-
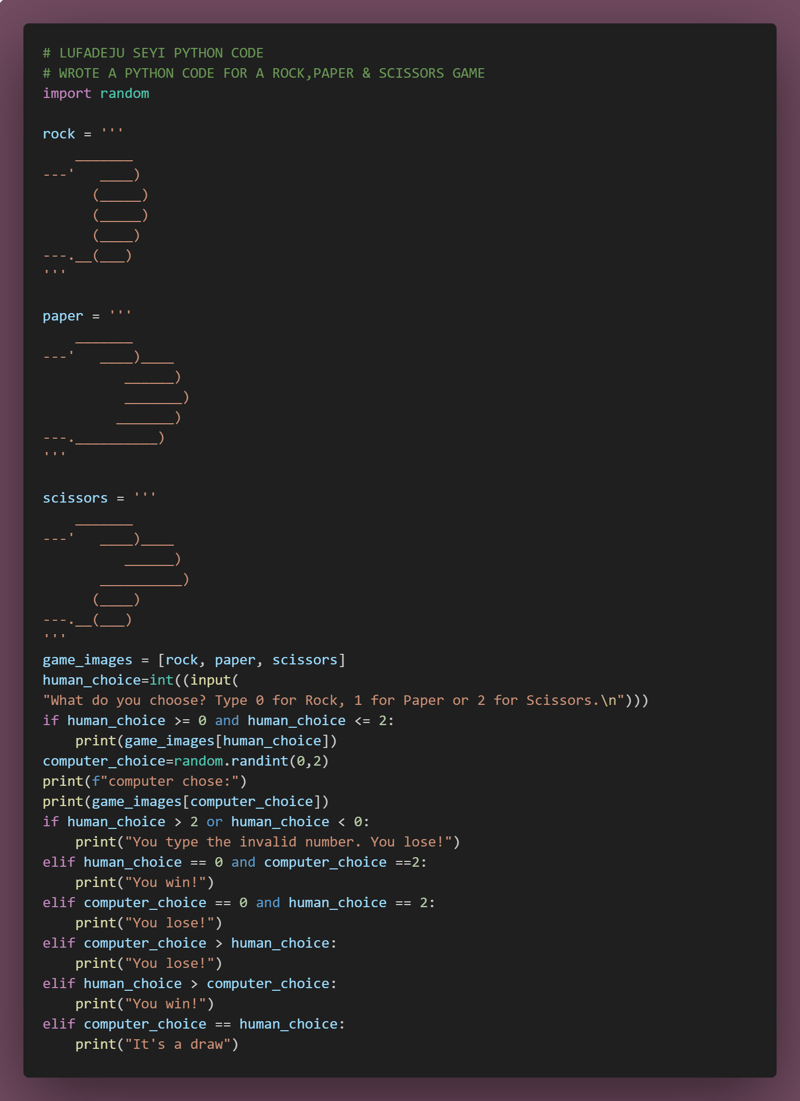
用Python轻松创建石头剪刀布游戏Python语言的灵活性和易用性使其成为开发简单而有趣游戏的理想选择。本文将指导您使用Python创建经典的石头剪刀布游戏。无论您是编程新手还是寻求有趣项目的老手,都能轻松上手。第一步:游戏规则石头剪刀布的游戏规则很简单:石头胜剪刀剪刀胜布布胜石头玩家从石头、剪刀、布三个选项中选择一个,根据以上规则判断胜负。第二步:代码结构游戏主要包含以下几个部分:玩家输入:玩家选择石头、剪刀或布。电脑选择:电脑随机选择石头、剪刀或布。胜负判定:比较玩家和电脑的选择,确定胜负。第三步:
-

去掉打印字典时的空行打印字典时,可能会出现不必要的空行。如果你想去掉这些空行,可以按照以下步骤操作...
-

判断文本是否为简体中文判断文本是否为简体中文,可以使用正则表达式来匹配中文汉字。正则表达式...
-

编程中的字符串a=“你好”b="阿维纳什"打印(a,b)a="我的名字是阿维纳什"打印(一)a="""我叫Avinash.我来keeramangalam,str(年龄(19)"""打印(一)a="阿维纳什"打印(a[4])a=“阿维纳什”打印(len(a))txt="印度最美丽的人"print(txt中的“印度”)修改字符串a="你好世界"打印(a.upper())小写a="你好世界"打印(a.lower())替换字符串a="你好世界"print(a.replace("h","r"))条带a="你好世界"
-

