-

Python库默认存放在site-packages目录,路径因环境和系统而异;应使用pip安装而非手动复制文件,开发时推荐pipinstall-e.。
-

MonkeyPatch能改类但不改源码,因Python类对象可变,方法是绑定到类命名空间的函数对象,直接赋值修改类__dict__即可生效,仅对新式类可靠;动态加实例方法须用types.MethodType绑定,否则self不自动传入。
-

因为pickle只记录“模块名+函数名”路径而非函数体,子进程需据此重新导入;若函数在__main__中(如脚本顶层),Windowsspawn无法复现上下文;若在嵌套作用域,则无全局名称可查,导致PicklingError。
-

先检查nvidia-smitopo-p2pr输出是否大量显示N/A或PHB而非PIX/SYS,若P2P未通则all_reduce降速3–5倍;确认硬件拓扑、BIOS设置,禁用CUDA_VISIBLE_DEVICES并显式绑定设备,backend必须设为"nccl",再通过nvidia-smidmon-su-d1观察PCIe带宽是否饱和。
-

asyncio.run()无法直接捕获create_task启动的任务异常,需在任务内处理或通过await、gather(return_exceptions=True)、task.exception()显式获取;retrying不支持异步。
-

本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如Overtake(v1))必然为真,从而实现确定性行为推理。本文详解如何通过Z3的增量求解(push/pop)与双重检查(SAT/UNSAT对比)机制,严格验证在给定约束下哪些动作谓词(如`Overtake(v1)`)必然为真,从而实现确定性行为推理。在自动驾驶或形式化安全推理场景中,仅满足约束是不够的——我们需要
-

嵌套字典是轻量级Trie实现,用dict键存字符、值为子节点,以'END'标记单词结尾;需注意键类型、终止标识设计、避免可变默认参数、空字符串处理及重叠前缀路径复用。
-

递归函数测试最常漏掉的三个边界是0、1、负值;出错常因边界未处理,如factorial(n)未处理n==0或n<0导致栈溢出或错误结果。
-
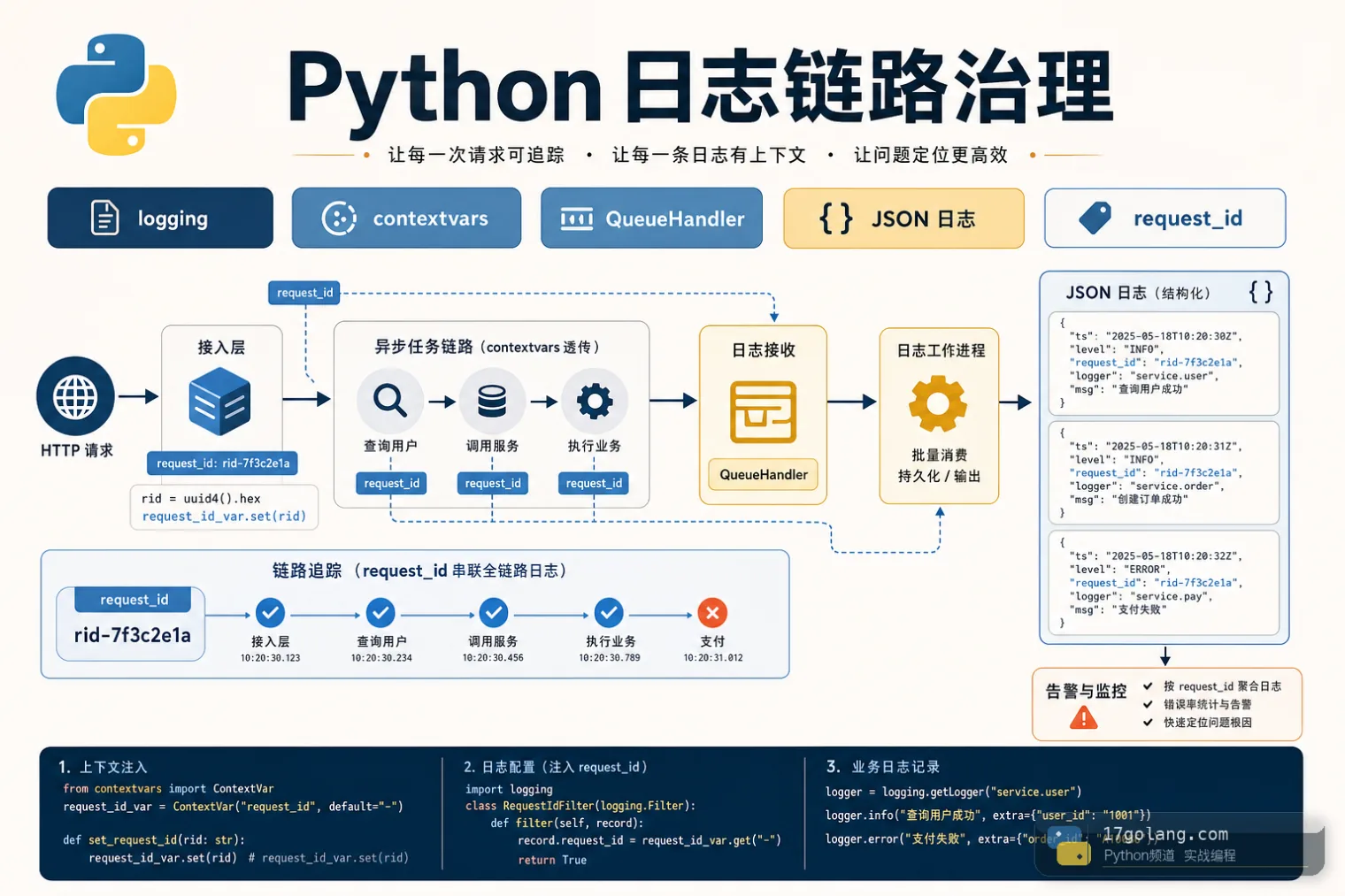
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。
-

