-

本文详解如何在Python中正确实现带参数的类方法装饰器(如@Logger.catch(file_path='log.txt')),解决因未区分装饰器工厂与实际装饰逻辑导致的TypeError:missing1requiredpositionalargument'func'错误。本文详解如何在Python中正确实现带参数的类方法装饰器(如@Logger.catch(file_path='log.txt')),解决因未区分装饰器工厂与实际装饰逻辑
-

Python中动态设置和获取属性核心靠setattr()和getattr():前者按字符串名设属性(支持新增),后者按字符串名取值并可设默认值,二者配合__setattr__和__getattr__可实现属性访问的精细控制。
-

GaussianNB适用于连续型数值特征(如身高、温度),MultinomialNB适用于非负整数计数特征(如词频、点击次数);核心依据是特征的物理含义与取值性质,而非分布形态。
-

递归函数测试最常漏掉的三个边界是0、1、负值;出错常因边界未处理,如factorial(n)未处理n==0或n<0导致栈溢出或错误结果。
-
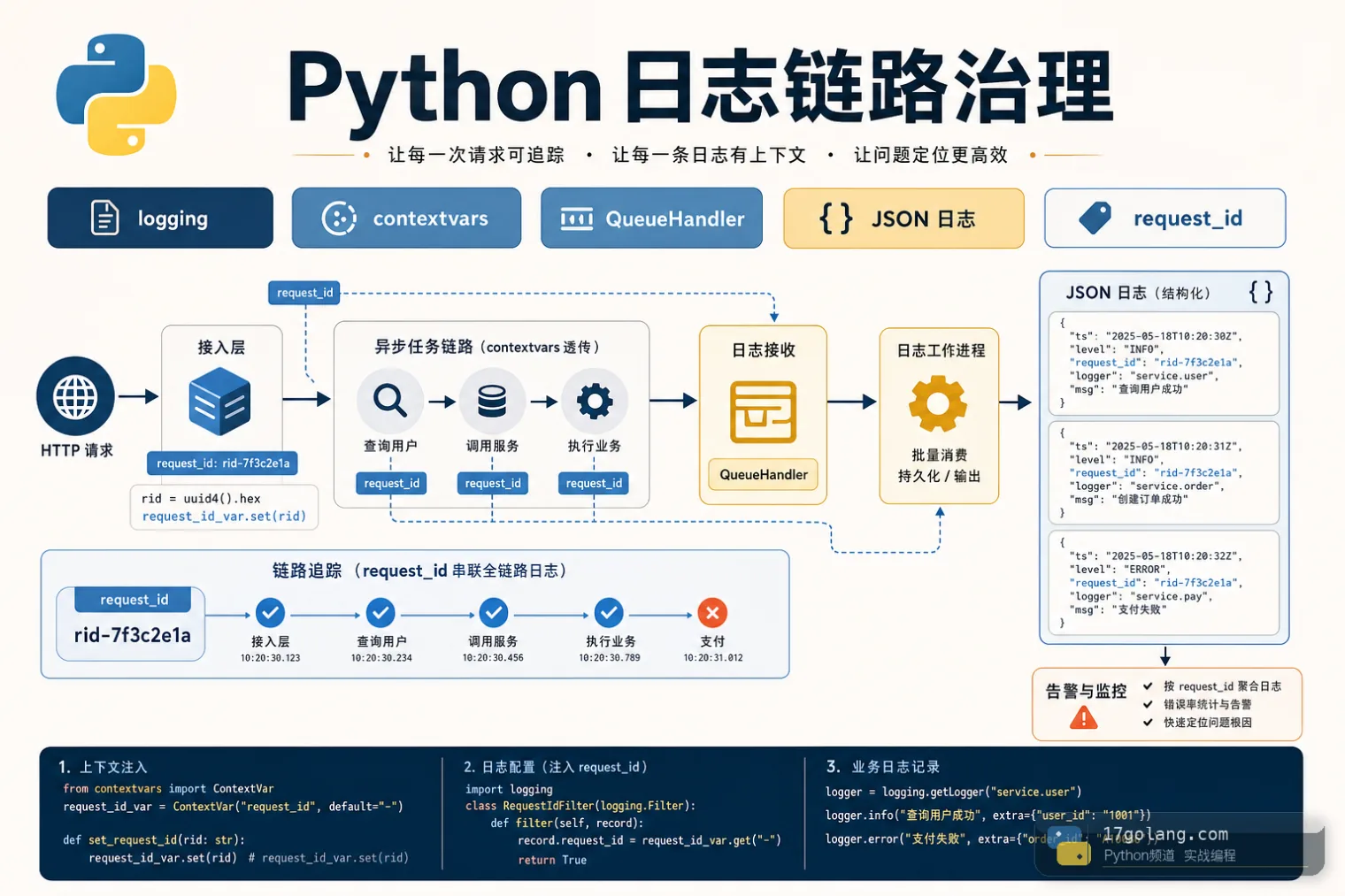
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。
-

本文介绍如何通过TypeAlias和类型提取技巧,在不修改外部库源码的前提下,安全、自动地复用第三方函数的参数类型,实现跨函数的类型推导与mypy严格校验。
-

SSL/TLS认证需验证服务器身份防中间人攻击,requests默认校验证书,手动用ssl模块须显式启用;密钥不可硬编码,应动态获取并使用AES-GCM或RSA加密;HTTPS服务端须限制协议版本、密码套件并启用HSTS;开发中需过滤日志敏感信息、用secrets生成随机数、审计第三方包。
-

直接操作bar返回的BarContainer对象的patches列表是动态着色特定柱子的唯一可靠方式,需用enumerate遍历patches并依原始数据索引设置set_facecolor(),避免使用set_color()或误操作ax.patches。
-

Python变量是标签而非盒子,赋值仅改变指向;可变对象赋值共享引用,修改会相互影响;is判断同一对象,==判断逻辑相等;函数内赋值默认创建局部变量。
-

答案:os模块用于文件目录操作(如创建、删除、重命名)、路径处理(结合os.path判断路径、拼接等)、环境变量管理(获取和设置)、执行系统命令及获取进程用户信息,需注意跨平台兼容性和权限细节。
-

Python中可用id()获取列表内存地址,返回十进制整数,hex()可转十六进制;修改列表元素不改变地址,但重新赋值会创建新对象;无需且不应使用ctypes等模拟C指针。
-

最快方法是在ModelAdmin类中直接设置fields属性,按需列出字段名列表,该方式零配置、立即生效、兼容性强;次选方案是使用fieldsets分组并嵌套元组实现横向排布,注意fields与fieldsets互斥。
-

汉诺塔递归函数通过分解问题实现n个盘子的移动:先将n-1个盘子从起始柱移到辅助柱,再将最大盘移到目标柱,最后将n-1个盘子从辅助柱移到目标柱;Python中用hanoi(n,start,helper,target)函数递归实现,每次调用处理一层子问题,最终完成全部移动。
-

在Python子类__init__中,应直接使用传入的参数(如x)而非self.x调用子类特有方法;因self.x类型在父类中未被严格约束,IDE无法推断其具体子类方法,易触发类型警告。
-

len在Python中是用来计算对象长度的函数。1)对于字符串,len返回字符数量。2)对于列表、元组等,len返回元素数量。3)对于字典,len返回键值对数量。4)自定义类可通过__len__方法支持len函数。