-

如何在Python中将代码存储到变量中在编程中,您可能会遇到需要重复使用特定代码段的情况。在Python中,您可以...
-

在我的个人项目hypergraph中与循环依赖进行斗争之后,我最终决定正面解决这个技术债务。随着代码库的扩展,这个问题变得越来越明显,使得维护和测试变得越来越困难。今天,我想分享为什么我选择实施全面的架构改革以及这个新实施解决了什么问题。问题当我第一次开始开发hypergraph时,我专注于让功能快速运行。这导致了一些仓促的架构决策,这些决策起初看起来不错,但随着项目的发展开始出现问题。最重要的问题是:核心模块之间的循环依赖组件之间的紧密耦合困难的测试场景复杂的初始化链关注点分离不佳当我尝试实现一个新的插
-
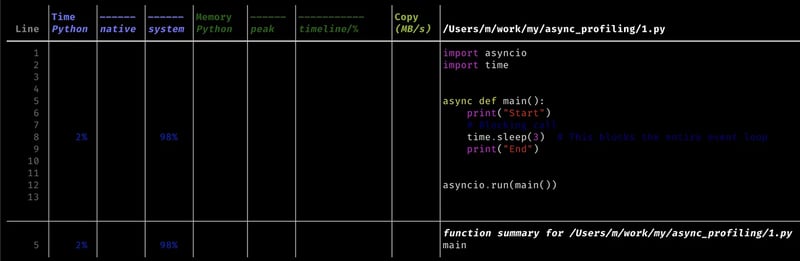
介绍应用程序分析是一个分析程序以确定其特征的过程:执行时间不同的代码零件和资源用法。分析的主要阶段总是或多或少相同的:测量执行时间。执行不同的代码零件需要多少时间?分析内存使用。程序的不同部分消耗了多少内存?识别瓶颈。代码的哪些部分减慢了程序或使用太多资源?>>性能优化。采取措施根据获得的数据提高执行速度和资源利用效率。有限数量的异步代码的特定瓶颈。让我们将每种类型与代码示例匹配。>-异步python中的瓶颈的主要类型
-

Python实现语音识别工具的不同技术方案:深度剖析与实践很多开发者都想过构建一个属于自己的语音识别工具,这听起来很酷,对吧?但实际操作中,你会发现选择合适的技术方案至关重要,它直接影响着你的工具的准确率、效率,甚至最终的易用性。这篇文章,我们就来深入探讨几种Python实现语音识别的技术方案,并分享一些我在开发过程中遇到的坑以及解决方法。技术选型与权衡语音识别并非一蹴而就,它依赖于一系列技术,从音频处理到语言模型,每个环节都潜藏着挑战。目前主流方案大致可以分为基于云服务的和本地方案。云服务方案,比
-

高效处理Web请求和大量Socket连接的Python框架选择本文探讨如何在Python中同时高效地处理Web请求和大量的Socket长连...
-

Python动态创建对象并调用方法的实现在Python开发中,我们经常会遇到需要根据字符串动态创建对象并调用其方法...
-

关于在Docker容器中自动激活Python虚拟环境的探讨许多开发者在使用Docker部署Python...
-

MacBookAir的触控板和快捷键可以通过以下步骤提升操作效率:1.掌握触控板手势,如三指轻扫和两指轻点,逐渐增加复杂度并自定义设置。2.熟练使用快捷键,如Command+C/V/Tab,多练习并自定义设置。3.合理使用功能以优化性能,调整灵敏度和减少不必要的快捷键使用,定期清理系统垃圾。
-

Python代码的基本结构包括模块、函数、类、语句和表达式。1.模块是代码组织的基本单位。2.函数是可重用的代码块,用于执行特定任务。3.类定义对象的属性和方法,支持面向对象编程。4.语句和表达式是代码的基本执行和计算单位。
-

如何在Python、Java和JavaScript中实现数据的格式化输出?1.Python使用format方法或f-strings进行基本和高级格式化输出。2.Java通过System.out.printf和String.format实现格式化输出。3.JavaScript使用模板字符串和padStart/padEnd方法进行格式化输出。
-

在Python中,高效为多行代码添加井号注释的方法包括:1.使用代码编辑器的快捷键,如VSCode的Ctrl+/或Cmd+/;2.使用Python的多行字符串作为注释;3.结合快捷键和多行字符串注释,以提高代码的可读性和可维护性。
-

Python的特点包括简洁、易读、高效、解释型和面向对象。1)简洁和易读的语法使开发更高效。2)动态类型系统提供灵活性,但可能导致运行时错误。3)丰富的标准库减少对第三方库的依赖。4)解释型特性导致性能劣势,但可通过Cython和Numba优化。5)庞大的社区和生态系统提供丰富资源,但选择过多可能导致困难。
-

<p>在Python中定义函数使用def关键字,后跟函数名和参数列表,函数体需缩进,可选返回值。1.基本定义:defgreet(name):returnf"Hello,{name}!".2.默认参数:defgreet(name,greeting="Hello"):returnf"{greeting},{name}!".3.不定长参数:defprint_args(args,kwargs):forarginargs:print(f"Positionalargument:{arg}");forkey
-

在Python中重命名文件可以使用os模块中的rename函数。具体步骤包括:1)导入os模块,2)使用os.rename('old_name.txt','new_name.txt')重命名文件。为了处理文件不存在和文件名冲突等情况,可以编写更健壮的代码,包括检查文件存在性和处理异常。
-

sort()方法和sorted()函数的主要区别是:1.sort()直接在原列表上进行排序,2.sorted()返回一个新的排序列表,不影响原列表。使用key参数可以实现自定义排序规则,适用于复杂对象排序。