-

match语句通过字节码级优化和单次结构探测替代链式if判断,减少重复取值与类型检查,在Python3.11+中实现更紧凑分支、更高JIT友好性及实际运行提速。
-

pytest不用BaseTestCase基类,因其依赖fixture而非继承机制;用fixture可精准控制作用域、支持依赖注入和参数化,而BaseTestCase会破坏fixture模型、导致mock和参数化失效。
-

特征工程是目标驱动、业务扎根、隔离严谨、可复现的系统性改造。需明确建模目标反向设计特征,区分缺失与异常的业务含义,合理编码高基数与非结构化字段,并严格时间隔离防止信息泄露。
-
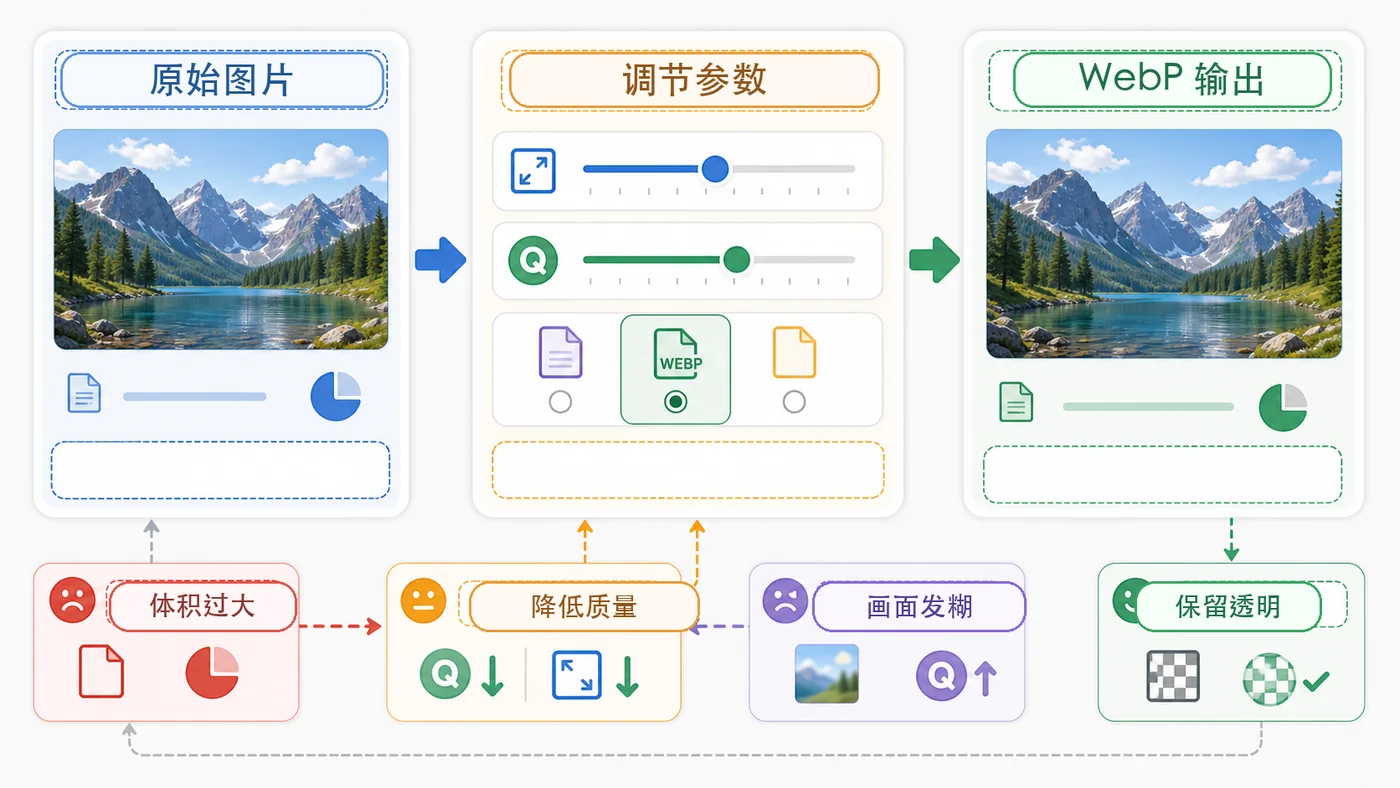
本文用 Python Pillow 实现图片批量压缩:从输入目录读取图片,按最大宽度等比缩放,输出 WebP,并生成压缩清单方便检查体积和清晰度。
-
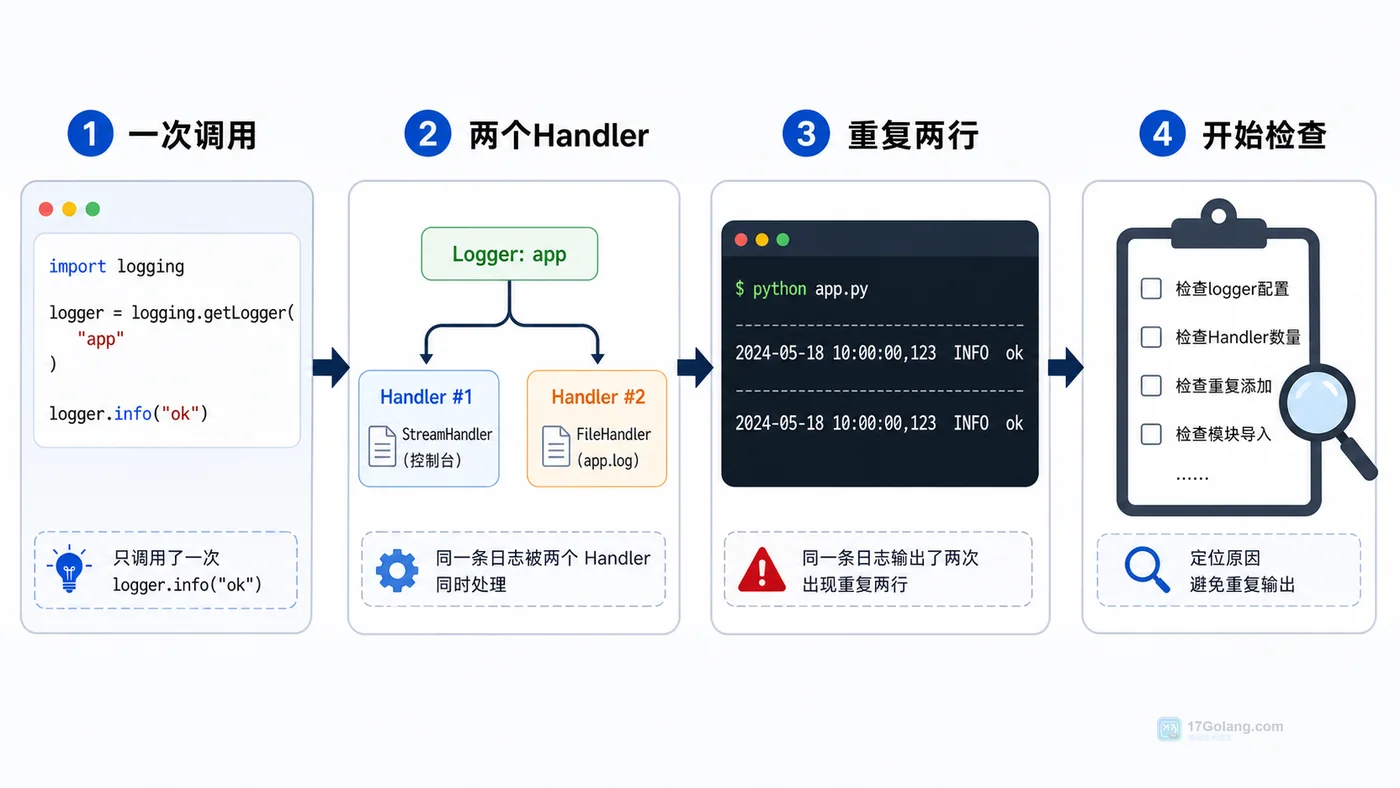
Python 项目里同一条日志重复出现两三次,常见原因是重复 addHandler 或子 logger 向根 logger 继续上抛。本文从复现现象开始,逐步检查 Handler 数量、logger 层级和 propagate 配置,整理一套稳定的日志初始化写法。
-