len在Python中是用来计算对象长度的函数。1)对于字符串,len返回字符数量。2)对于列表、元组等,len返回元素数量。3)对于字典,len返回键值对数量。4)自定义类可通过__len__方法支持len函数。
-

Python中__eq__方法决定==运算符行为,默认仅比较对象身份;需重写以按属性值判断相等,且须遵循类型检查、返回布尔值、保持对称性等原则,并注意与__hash__配合及常见错误规避。
-

本文介绍如何对位于分段线性3D路径上的点进行精确的距离插值——关键在于识别问题本质为1D参数化插值,而非错误地使用3D空间插值(如griddata),从而避免NaN输出并提升计算效率与精度。本文介绍如何对位于分段线性3D路径上的点进行精确的距离插值——关键在于识别问题本质为1D参数化插值,而非错误地使用3D空间插值(如`griddata`),从而避免NaN输出并提升计算效率与精度。在处理沿3D曲线分布的数据时,一个常见误区是将路径点视为不规则三维散点,并直
-

HuberLoss默认delta=1.0易导致退化为MSE,需根据数据误差尺度(如四分位数)显式设置delta,并区分使用tf.keras.losses.Huber(Loss类)与tf.losses.Huber(函数),编译模型时必须用前者并指定reduction。
-

答案是使用Python解决LeetCode题目需理解题意并按函数签名实现逻辑,常用双指针、哈希表、滑动窗口、DFS/BFS和动态规划等算法,结合数据结构优化解法,通过手动测试用例和平台验证调试,建议分类刷题、总结模板并学习优质解答以提升效率。
-

copy.deepcopy有时改了原对象,是因为其对不可拷贝成分(如文件句柄、线程锁)、未正确实现__reduce__或__getstate__的自定义类、或某些C扩展类型(如旧版NumPy数组)可能静默降级为浅拷贝或抛出TypeError,导致隔离失效。