-

本文介绍如何对位于分段线性3D路径上的点进行精确的距离插值——关键在于识别问题本质为1D参数化插值,而非错误地使用3D空间插值(如griddata),从而避免NaN输出并提升计算效率与精度。本文介绍如何对位于分段线性3D路径上的点进行精确的距离插值——关键在于识别问题本质为1D参数化插值,而非错误地使用3D空间插值(如`griddata`),从而避免NaN输出并提升计算效率与精度。在处理沿3D曲线分布的数据时,一个常见误区是将路径点视为不规则三维散点,并直
-

HuberLoss默认delta=1.0易导致退化为MSE,需根据数据误差尺度(如四分位数)显式设置delta,并区分使用tf.keras.losses.Huber(Loss类)与tf.losses.Huber(函数),编译模型时必须用前者并指定reduction。
-

答案是使用Python解决LeetCode题目需理解题意并按函数签名实现逻辑,常用双指针、哈希表、滑动窗口、DFS/BFS和动态规划等算法,结合数据结构优化解法,通过手动测试用例和平台验证调试,建议分类刷题、总结模板并学习优质解答以提升效率。
-

copy.deepcopy有时改了原对象,是因为其对不可拷贝成分(如文件句柄、线程锁)、未正确实现__reduce__或__getstate__的自定义类、或某些C扩展类型(如旧版NumPy数组)可能静默降级为浅拷贝或抛出TypeError,导致隔离失效。
-

Flask默认日志不写入文件是因为开发服务器仅输出到stderr且未配置文件handler;生产环境日志更易被WSGI接管或丢弃。常见问题包括basicConfig失效、日志仅显示在终端、重启后文件为空及多进程错乱。根本原因是app.logger是独立实例,不继承rootlogger配置,且Flask启动时已添加StreamHandler,basicConfig仅在root无handler时生效;同时若未显式设置日志级别,WARNING以下消息会被过滤。可靠写法是直接为app.logger添加Rotati
-

shutil.copytree默认要求目标目录不存在,否则抛FileExistsError;Python3.8+可用dirs_exist_ok=True跳过该错误,仅覆盖同名文件,不清理目标中多余内容。
-

Safety仅扫描requirements.txt中的直接依赖,不递归分析子依赖或锁定文件,也不检测逻辑漏洞;需加--full-report才显示CVE编号等完整信息。
-
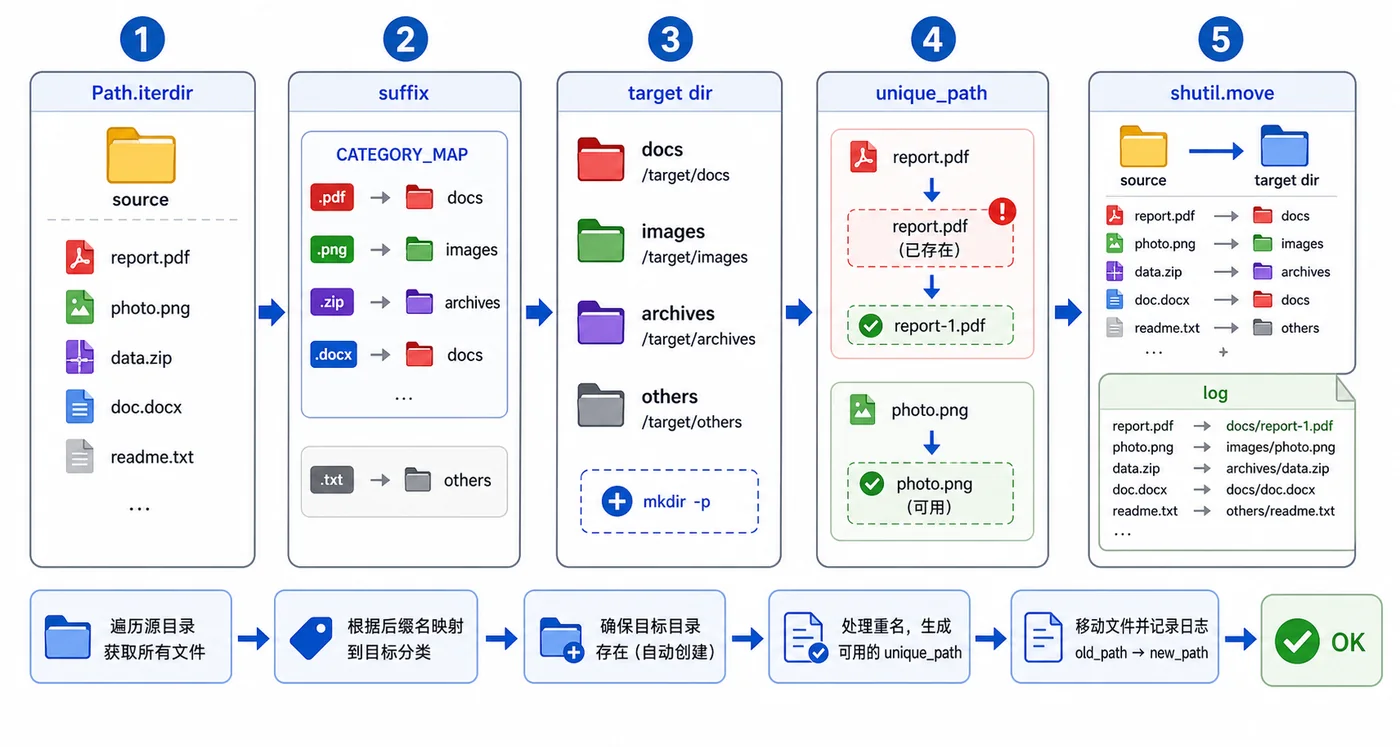
用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。
-

