-

如何利用Redis实现分布式消息发布与订阅引言:在分布式系统中,消息发布与订阅是一种常见的通信模式,可以实现不同模块之间的解耦。Redis作为一种高性能的键值对存储系统,可以用来实现分布式消息发布与订阅功能。本文将介绍如何使用Redis来实现这一功能,并提供具体的代码示例。一、Redis的发布与订阅功能Redis的发布与订阅功能是基于消息队列的一种实现方式。
-

能,BITPOS返回第一个值为1的bit位偏移量(从0开始),需结合写入时的时间粒度和起始时间换算为真实时间,全0时返回-1。
-

安全更新Redis配置参数的步骤包括:1)备份Redis数据库和配置文件;2)使用CONFIGSET命令动态更新配置参数;3)编辑配置文件并重启服务更新不支持动态修改的参数;4)更新安全相关参数如requirepass和bind;5)合理配置参数并考虑版本兼容性;6)进行充分的测试和验证,确保系统运行正常。
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-

开启和查看Redis的安全审计日志需要编辑redis.conf文件,将appendonly设置为yes,并定义日志文件名。查看日志可通过读取AOF文件。1.编辑redis.conf,设置appendonlyyes和appendfilename。2.使用catappendonly.aof查看日志。定期管理AOF文件并确保其安全性是必要的。
-
具体如下:一、聊聊什么是硬编码使用缓存?在学习SpringCache之前,笔者经常会硬编码的方式使用缓存。我们来举个实际中的例子,为了提升用户信息的查询效率,我们对用户信息使用了缓存,示例代码如下:@AutowireprivateUserMapperuserMapper;@AutowireprivateRedisCacheredisCache;//查询用户publicUsergetUserById(LonguserId){//定义缓存keyStringcacheKey="userId_"+userId;/
-

RedisPub/Sub不直接产生内存碎片,但未清理的订阅连接、消息积压或缓冲区配置不当会推高used_memory_rss,导致mem_fragmentation_ratio偏高,形成“假性碎片”;真实碎片源于键值对频繁增删改,而Pub/Sub缓冲区不受active-defrag影响。
-

SINTER是Redis中计算共同好友唯一靠谱、原子、高效的方式,它基于内存集合运算,自动选取最小集合优化性能,毫秒级返回结果,避免网络往返与客户端计算开销。
-

如何为Redis设置强密码和访问控制?通过以下步骤实现:1.在redis.conf中设置强密码,使用requirepass命令;2.启用绑定地址,使用bind命令限制访问;3.配置ACL,创建用户和权限,确保只有授权用户访问。通过这些措施,可以有效保护Redis数据库的安全。
-

需要关注Redis的版本更新,因为它能带来性能提升、安全补丁和新功能。检查Redis版本是否需要升级的步骤包括:1.使用命令“redis-cli--version”查看当前版本;2.与Redis官方版本对比;3.评估新功能、性能提升、安全补丁和兼容性;4.遵循备份数据、测试环境、逐步升级和监控日志的最佳实践。
-
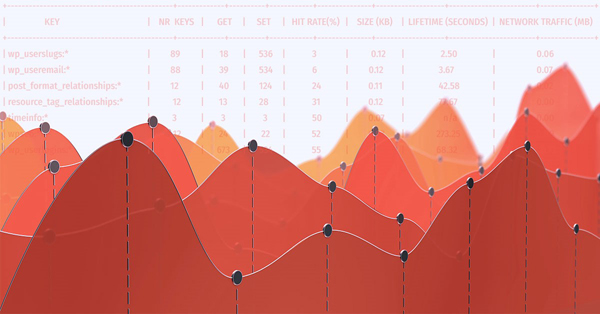
【golang学习网.com快译】在我们需要分析Redis实例的内存使用情况时,市场上有着许多免费的开源工具,同时也有少量的付费产品。如果您想更深层次地分析内存相关问题的话,就可能需要用到
-

CLUSTERKEYSLOT仅执行CRC16(key)mod16384计算,返回0–16383的槽号,不查询集群拓扑或节点信息;定位具体实例需配合CLUSTERSLOTS或CLUSTERNODES查找槽所属节点。
-

HLL在处理大数据量统计时的使用技巧包括:1.合并多个HLL以统计多个数据源的UV;2.定期清理HLL数据以确保统计准确性;3.结合其他数据结构使用以获取更多详情。HLL是一种概率性数据结构,适用于需要近似值而非精确值的统计场景。
-

Redis性能瓶颈主要出现在硬件、配置和应用层面。1.硬件层面:内存不足和CPU性能低下可能导致性能问题。2.配置层面:不当的持久化和网络配置会影响性能。3.应用层面:大Key、大Value和不合理缓存策略是常见问题。通过监控和优化,可以有效提升Redis性能。
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。