最初由lizacosta发表在streamlit博客上还记得第一次使用人工智能图像生成器有多酷吗?那两千万根手指和噩梦般的吃意大利面的画面不仅仅是有趣,它们在不经意间透露了哎呀!人工智能模型的智能程度与我们一样。和我们一样,他们也很难画手。人工智能模型很快变得更加复杂,但现在的模型数量太多了。而且,和我们一样,他们中的一些人比其他人更擅长某些任务。以文本生成为例。尽管llama、gemma和mistral都是法学硕士,但他们中的一些人更擅长生成代码,而另一些人则更擅长头脑风暴、编码或创意写作。根据提示,它
-

移动应用程序已经成为了人们日常生活中必不可少的一部分。而Python作为一种高级编程语言,广泛应用于Web开发、机器学习、数据分析等领域,Xamarin则是一款跨平台移动应用开发框架,能够使用C#和.NET开发Android和iOS应用程序。这篇文章将介绍如何使用Python和Xamarin构建移动应用程序。准备工作在开始之前,您需要安装以下软件:Pytho
-

python中的自然语言处理(NLP)模型的性能测量对于评估模型的有效性和效率至关重要。以下是用于评估NLP模型准确性和效率的主要指标:准确性指标:精度(Precision):衡量模型预测为正类的样本中,实际为正类的比例。召回率(Recall):衡量模型预测的所有实际正类样本中,被模型预测为正类的比例。F1得分:精度和召回率的加权平均值,提供了一个衡量模型整体准确性的指标。准确率(Accuracy):衡量模型预测的所有样本中,正确预测比例。混淆矩阵:显示模型预测的实际值和预测值,用于识别假阳性和假阴性。效
-

SORT(SimpleOnlineandRealtimeTracking)是一种基于卡尔曼滤波的目标跟踪算法,它可以在实时场景中对移动目标进行鲁棒跟踪。SORT算法最初是由AlexBewley等人在2016年提出的,它已被广泛应用于计算机视觉领域的各种应用中,例如视频监控、自动驾驶、机器人导航等。SORT算法主要基于两个核心思想:卡尔曼滤波和匈牙利算法。卡尔曼滤波是一种用于估计系统状态的算法,它可以利用系统的动态模型和传感器测量值,对系统状态进行预测和更新,从而提高状态估计的准确性。匈牙利算法是一种用于解
-

简单易懂的pip安装命令教程,需要具体代码示例1.简介pip是Python的官方包管理工具,可以方便地安装、升级和管理Python的第三方库。本文将介绍pip的安装方法和常用命令,以及一些常见问题的解决方案。2.安装pip2.1确认Python版本在安装pip之前,需要确认Python是否已安装。打开终端或命令行窗口,输入以下命令确认Python的版本
-