应捕获特定网络异常而非Exception:requests对应ConnectionError、Timeout、HTTPError(需status_code≥500);httpx对应ConnectError、TimeoutException;重试3次,采用带抖动的指数退避;必用functools.wraps保留签名;非幂等请求如POST需业务层控制重试。
-

唯一稳妥路径是用conda创建Python3.9环境:condacreate-ntf29python=3.9,再condainstall-cconda-forgetensorflow=2.9.0;因TensorFlow2.9官方不支持Python3.10+,其二进制包依赖libpython3.9.so,ABI不兼容导致pip强装必失败。
-

PyScript加载失败主因是py-config配置错误或CDN资源不可达,需确保py-config在body顶部、显式指定pyodide_url,并用Network面板验证;import失败因pandas等含C扩展包须用micropip动态安装;DOM交互卡顿应避免频繁innerHTML操作;本地开发必须启用HTTP服务规避CORS限制。
-

LabelEncoder不接受缺失值,fit()遇None或NaN直接报错;须先清洗(删除或填充)再fit;transform时若遇新标签会报错,应统一用同一实例并考虑OrdinalEncoder兜底。
-

异步死锁是协程await永久不释放的锁时静默挂起,主因是多协程交叉获取锁顺序不一致导致循环等待;须按全局统一顺序加锁、缩小临界区、禁用手动acquire/release、用asyncwith确保释放。
-

Python多线程不适合CPU密集任务,核心原因是全局解释器锁(GIL)的存在——它强制同一时刻只有一个线程执行Python字节码,即使在多核CPU上,也无法真正并行执行计算密集型代码。CPU密集任务会被GIL串行化GIL是CPython解释器为内存管理安全而加的一把“独占锁”。当一个线程在做纯计算(如循环累加、矩阵运算、加密解密)时,它会一直持有GIL,其他线程只能等待。结果是:多线程跑CPU密集任务,耗时几乎和单线程一样,甚至更慢(因线程切换开销)。例
-

r高但%idle高说明CPU不忙,瓶颈在futex/mutex等同步原语争用;可用perfrecord-e'syscalls:sys_enter_futex'和pidstat-w验证,重点看用户进程调用栈是否含pthread_mutex_lock或__lll_lock_wait。