-

普通二叉树:无值限制,用于层次结构;2.二叉搜索树:左小右大,支持高效操作;3.平衡二叉搜索树:AVL和红黑树防退化;4.完全二叉树:节点靠左,适合堆与数组存储;5.满二叉树:每个节点均有0或2子;6.完美二叉树:所有叶同层且内部节点均两子;7.堆:完全二叉树,分最大最小堆,heapq实现最小堆;8.伸展树等高级变体用于特定场景。
-

structlog本身不支持对已获取的logger实例调用.configure()进行局部配置,但可通过structlog.wrap_logger()手动封装不同处理器链,实现多日志器差异化输出。structlog本身不支持对已获取的logger实例调用`.configure()`进行局部配置,但可通过`structlog.wrap_logger()`手动封装不同处理器链,实现多日志器差异化输出。在structlog中,st
-
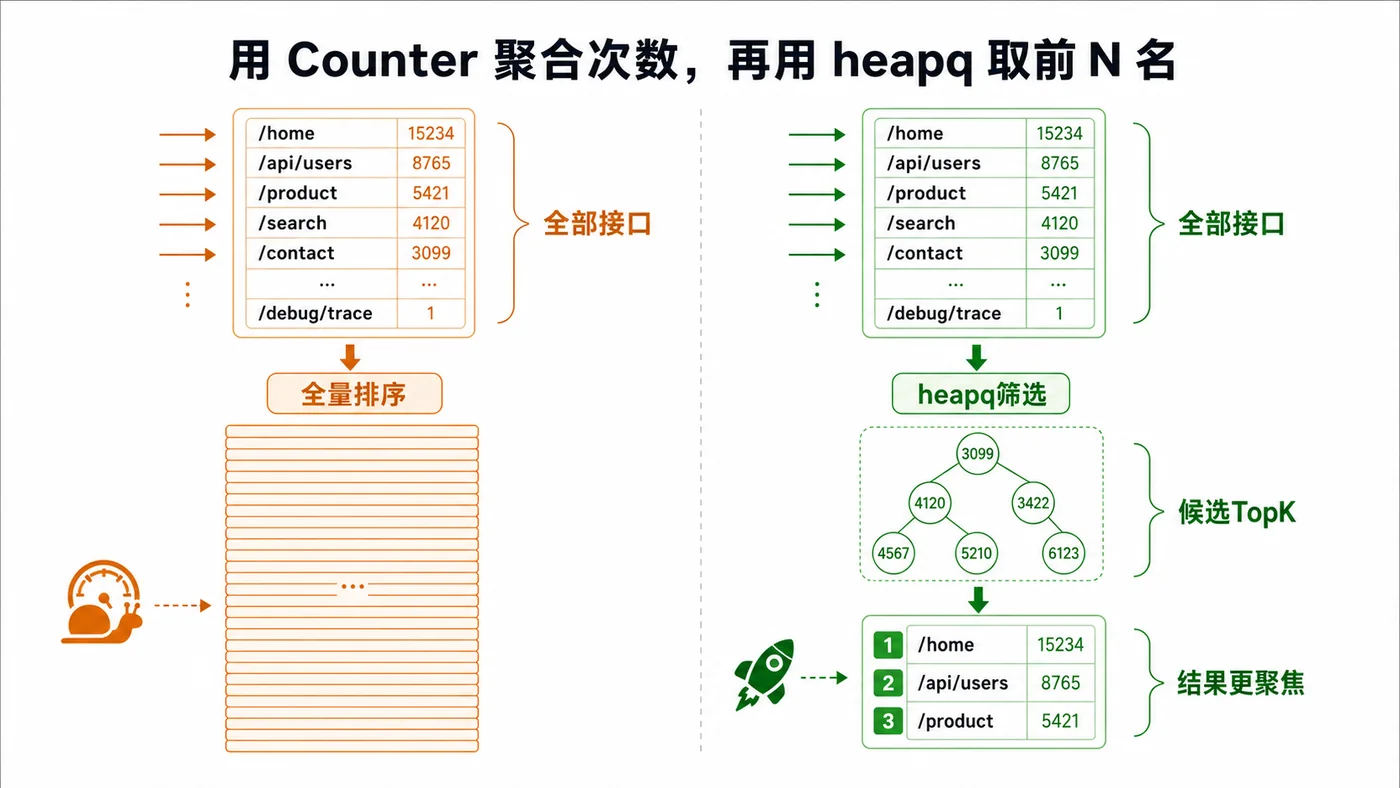
本文用 Python 标准库完成日志 TopK 统计:逐行读取大文件、用 Counter 聚合接口次数,再用 heapq 取出高频接口,适合快速排查访问热点和接口倾斜问题。
-