深入了解Django的模板引擎和Flask的Jinja2,需要具体代码示例引言:Django和Flask是Python中两个常用且流行的Web框架。它们都提供了强大的模板引擎来处理动态网页的渲染。Django使用自己的模板引擎,而Flask使用Jinja2。本文将深入了解Django的模板引擎和Flask的Jinja2,并提供一些具体的代码示例来说明它们的用
-
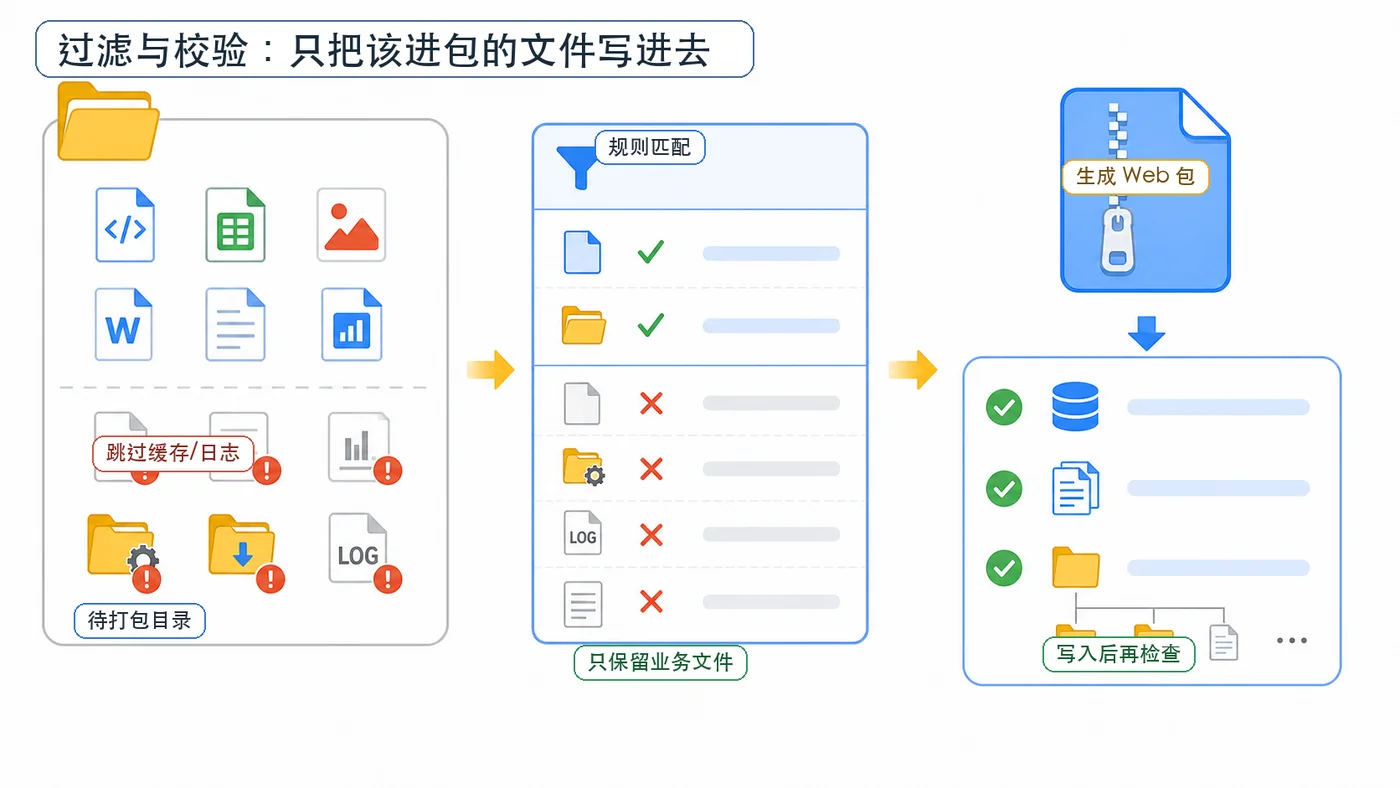
用 Python 标准库 zipfile 做一个可靠的批量打包脚本:遍历源目录、保留相对路径、跳过缓存和日志文件,写入压缩包后再校验文件数量、路径和 CRC 结果。
-

直接选择Python3.10及以上版本最合适,因其性能更强、语法更现代、错误提示更清晰;Python2已停止维护,资源不兼容且存在安全隐患;推荐安装python.org提供的最新稳定版如Python3.12,并通过python--version验证版本。
-

request.endpoint返回当前请求匹配的视图端点名,由路由注册时指定,默认为函数名;蓝本下带前缀,手动指定则完全无关函数名;None表示未匹配路由或不在请求上下文。
-

本文介绍如何使用Pandas精确提取「仅当首个满足布尔掩码的行位于前N行内」时对应的值,否则统一设为NaN;核心在于结合索引范围约束与首次命中逻辑,避免cumsum().eq(1)的全局匹配缺陷。
-

Plotly是Python中制作交互式图表最实用的工具之一,支持离线使用、HTML导出、Dash集成及动态筛选;三行代码即可运行,交互功能默认开启,悬停、缩放、平移等内置,动画与多子图联动便捷,嵌入网页或导出分享轻量可靠。