-
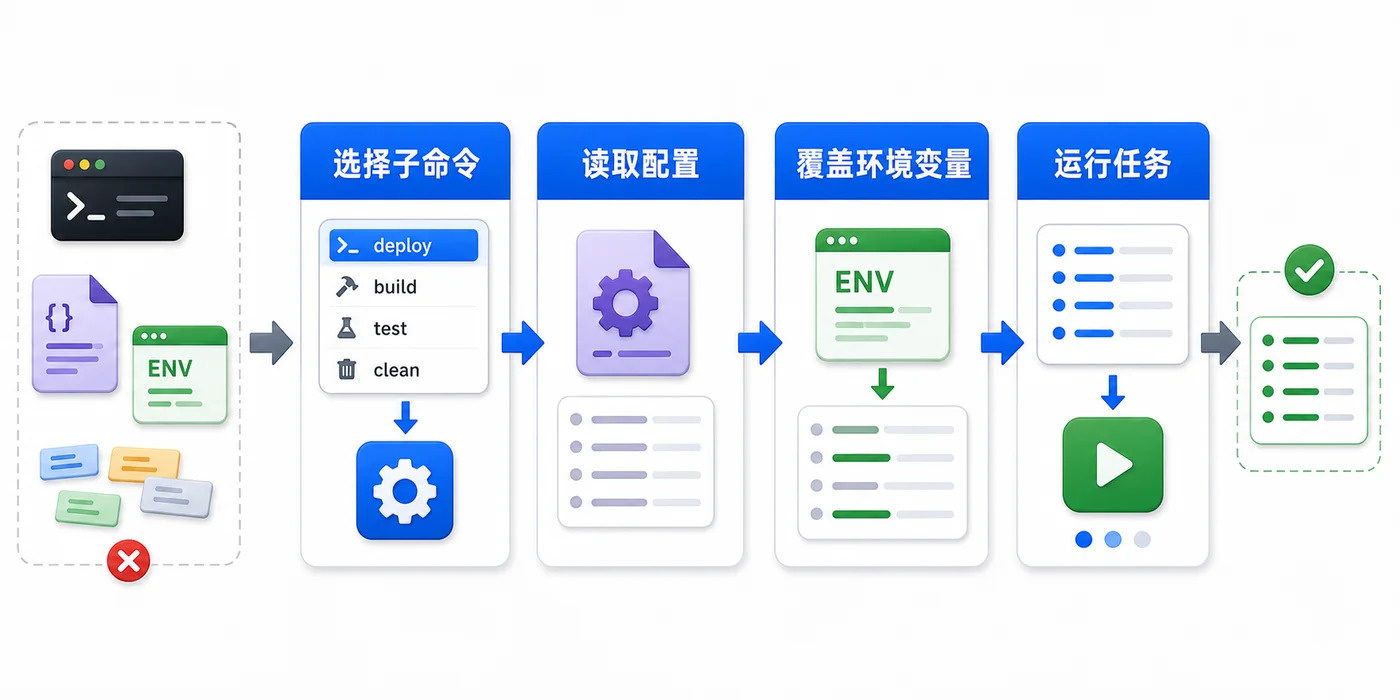
本文用日志清理工具做例子,演示 Python argparse 如何解析参数、校验类型、设计子命令,并把配置文件和环境变量合并成最终运行参数。
-

生成器推导式用圆括号语法(gen_exprforvariableiniterableifcondition)创建惰性求值的生成器对象,相比列表推导式更节省内存,适用于处理大数据或需逐个访问的场景。
-

不能。pytest_terminal_summary钩子仅用于终端输出汇总信息,无数据库连接且不保证测试完成,强行回填易漏数据、抛异常或阻塞输出;应改用pytest_runtest_makereport钩子,在rep.when=="call"时提取case_id并写入数据库。
-

直接计算方差膨胀因子(VIF)最有效,VIF>5提示潜在共线性,>10确认严重共线性;VIF仅适用于线性回归,须在未标准化数据上计算,且需重算以应对动态共线性结构。
-

直接调用父类名会破坏菱形继承的初始化顺序,因强行跳过MRO导致A.__init__重复执行、C.__init__被跳过及super()链中断;应统一用super()配合**kwargs透传参数,并验证D.__mro__确保顺序正确。
-

await位置错误会导致异步退化为同步:循环内await使请求串行,应改用asyncio.gather并发;非async函数中需用asyncio.run()或await调用;不可await非awaitable对象,如time.sleep或requests.get。
-

np.genfromtxt读带表头CSV时第一行出错,因默认不跳过表头且尝试将字符串转float报错;需用skip_header=1跳过表头,配合missing_values、filling_values处理缺失值,并注意编码与dtype设置。
-

skl2onnx保存sklearn模型为ONNX需先fit模型并提供带类型和shape的X_sample;convert_sklearn依赖拟合后属性推导schema;输出字段名比索引更可靠;体积增大是因参数展开为常量节点,属正常现象。
-

pandas读取Excel合并单元格时仅保留左上角值,其余为NaN,因合并属显示层操作,底层无数据对应;可用ffill按行填充连续NaN,但不恢复合并格式。
-

zscore返回NaN需先检查并过滤NaN/inf,或用nan_policy='omit';阈值3不普适,应结合分布和业务调整;多维数据需区分字段级与样本级检测;pandas计算慢时优先用scipy.stats.zscore。
-

逻辑删除是通过deleted_at等字段标记数据“已删除”而非物理删除,需自动过滤未删除记录以避免遗漏;SQLAlchemy需结合Query子类、事件监听和显式关系条件实现全局、安全、可绕过的软删机制。
-

__getattr__仅在访问不存在属性时触发,用于动态代理、惰性加载和友好错误提示;它不拦截已定义属性或方法,也不替代__getattribute__。
-

attributes("-topmost",True)是最简方案,但非真正永久:Windows较稳定,macOS和Linux(尤其Wayland)支持有限;需窗口已显示(deiconify/update后),且切换或withdraw后需重设;lift()和focus_force()无法突破系统Z-order,不适用于长期置顶。
-

Ubuntu22.04官方仓库仅提供Python3.10,不包含python3.11,需通过deadsnakesPPA安装;执行sudoadd-apt-repositoryppa:deadsnakes/ppa后更新并安装python3.11及-venv、-dev包;切勿用update-alternatives修改系统默认python3,应显式调用或使用venv隔离环境。
-

TensorFlow2.x中应使用tf.keras.applications直接加载预训练模型,如ResNet50(weights='imagenet'),自动下载权重;去顶层用include_top=False;必须用对应模型的preprocess_input预处理,不可混用或手动归一化。