Python代码解耦的核心是职责清晰、依赖明确、局部修改不影响全局,通过模块化设计、协议定义、依赖注入和配置分离实现可读性、可测试性与可维护性提升。
-

SnowNLP仅支持简体中文且词典陈旧,对新词、emoji等识别不准;无predict方法,sentiments为0~1经验分值;TextBlob原生不支持中文,返回中性结果而不报错;推荐transformers轻量微调模型替代。
-

BeamSearch拖慢翻译速度是因为以空间换时间,每步计算k×vocab_size个logit,内存和计算量随beam_width指数增长;合理设置beam_width=3~5为多数轻量模型甜点区,长文本建议降为3;关闭BeamSearch(num_beams=1)或优化tokenizer(如预分配缓冲、归一化输入、跳过后处理)可显著提速。
-

用+拼接字符串越拼越慢,因str不可变,每次+都新建对象并丢弃原字符串;拼接1000次产生999个废弃字符串,内存与时间双浪费。
-

用asyncio.gather()当需按调用顺序获取全部结果,异常默认中断;用asyncio.wait()当需监控中间状态、提前退出或精细控制超时与异常处理。
-

list的in操作慢因线性扫描O(n),set基于哈希表平均O(1);高频存在判断应转set,适用“查多改少”场景如黑名单校验、去重检查等。
-

Python爬虫存数据到MongoDB需安装PyMongo库、用MongoClient连接数据库、调用insert_one或insert_many插入数据,全过程高效适配非结构化数据,建议添加索引与异常处理以提升稳定性。
-

时间戳需转换为Excel日期格式才能正确显示和计算。Python时间戳从1970年1月1日(UTC)起算,而Excel以1900年1月1日为起点,两者相差25569天。因此,将秒级时间戳转为Excel日期值公式为:(timestamp/86400)+25569;毫秒级则先除以1000或整体除以86400000后再加25569。注意时区问题,推荐使用UTC时间避免本地时区偏差。若用pandas写入Excel(如df.to_excel),可通过pd.to_datetime(timestamp,unit='s'
-

httpx在高并发下通常比aiohttp更快、内存更省,但性能差异取决于请求类型与连接配置:小文件高频请求需调优aiohttp的TCPConnector(如limit_per_host=0),大文件流式下载httpx更稳定,HTTP/2支持更原生,超时与重试机制也更严谨。
-

@lru_cache是functools中基于LRU策略的内存缓存装饰器,要求参数可哈希且函数为纯函数;支持maxsize控制容量,提供cache_info和cache_clear等管理方法。
-

今日头条热搜榜的真实Ajax接口可通过F12打开Network→XHR,筛选含“hot”或“hotboard”的请求,典型URL为https://www.toutiao.com/hot-event/hot-board/,需携带Referer、User-Agent及有效Cookie(含tt_webid)才能成功获取JSON数据。
-

全站脱敏显示必须重写Serializer的to_representation方法,而非to_internal_value;需结合模型Meta或显式声明敏感字段,在非DEBUG环境下执行掩码,且嵌套序列化器、SerializerMethodField等各路径均需统一处理。