groupby().head()返回空或结果错误,因它按原始行序取每组前N行而非按指标排序;需先sort_values再groupby().head(),或改用apply(nlargest)并注意NaN、索引、并列处理。
-

Python中可哈希对象需满足“相等对象哈希值相同”且哈希值生命周期内不可变;内置不可变类型(如int、str、tuple)默认可哈希,可变类型(如list、dict)默认不可哈希;自定义类需同时实现__hash__和__eq__方法,并确保参与哈希的属性逻辑不可变。
-

应使用pandas.read_csv的na_values和keep_default_na在读取阶段识别自定义缺失标识;设keep_default_na=False避免误判,配合dtype预声明列类型、fillna的limit/method控制填充边界、dask替代处理超大文件、SimpleImputer实现跨chunk一致填充,并通过业务逻辑校验区分真实缺失与有效标记。
-

最可靠方式是检查响应HTML中是否存在仅登录后才有的特定DOM元素,如<divclass="profile-header">,而非依赖HTTP状态码;若用requests+BeautifulSoup未找到该元素,则登录态已失效。
-

duplicated()默认只标记后续重复行为True,首行为False;用keep=False可标记全部重复行,配合subset可指定列判断重复,需注意NaN、字符串格式和时间精度等预处理。
-

在DjangoCRM系统中,直接删除被估计单、服务报告或发票引用的库存项会导致外键关联断裂,引发页面加载失败;正确做法是通过on_delete参数配置外键行为(如SET_NULL),使历史记录保留完整性,同时逻辑上“下架”该库存项。在DjangoCRM系统中,直接删除被估计单、服务报告或发票引用的库存项会导致外键关联断裂,引发页面加载失败;正确做法是通过`on_delete`参数配置外键行为(如`SET_NULL`),使历史记录保留
-

sort()和rsort()按值排序并重置键;2.asort()和arsort()保持键值关联按值排序;3.ksort()和krsort()按键排序;4.usort()支持自定义排序逻辑。
-

Flask中用@app.errorhandler(404)和@app.errorhandler(500)注册处理函数,返回render_template('404.html'),404;需关闭DEBUG模式、确保模板路径正确且显式返回状态码。
-

真正需解决的是工程化落地问题:setup.py与pyproject.toml选型、旧项目迁移字段修改、pipinstall-e.路径异常、poetryCI超时优化、entry_points键名错误等。
-

Python网页爬虫与数据清洗需分“获取”和“处理”两阶段:爬虫用requests+BeautifulSoup,注意headers、异常捕获和请求频率;提取优先用find/select而非正则;清洗按空值→格式→逻辑三级过滤;落地推荐SQL存储与函数封装。