-

在启动Redis时,可以通过命令行参数--config或-c来指定配置文件,确保Redis使用自定义配置而非默认配置。例如:1.基本用法:redis-server/etc/redis/redis.conf。2.高级用法:在主配置文件中使用INCLUDE指令引入其他配置文件。
-

Redis启动后无法访问的原因主要包括配置文件问题、网络问题、防火墙设置和内存不足。解决方案如下:1.调整配置文件,确保绑定地址和端口正确;2.修复网络连接,确保Redis服务器和客户端连接正常;3.调整防火墙规则,允许Redis端口访问;4.增加内存或调整Redis配置,确保内存充足。
-

Redis和Perl语言开发:构建高效的命令行工具引言:Redis是一个开源的内存数据存储系统,使用C语言编写,具有高性能和灵活的特性,被广泛用于缓存、消息队列和实时分析等场景。Perl是一种脚本语言,具有强大的文本处理和正则表达式功能,非常适合用于快速开发命令行工具。本文将介绍如何使用Perl语言和Redis构建高效的命令行工具,并且提供相关的代码示例。一
-

如何利用Redis和C#实现分布式数据分片功能分布式计算已成为现代计算机系统中普遍的需求。而数据分片是实现分布式计算的关键技术之一。本文将介绍如何利用Redis和C#来实现数据分片功能。Redis是一个基于内存的数据结构存储系统,具有高性能和可靠性。而C#是一种常用的面向对象编程语言,适用于开发各种类型的应用程序。在分布式系统中,分片是将数据划分为多个部分的
-

redis-full-check的使用背景
在经历了之前的文章内容章节内容,已完成Redis迁移后,可能会存在以下问题需要进行数据迁移之后的对比。例如,如果Redis迁移的过程出现异常,源端与目的端Redis的数
-

Redis集群是没法执行批量操作命令的,如mget,pipeline等。这是因为redis将集群划分为16383个哈希槽,不同的key会划分到不同的槽中。但是,Jedis客户端提供了计算key的slot方法,已经slot和节点
-
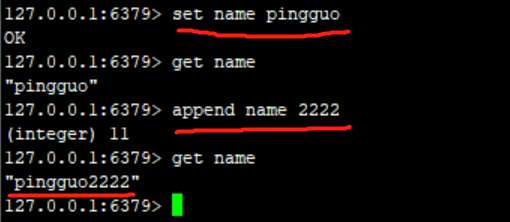
Redis数据类型String操作命令
一、append 追加字符串
append name 2222
二、strlen 获取key 字符串长度
strlen name
三、自增、自减
文章浏览量,点赞可以用这种实现。
incr agedecr age
注意这里得是数字才可
-

SpringBoot中@Cacheable不支持动态过期时间,因SpringCache抽象层仅支持全局TTL配置;需通过RedisTemplate手动设expire、多CacheManager配置或自定义RedisCacheWriter实现差异化TTL。
-

redis-cli--clusterfix并非万能修复器,仅解决Slot被多节点声明的明确冲突,对Slot丢失、元数据错乱、nodes.conf未刷新等问题无效;它只比对并修正冲突项,不处理“看似合理实则失效”的条目。
-

Redis在高并发环境下的性能调优可以通过以下步骤实现:1.内存管理:使用maxmemory和maxmemory-policy配置,建议使用allkeys-lru策略。2.网络I/O优化:调整tcp-backlog和client-output-buffer-limit配置。3.持久化优化:调整rdb和aof的配置,平衡性能和数据安全。4.集群和分片:使用RedisCluster或Codis分散数据。5.客户端优化:使用连接池和批处理命令如pipeline或mget/mset。通过这些措施,可以确保Redi
-

要分析Redis的性能瓶颈,首先应监控关键指标,包括CPU使用率、内存使用率、网络I/O、命中率和慢查询日志。1.监控关键指标是性能分析的第一步,通过redis-cliinfo或第三方工具如Prometheus+Grafana获取数据。2.使用redis-cli--latency检测Redis延迟,帮助识别服务器响应时间异常。3.分析慢查询日志可揪出执行效率低的命令,通过CONFIGSET开启日志并用SLOWLOGGET查看记录。4.剖析Redis命令细节,利用COMMANDINFO分析命令复杂度与执行时
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。
-

要查看Redis的连接状态和连接数,可以使用以下方法:1.使用INFO命令,输入“redis-cliINFOclients”查看基本连接信息;2.使用CLIENTLIST命令获取更详细的连接列表。通过这些命令,可以监控Redis的连接情况,优化性能。
-

如何利用Redis实现分布式消息发布与订阅引言:在分布式系统中,消息发布与订阅是一种常见的通信模式,可以实现不同模块之间的解耦。Redis作为一种高性能的键值对存储系统,可以用来实现分布式消息发布与订阅功能。本文将介绍如何使用Redis来实现这一功能,并提供具体的代码示例。一、Redis的发布与订阅功能Redis的发布与订阅功能是基于消息队列的一种实现方式。
-

能,BITPOS返回第一个值为1的bit位偏移量(从0开始),需结合写入时的时间粒度和起始时间换算为真实时间,全0时返回-1。