重试机制,订阅者断线或处理失败即导致报警永久丢失。227 收藏 -
 必须同时排除RedisAutoConfiguration和RedisRepositoriesAutoConfiguration,否则因后者依赖redisTemplate而启动失败;exclude参数需传入Class数组,配置文件中须正确书写全限定名并避免缩进错误,且需清理残留Redis属性和手动Bean。227 收藏
必须同时排除RedisAutoConfiguration和RedisRepositoriesAutoConfiguration,否则因后者依赖redisTemplate而启动失败;exclude参数需传入Class数组,配置文件中须正确书写全限定名并避免缩进错误,且需清理残留Redis属性和手动Bean。227 收藏 -
 RedisLua脚本需用原子“读-判-写”实现状态变迁,推荐HASH结构存储多字段(如status、updated_at、version),通过HGETALL/HSET原子操作,结合redis.call("TIME")获取时间戳、INCR或version校验防越级跳转,返回结构化结果便于业务判断。224 收藏
RedisLua脚本需用原子“读-判-写”实现状态变迁,推荐HASH结构存储多字段(如status、updated_at、version),通过HGETALL/HSET原子操作,结合redis.call("TIME")获取时间戳、INCR或version校验防越级跳转,返回结构化结果便于业务判断。224 收藏 -
 Redis客户端重连易打挂新主库,因默认“失败即重试”导致连接风暴;需配置指数退避+随机抖动(如Lettuce用ExponentialBackoffRetry.withJitter)、Go端自定义DialContext重试逻辑,并控制初始延迟50–100ms、最大延迟≤3s、重试8–12次。223 收藏
Redis客户端重连易打挂新主库,因默认“失败即重试”导致连接风暴;需配置指数退避+随机抖动(如Lettuce用ExponentialBackoffRetry.withJitter)、Go端自定义DialContext重试逻辑,并控制初始延迟50–100ms、最大延迟≤3s、重试8–12次。223 收藏