-

在Python中,pi指的是数学常数π。使用方法:1)从math模块导入π;2)用于计算圆的面积和周长;3)在三角函数中以弧度计算;4)在统计学和概率计算中应用。使用π时需注意精度、性能和代码可读性。
-

在Python中操作数据库可以使用SQLAlchemy或Psycopg2等库。1)使用mysql-connector-python库连接MySQL数据库,执行查询并打印结果。2)使用SQLAlchemy进行ORM操作,定义模型类映射数据库表,进行增删查改操作。选择合适的数据库操作方式需考虑项目规模、性能需求和团队技能。
-

break和continue在编程中用于控制循环流程。1.break用于立即终止循环,如查找特定元素时。2.continue用于跳过当前循环的剩余部分,继续下一次迭代,如打印奇数时。合理使用它们能提升代码效率和清晰度。
-

使用Python进行Web开发可以选择Flask、Django和FastAPI等框架。1.Flask适合小型项目,易于上手。2.Django适用于大型项目,功能全面。3.FastAPI适用于高性能需求,基于异步编程。
-

在Django中实现分词搜索的技术探讨在我们进行全文搜索时,常常会遇到如何将用户输入的查询词进行分词并实现...
-

python获取response不到正确内容,如何解决?在使用Python的requests...
-

介绍ble-lock-session是一个简单的python工具,它使用蓝牙根据设备(例如智能手机或智能手表)的接近程度自动锁定或解锁计算机。它的创建是为了给日常计算机使用带来一定程度的自动化,以最少的硬件要求轻松保护您的环境。在本文中,我们将研究ble-lock-session的工作原理、其底层设计,以及一些可以将其功能扩展到基本锁定/解锁机制之外的有趣方法。什么是ble-lock-session?ble-lock-session是一个基于python的工具,它与系统的蓝牙堆栈交互,以确定附近是否有配对
-

将文件打开方式关联到自定义程序问题:如何在Python...
-

维姆...
-

从零入门Python和机器学习:开拓学习之路初次接触Python...
-

在Python程序中,注释常常被用于说明代码的逻辑,功能和特点,帮助后续的程序员们快速了解代码的意图和实现细节。但是,在实际编码中,有时候注释的质量不高,或者不规范,可能会导致一些问题,影响编码效率和程序的可读性和可维护性。那么,如何解决Python的代码中的注释不规范错误呢?在本文中,我们将对这一问题进行分析和探讨,提出一些实用的解决方案。一、什么是注释错
-

PyInstaller是一款适用于python程序的强大打包工具,它能够将Python脚本编译成独立的可执行文件,从而无需安装Python解释器即可在各个平台上运行。本文将深入探索PyInstaller的特性,并通过代码示例展示其使用方式,带你领略Python程序千里奔袭的异界传送术。一、PyInstaller的安装PyInstaller的安装非常简单,通过pip命令即可完成:importtkinterastkroot=tk.Tk()root.title("HelloWorld")root.mainloo
-

提高工作效率:掌握pip指令的高级用法,需要具体代码示例在日常的工作中,我们经常会使用到Python进行开发和数据分析。而使用Python进行开发过程中,安装和管理第三方库是必不可少的一环。而pip是Python的包管理工具,能够方便地安装、卸载和更新各种Python包。虽然大部分人都熟悉pip的基本用法,但是掌握pip的高级
-

让PyCharm适应你的需求:如何调整中文界面设置,需要具体代码示例随着Python的广泛应用和发展,PyCharm成为了许多Python开发者的首选集成开发环境(IDE)。PyCharm提供了丰富的功能和工具,使得开发工作更加高效和愉悦。对于中国开发者来说,一个中文界面将更加方便日常使用。本文将介绍如何调整PyCharm的界面设置为中文,并提供一些具体的代
-
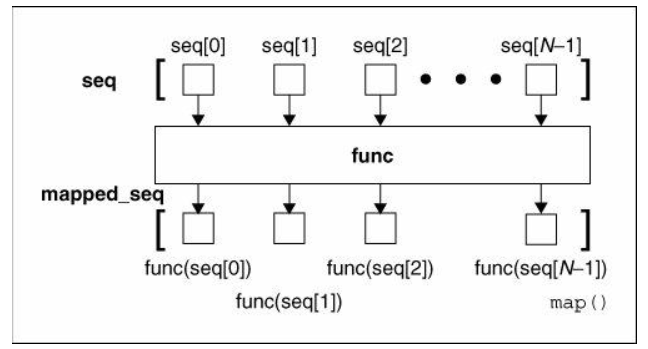
本文对Python中的函数式编程技术进行了简单的入门介绍。头等函数在Python中,函数是「头等公民」(first-class)。也就是说,函数与其他数据类型(如int)处于平等地位。因而,我们可以将函数赋值给变量,也可以将其作为参数传入其他函数,将它们存储在其他数据结构(如dicts)中,并将它们作为其他函数的返回值。把函数作为对象由于其他数据类型(如string、list和int)都是对象,那么函数也是Python中的对象。我们来看示例函数foo,它将自己的名称打印出来:def