-

r高但%idle高说明CPU不忙,瓶颈在futex/mutex等同步原语争用;可用perfrecord-e'syscalls:sys_enter_futex'和pidstat-w验证,重点看用户进程调用栈是否含pthread_mutex_lock或__lll_lock_wait。
-

纯数据读取场景下,sqlalchemy.core通常比sqlalchemy.orm快1.5–3倍,因绕过对象生命周期管理;但orm在需对象行为、关联操作时更优,二者应按场景混合使用。
-

defaultdict初始化必须传可调用对象,如int、list、lambda:"N/A";不可传0或[];int不带括号;计数用defaultdict(int),归集用defaultdict(list);访问缺失key会自动插入,影响内存和键判断。
-

根本原因是logging.LogRecord默认不携带请求级上下文变量,trace_id必须通过contextvars+自定义Filter显式注入;threading.local在异步场景失效,contextvars未正确传递或解析格式错误也会导致丢失。
-

PyPDF2.PdfMerger合并PDF出错的根本原因有四:路径未排序致顺序错乱;封面页重复插入;4.0+版本API变更要求显式传fileobj;字体不嵌入致中文乱码;大文件内存爆满。
-
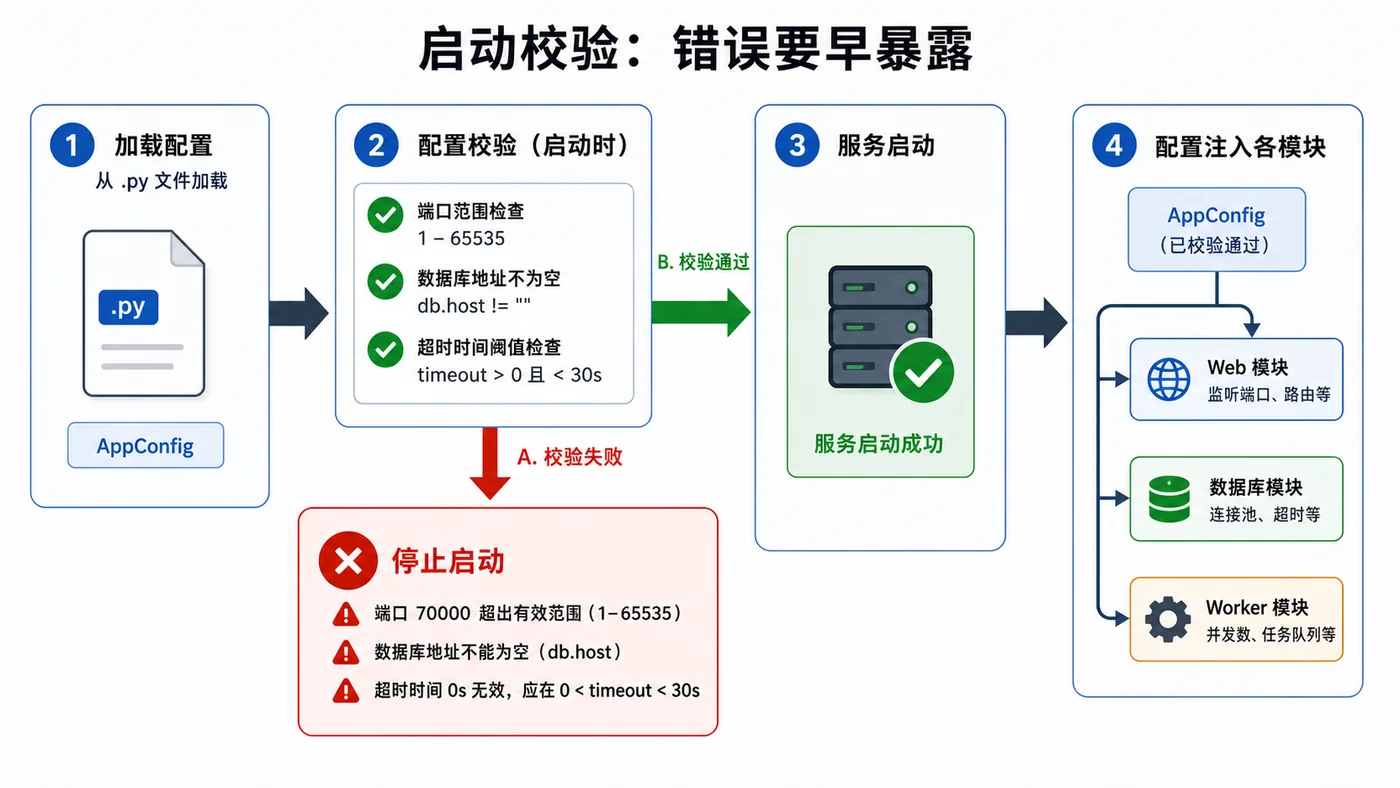
本文用标准库 dataclass 写一套轻量配置加载方案,演示默认值、环境变量覆盖、类型转换和启动校验,避免服务上线后才发现端口、数据库地址或超时参数写错。
-

应使用bbox_to_anchor与ncol联合控制图例位置,配合tight_layout的rect参数预留空间或用subplots_adjust直接调整边距,再通过columnspacing、handlelength和fontsize微调多行图例对齐与显示效果。
-

Python3.12安装后cmd报“不是内部或外部命令”主因是PATH未正确配置,安装时必须勾选“Addpython.exetoPATH”,否则需手动添加安装目录及Scripts路径到系统环境变量。
-

VSCode中Python插件无法识别解释器、模块导入失败、调试断点无效及中文乱码等问题,根源在于解释器路径未正确配置、虚拟环境未激活、launch.json配置错误或终端/文件编码不一致,需按系统差异逐一排查。
-

STATIC_URL是浏览器请求静态资源的URL前缀(如/static/),STATIC_ROOT是collectstatic命令汇总静态文件的目标物理目录,仅用于生产环境由Web服务器直接服务。
-

通过外部 API 调用场景,演示 Python requests 如何设置 connect/read 超时、复用 Session 连接池、配置重试策略,并记录日志定位慢请求。
-

正确设置路由器无线参数可提升网络稳定性与安全性:首先设置个性化SSID,避免默认名称和敏感信息;其次选择WPA2/WPA3加密并设置强密码;然后根据使用场景选择2.4GHz(覆盖广)或5GHz(速率高)频段,必要时调整信道减少干扰;最后建议定期更新固件、关闭WPS、启用MAC过滤或隐藏SSID,完成设置后重启路由器并测试连接,确保网络高效安全运行。
-

for循环在NumPy中特别慢,因Python解释器需反复进行类型检查、对象查找和引用计数,而NumPy数组是连续内存中的同构数据块,应通过向量化操作(如ufunc、布尔索引、np.where)而非Python层循环来利用CPU批量处理能力。