-

PyTorch模型输出全一样,根本原因是logits坍缩(标准差≈0),常见于LSTM初始化错误、数据预处理抹平差异或误加Softmax;需检查logits标准差、禁用forward中softmax、确保CrossEntropyLoss输入原始logits。
-

Python的int类型原生支持任意精度大整数,无需额外库;pow(a,b,m)是高效模幂运算唯一推荐方式;bin()/hex()转换比格式化更快,int(s,base)支持超长字符串解析。
-

猜数字游戏是Python入门的绝佳实践,它融合了随机数生成、用户交互、条件判断和循环控制等核心编程概念。通过构建这个游戏,初学者能直观理解代码如何与用户互动,并在解决输入验证、类型转换等问题的过程中加深对编程逻辑和数据类型的掌握。加入次数限制、自定义范围和再玩一次等功能可提升趣味性和挑战性,而良好的代码结构、变量命名及异常处理则有助于培养规范的编程习惯。这个小游戏不仅是语法练习,更是编程思维的启蒙训练。
-

默认json.dumps处理自定义对象慢,因其不识别非内置类型,每次均需通用default回调做类型判断与字段遍历,无缓存、不跳过私有属性、不预编译路径;高效方案是继承JSONEncoder精准分支处理,或改用orjson等高性能库直接序列化。
-

直接mockregion.get会失败,因为region是封装了后端、锁、序列化等逻辑的代理对象,实际调用的是backend.get;正确做法是配置memory后端、mock数据加载函数、用fixture隔离region实例,并统一序列化器以避免上线异常。
-

本文详解二分查找中常见的IndexError:listindexoutofrange错误根源,并提供修复后的递归实现,确保在空列表、单元素或目标不存在时安全运行,同时准确返回原始排序数组中的真实索引位置。本文详解二分查找中常见的`IndexError:listindexoutofrange`错误根源,并提供修复后的递归实现,确保在空列表、单元素或目标不存在时安全运行,同时准确返回原始排序数组中的真实索引位置。二分查找(Binar
-

PyCharm的独特之处在于其集成的开发工具、丰富的自定义选项和快捷方式,以及对Python生态系统的全面支持。1)它提供了智能代码补全和调试功能,2)支持从Django到数据科学工具的广泛生态系统,3)具有强大的代码重构和性能优化工具,4)内置虚拟环境和依赖包管理功能,使得开发过程更加高效和顺畅。
-

Annotated比普通类型注解更合适,因为它能在保留原始类型的同时叠加校验规则、文档说明等元数据,且被mypy等检查器正确识别;元数据可为任意对象,但需避免运行时表达式以确保类型检查有效。
-

Python数据抓取核心是理清“请求→响应→解析→存储”四环节:一、明确目标与请求方式,区分静态/动态加载,合理选用requests或Selenium;二、用CSS选择器精准提取字段,注意防KeyError和文本清洗;三、设计容错逻辑应对缺失、格式混乱与结构变动;四、结构化保存前需校验数据一致性与完整性。
-

zip本质是按位置配对的生成器,返回迭代器而非列表,具最短截断特性,需list()显式转换才可见结果,解包需用zip(*zipped)实现“unzip”。
-

pytest-xdist的--ssh远程执行实为通过execnet通道间接实现,并非真正远程启动进程,常见失败原因包括execnet兼容性问题、SSH配置解析失败、远端Python环境缺失或版本不匹配等。
-
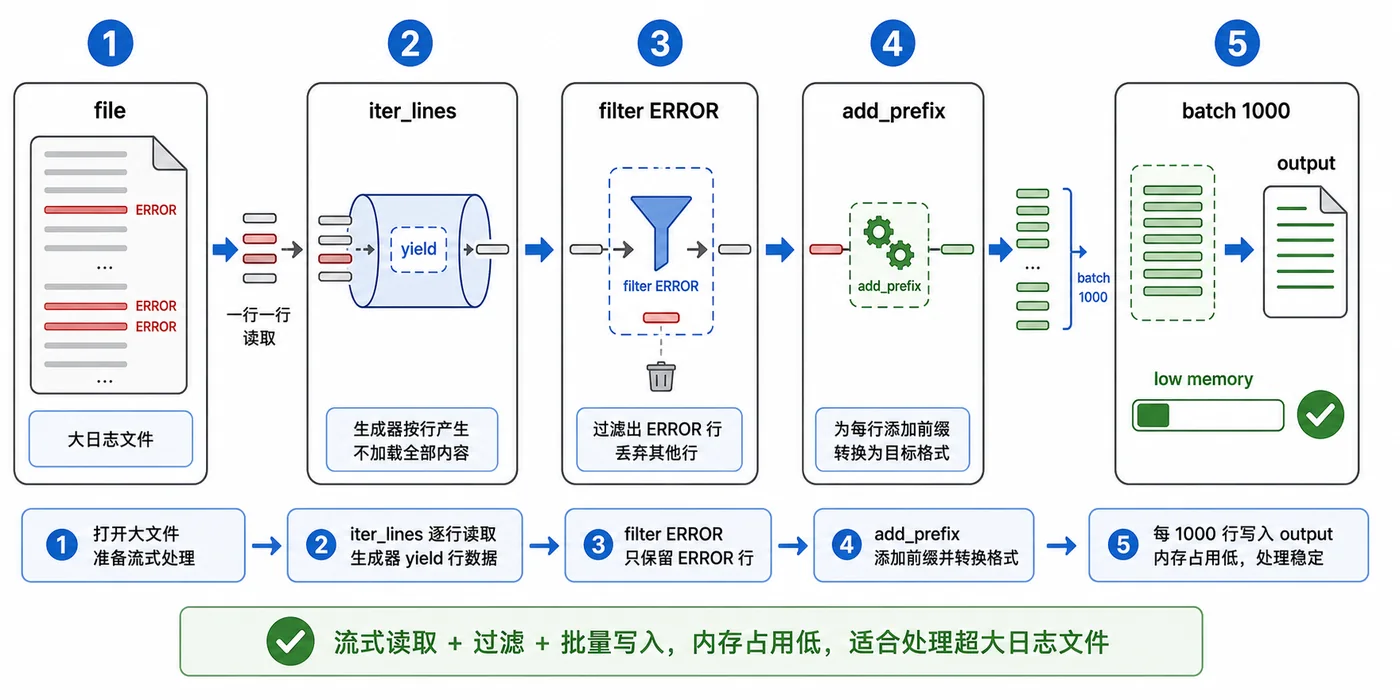
用日志清洗场景演示 Python 处理大文件的稳定方式:不要一次性 read 全部内容,而是用生成器逐行读取、过滤有效行,再按批次写入结果文件,降低内存压力。
-

从 Python Django async view 线上改造入手,讲清异步视图、同步 ORM 边界、sync_to_async、事务收口和上线检查。
-

Pydanticv2+在Flask中最简校验路径是手动调用model_validate_json或model_validate,不依赖插件;需捕获ValidationError并返回422,避免误用装饰器或中间件导致错误信息丢失。
-

reduce函数用于将二元函数应用于序列元素并归约为单个值,需从functools导入;其语法为reduce(function,iterable[,initializer]),其中function为操作函数,iterable为可迭代对象,initializer为可选初始值;示例中通过lambda实现求和:1+2=3,3+3=6,6+4=10,10+5=15,最终输出15;提供初始值时如reduce(lambdax,y:x*y,[1,2,3],10),计算过程为10×1=10,10×2=20,20×3=60