python教程技术文章
-
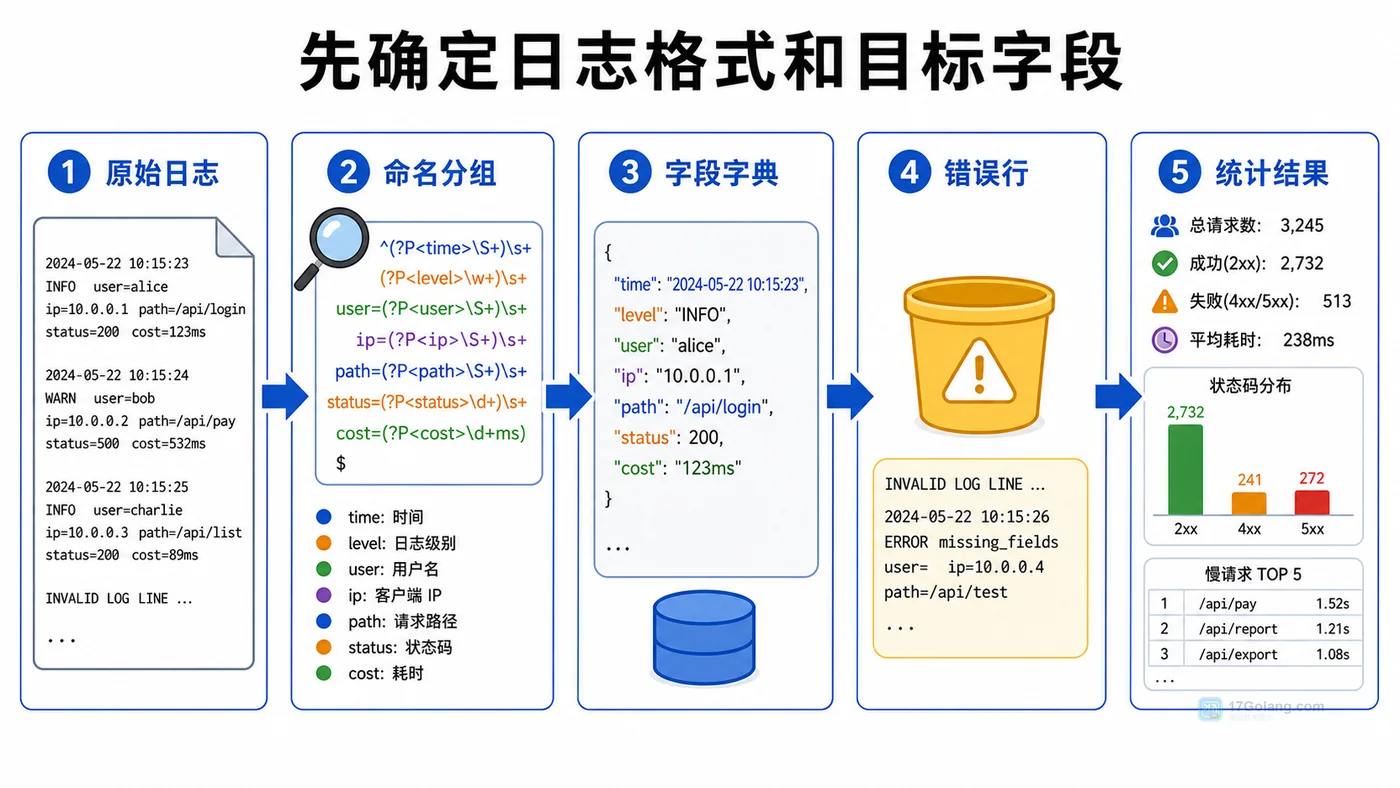 本文用 Python 解析访问日志的场景讲清正则命名分组:如何把原始日志拆成字段字典,如何处理格式不符合预期的错误行,最后统计接口访问次数、状态码分布和慢请求。308 收藏
本文用 Python 解析访问日志的场景讲清正则命名分组:如何把原始日志拆成字段字典,如何处理格式不符合预期的错误行,最后统计接口访问次数、状态码分布和慢请求。308 收藏 -
 os.walk默认不保证深度优先且无缩进逻辑,需手动排序dirs并用递归函数传depth参数控制缩进;推荐pathlib.Path.rglob或iterdir()配合try/except处理权限错误和符号链接。307 收藏
os.walk默认不保证深度优先且无缩进逻辑,需手动排序dirs并用递归函数传depth参数控制缩进;推荐pathlib.Path.rglob或iterdir()配合try/except处理权限错误和符号链接。307 收藏 -
 fillna(method='ffill')用前向最近非空值填充NaN,fillna(method='bfill')用后向最近非空值填充;二者默认按列(axis=0)纵向操作,不改变原非空值,全NaN列填充后仍为NaN。307 收藏
fillna(method='ffill')用前向最近非空值填充NaN,fillna(method='bfill')用后向最近非空值填充;二者默认按列(axis=0)纵向操作,不改变原非空值,全NaN列填充后仍为NaN。307 收藏 -
 ConnectionResetError表明对端主动发送RST断连,常见于长连接空闲超时;需在connect后显式启用TCPKeepalive并调小参数(如Linux设TCP_KEEPIDLE=60秒),同时应用层须实现心跳协议与自动重连机制。307 收藏
ConnectionResetError表明对端主动发送RST断连,常见于长连接空闲超时;需在connect后显式启用TCPKeepalive并调小参数(如Linux设TCP_KEEPIDLE=60秒),同时应用层须实现心跳协议与自动重连机制。307 收藏 -
 Python内置函数开箱即用,重点在于精准巧用:int()需strip()预处理防错,bool()判空规则明确,isinstance()比type()更优;len()适用多种类型但不支持生成器;sorted()可key排序,enumerate()简化带索引循环;all()/any()高效聚合判断。306 收藏
Python内置函数开箱即用,重点在于精准巧用:int()需strip()预处理防错,bool()判空规则明确,isinstance()比type()更优;len()适用多种类型但不支持生成器;sorted()可key排序,enumerate()简化带索引循环;all()/any()高效聚合判断。306 收藏 -
 直接用pika发送任务会丢消息,是因为默认未启用发布确认、队列未持久化、消息未设delivery_mode=2;漏掉任一机制,RabbitMQ重启或消费者异常时消息即丢失。305 收藏
直接用pika发送任务会丢消息,是因为默认未启用发布确认、队列未持久化、消息未设delivery_mode=2;漏掉任一机制,RabbitMQ重启或消费者异常时消息即丢失。305 收藏 -
 根本原因是子进程启动时复用父进程的CUDA上下文或OpenCV等非fork-safe库的全局状态,导致初始化阻塞;典型表现为卡在forbatchindataloader:且无报错。304 收藏
根本原因是子进程启动时复用父进程的CUDA上下文或OpenCV等非fork-safe库的全局状态,导致初始化阻塞;典型表现为卡在forbatchindataloader:且无报错。304 收藏 -
 PolynomialFeatures维度爆炸因生成所有组合项,列数为C(n+degree,degree);实操需控制交互项、标准化、限制输入范围、避免盲目升阶及稀疏矩阵错误。304 收藏
PolynomialFeatures维度爆炸因生成所有组合项,列数为C(n+degree,degree);实操需控制交互项、标准化、限制输入范围、避免盲目升阶及稀疏矩阵错误。304 收藏 -
