-

阿帕奇冰山101apache冰山实践介绍免费apacheiceberg速成课程apacheiceberg的免费副本:权威指南使用dbt时,您可以使用的最强大的功能之一是宏。宏允许您编写可在整个dbt项目中使用的可重用代码,帮助您优化开发、减少冗余并标准化常见模式。在这篇文章中,我们将探讨dbt宏的用途、它们如何帮助您简化数据转换工作流程以及如何有效地使用它们。什么是dbt宏?在较高的层面上,dbt宏是用jinja(一种集成到dbt的模板语言)编写的可重用代码片段。宏的作用类似于函数,您可以在dbt项目中的
-

pydantic的Anyurl方法返回格式类型pydantic库中的Anyurl方法用来验证和处理URL。在某些情况下,该方法可能返回None值�...
-

Go语言采用晚绑定的原因及其解决方法在Go语言中,当我们使用空数组存储类型为void->int...
-

Python解码字符串在Python中,使用encode()和decode()方法进行编码和解码非常常见。encode()...
-

Python的shelve模块shelve模块提供了一个类似于字典的持久化数据结构,允许将对象存储在文件中。在shelve...
-
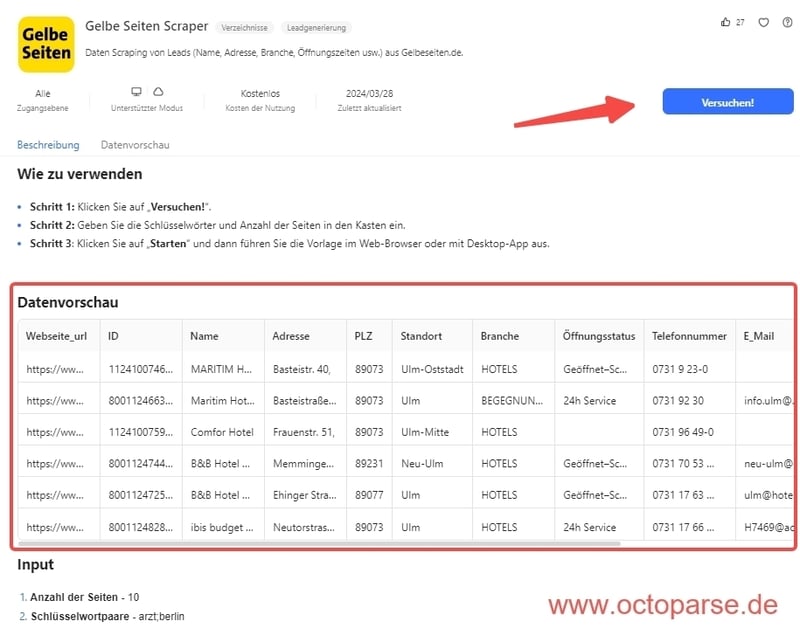
在本文中,您将学习如何在没有任何编程知识的情况下抓取电话号码、传真号码、网站、营业时间和地址等潜在客户数据。即使是初学者也可以轻松创建黄页抓取工具。从黄页可以获取哪些信息?从黄页中可以获得很多与业务相关的信息,这对于营销、销售和市场研究特别有用。典型信息包括:公司名称:公司名称或品牌名称。地址:详细地址,包括城市、街道和邮政编码。联系信息:电话号码、电子邮件地址,有时还有传真号码。网站URL:如果有,请链接到公司网站。行业和类别:根据行业和活动领域对公司进行分类。营业时间:有空时的营业时间。评级和评论:客
-

嘿,我目前正在开发一个用python编写的开源网络安全和密码学存储库,它位于github上。此仓库目前有多种功能:异或运算。简洁的ECB加密/解密功能。简洁的CBC加解密功能。还有一个很酷的功能,让你玩得开心。我目前正在研究CTR功能。此存储库当前是一个python库,但我也想用C编程语言编写此存储库。
-

如何选择pip和pip3来管理Python包?在Python的世界里,有许多不同的包管理工具可供选择。其中最常用的两个是pip和pip3。那么,如何选择使用哪个工具来管理Python包呢?本文将为您详细介绍如何根据您的需求来选择使用pip还是pip3,并提供具体的代码示例供参考。首先,让我们来了解一下pip和pip3的区别。pip是Python2.x版本的
-

字典是Python提供的一种常用的数据结构,它用于存放具有映射关系的数据。是一种可变容器模型,且可存储任意类型对象。字典是一个无序、可变和有索引的集合。在Python中,字典用花括号编写{},拥有键值对即key和value组成,字典的每个键值对用冒号:分割,每个键值对之间用逗号,分割。字典中的键具有唯一性,如果键重复,则后边的键对应的值会把前面键对应的值替换掉,值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组都可以为字典的键,但是列表不可以作为key值。eg:dict1={
-

近年来,随着机器学习和人工智能技术的迅猛发展,语音识别技术也取得了突破性的进展。在众多的语音识别工具中,Python作为一种高效、灵活且易于使用的编程语言,在语音识别领域中表现出色,为该领域带来了许多创新和突破。首先,Python在语音信号处理方面发挥了重要的作用。语音信号处理是语音识别的基础,它涉及到声音的采集、预处理、特征提取等一系列过程。Python提
-

在Python类相互引用场景中,直接使用未定义的类名作为类型注解会导致MyPy报错(如“Namealreadydefined”)。本文介绍两种标准、兼容且类型安全的解决方案:字符串字面量前向引用和from__future__importannotations。
-

ServerlessFramework多云模板本质是配置抽象层,非跨云运行时:一份serverless.yml仅支持单provider部署,events、resources、provider.role等强绑定字段不可复用,需通过${file()}拆分配置并动态加载。
-

本文介绍两种高效管理Tkinter按钮颜色的方案:一是为每个按钮绑定独立配色逻辑,二是点击任一按钮即批量更新全部按钮背景色,避免重复调用config,提升代码可维护性与扩展性。
-

答案:在Python3中可通过三引号、换行符\n、字符串拼接或textwrap.indent()实现字符串换行与空格添加。1.三引号保留多行原始格式;2.\n配合空格手动控制换行与缩进;3.使用join()动态生成带缩进的多行字符串;4.textwrap.indent()对已有文本统一加缩进,适合批量处理。根据场景选择合适方式即可。
-

PhotoImage原生仅支持GIF/PPM/PGM且不支持缩放,加载PNG/JPEG需Pillow解码并显式resize;必须用Image.LANCZOS重采样、转换RGBA模式、手动管理引用,Canvas需防抖重绘,Label需pack_propagate(False)或改用Canvas。