-
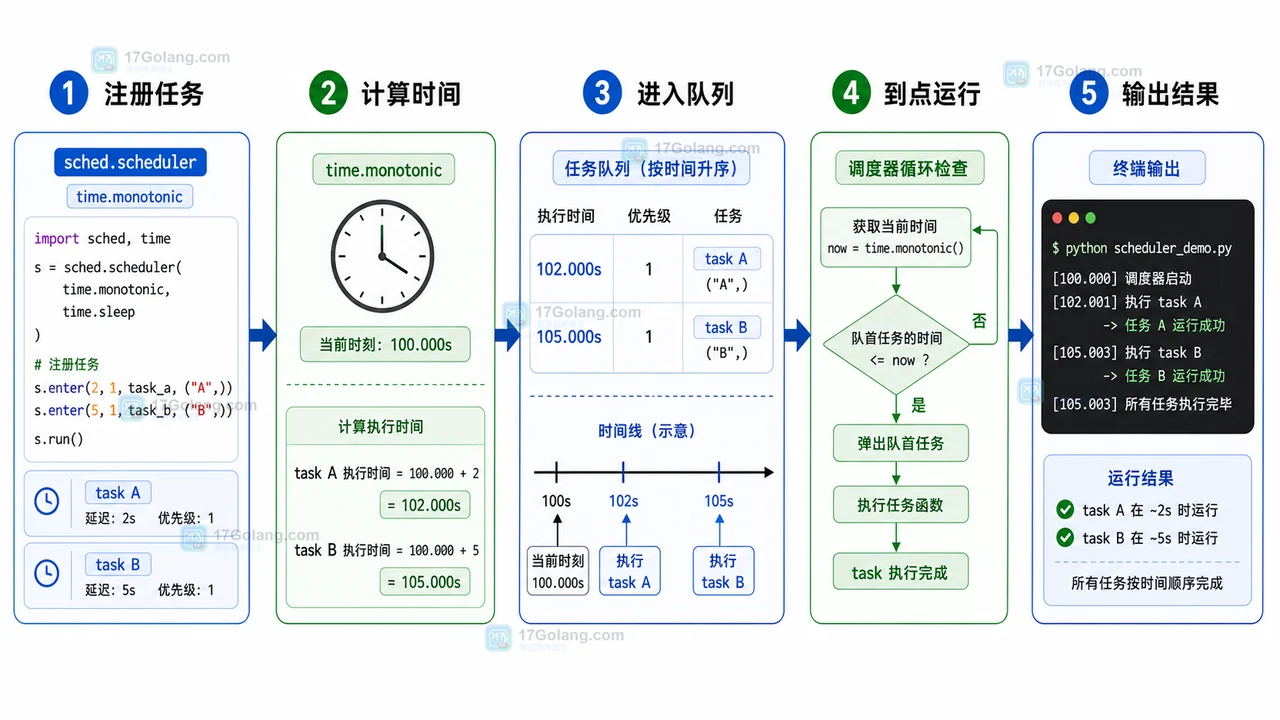
用 Python 标准库 sched 做一个本地轻量定时任务实验,覆盖任务注册、轮询运行、周期任务、失败重试、运行检查和清理边界,适合小脚本和本地自动化场景。
-

剪枝本身不减模型体积,必须strip_pruning+h5导出才能看到磁盘大小下降:因PolynomialDecay仅加掩码,保存仍为稠密格式;strip_pruning移除mask后用h5保存,才利用零值压缩实现40–60%体积下降。
-

Python中取消异步任务需调用Task.cancel()触发协作式取消,协程必须在await点响应CancelledError并重抛,否则取消无效;纯CPU计算或阻塞IO需转为异步执行以支持取消。
-

大规模文本预处理需先解决内存与分词问题:用生成器+tf.data避免OOM,轻量分词器优先,合理设vocab_size、output_dim及trainable,转TFRecord提升I/O性能,并用padded_batch确保静态shape。
-

__enter__和__exit__必须成对出现,因为with语句依赖二者驱动:进入时调__enter__,退出时无条件调__exit__(含异常);缺一则报AttributeError,且__exit__四参数不可少,返回True可抑制异常。
-

按频次降序排应调用most_common()方法,它返回(key,count)元组列表,全量排序用most_common(),TopN用most_common(k),比sorted(counter.items(),key=lambdax:x[1],reverse=True)更高效且语义明确。
-

生成器抛异常后立即终止迭代;需用try/except内部捕获异常才能继续yield;throw()可外部注入异常并由生成器处理;StopIteration后生成器永久关闭不可重用。
-

目标跟踪模型通常基于预训练检测器构建,采用“检测+关联”两阶段结构,而非端到端训练;主流方案如ByteTrack用YOLO检测加双阈值关联,训练时检测、ReID、关联超参分步优化。
-

文本分类在PythonWeb开发中需注重数据清洗、特征对齐与接口封装。应使用标注数据(如客服留言)划分训练/测试集,TF-IDF+LogisticRegression为首选模型,FastAPI封装接口并限流日志,确保稳定高效落地。
-

Python支持动态添加实例和类属性,实例属性仅影响当前对象,类属性影响所有实例;使用__slots__会限制实例属性添加;直接操作__dict__存在风险,不推荐常规使用。
-

在Python中高效操作Parquet文件的方法包括:使用Pandas配合pyarrow或fastparquet引擎读写文件,适用于小规模数据;面对大规模数据时采用PyArrow模块实现按列或分块读取;优化存储效率可通过设置行组大小、选择压缩算法、按字段分区排序以及避免频繁写入小文件等方式实现。
-

dis.dis()输出空或极简指令常见原因包括传入未编译对象、lambda被优化、函数体为空/仅注释,以及Python3.12+的快速常量折叠;实操需确认目标为可访问函数对象,用__wrapped__解包装饰器,拆分运算式以观察过程,类方法须传绑定或未绑定对象。
-

“badmagicnumber”通常因环境干扰导致,如LVM未激活、LUKS未解密、分区路径错误或设备非XFS格式;需先用xfs_db或hexdump验证超级块魔数0x58465342,再排除三类干扰,最后才考虑重建。
-

本文详解如何通过设置关键请求头(User-Agent和Accept-Language)并配合流式下载,成功获取ADGM等严格防护网站上的PDF文件,避免文件损坏或403/406错误。
-

Python文件操作核心是打开、读写、关闭;用open()指定路径和mode(如'r'只读、'w'写入、'a'追加),推荐with语句自动管理资源,注意encoding防乱码,write()写字符串、writelines()写列表,解析文本常用strip()、split()等方法。