 本文介绍一种高效、向量化的方法,将DataFrame中某列的值依据其所属的预定义列表组(如tier1、tier2),映射为对应的层级编号(如1、2),并生成新分类列,避免显式循环,适用于数百行数据与十余个分组场景。304 收藏
本文介绍一种高效、向量化的方法,将DataFrame中某列的值依据其所属的预定义列表组(如tier1、tier2),映射为对应的层级编号(如1、2),并生成新分类列,避免显式循环,适用于数百行数据与十余个分组场景。304 收藏 -
 本文介绍如何精准修改Excel表格中任意位置(如A3、B3)的列标题文本,区别于Pandas的列名批量重命名,推荐使用openpyxl直接编辑单元格值,确保原始格式、公式和非结构化布局不受影响。本文介绍如何精准修改Excel表格中任意位置(如A3、B3)的列标题文本,区别于Pandas的列名批量重命名,推荐使用openpyxl直接编辑单元格值,确保原始格式、公式和非结构化布局不受影响。在实际数据处理中,Excel文件的列标题往304 收藏
本文介绍如何精准修改Excel表格中任意位置(如A3、B3)的列标题文本,区别于Pandas的列名批量重命名,推荐使用openpyxl直接编辑单元格值,确保原始格式、公式和非结构化布局不受影响。本文介绍如何精准修改Excel表格中任意位置(如A3、B3)的列标题文本,区别于Pandas的列名批量重命名,推荐使用openpyxl直接编辑单元格值,确保原始格式、公式和非结构化布局不受影响。在实际数据处理中,Excel文件的列标题往304 收藏 -
 直接MockSQLAlchemy模型易失败,因其非可调用对象,真正需Mock的是session实例及其Query链式行为,须让mock支持.filter()等中间调用并仅在.all()等终端方法返回数据。304 收藏
直接MockSQLAlchemy模型易失败,因其非可调用对象,真正需Mock的是session实例及其Query链式行为,须让mock支持.filter()等中间调用并仅在.all()等终端方法返回数据。304 收藏 -
 SettingWithCopyWarning是Pandas提示你可能在修改副本而非原DataFrame,根源在于链式索引不保证可写性;应统一使用df.loc[条件,列]赋值,避免df布尔索引=值。303 收藏
SettingWithCopyWarning是Pandas提示你可能在修改副本而非原DataFrame,根源在于链式索引不保证可写性;应统一使用df.loc[条件,列]赋值,避免df布尔索引=值。303 收藏 -
文章 · python教程 | 1星期前 | 工程化 · 自动化测试 · pytest · CI · 生产实践 · Python教程 · Python CI pytest fixture tmp_path monkeypatch pytest-xdist 测试稳定性
 从 Python 项目 CI 偶发失败入手,讲清 pytest fixture 共享状态、tmp_path 文件隔离、monkeypatch 自动回滚和 xdist 并发验证的实战治理方法。303 收藏
从 Python 项目 CI 偶发失败入手,讲清 pytest fixture 共享状态、tmp_path 文件隔离、monkeypatch 自动回滚和 xdist 并发验证的实战治理方法。303 收藏 -
 Pythonjson模块进阶用法包括:自定义default函数序列化类实例;用object_hook反序列化为对象;ensure_ascii=False保留中文;文件操作需显式指定UTF-8编码;通过parse_float/parse_int等参数增强安全性,禁用eval系函数。302 收藏
Pythonjson模块进阶用法包括:自定义default函数序列化类实例;用object_hook反序列化为对象;ensure_ascii=False保留中文;文件操作需显式指定UTF-8编码;通过parse_float/parse_int等参数增强安全性,禁用eval系函数。302 收藏 -
 Python字符串、列表、字典是协同工作的数据搭档:字符串不可变,需用join或转列表操作;列表可变但注意头部操作性能;字典键须可哈希,三者常组合用于解析与结构化数据。302 收藏
Python字符串、列表、字典是协同工作的数据搭档:字符串不可变,需用join或转列表操作;列表可变但注意头部操作性能;字典键须可哈希,三者常组合用于解析与结构化数据。302 收藏