python教程技术文章
-
 Python并发设计的核心是根据任务类型、资源约束和可维护性做有意识取舍:I/O密集用异步或线程,CPU密集必须用多进程;需控制并发规模、避免状态共享、强化可观测性,并优先明确责任边界。210 收藏
Python并发设计的核心是根据任务类型、资源约束和可维护性做有意识取舍:I/O密集用异步或线程,CPU密集必须用多进程;需控制并发规模、避免状态共享、强化可观测性,并优先明确责任边界。210 收藏 -
 正则回溯因嵌套量词、重叠分支等导致指数级试错,使匹配耗时暴增;可用regex模块超时机制、长度递增测试及re.DEBUG字节码分析来识别和规避。210 收藏
正则回溯因嵌套量词、重叠分支等导致指数级试错,使匹配耗时暴增;可用regex模块超时机制、长度递增测试及re.DEBUG字节码分析来识别和规避。210 收藏 -
 np.sum()结果与预期不相等是因浮点数二进制表示固有误差,累积导致微小偏差;应使用np.allclose()等容差比较而非==,关键场景可改用Decimal或Kahan求和。210 收藏
np.sum()结果与预期不相等是因浮点数二进制表示固有误差,累积导致微小偏差;应使用np.allclose()等容差比较而非==,关键场景可改用Decimal或Kahan求和。210 收藏 -
 Python处理跨平台换行符时,可通过open函数自动转换或手动替换统一为\n。读取时使用文本模式可自动标准化为\n;需精确控制时可用replace方法将\r\n和\r替换为\n;写入时通过newline参数指定换行格式;批量处理可结合pathlib遍历文件并统一换行符,确保跨平台兼容性。210 收藏
Python处理跨平台换行符时,可通过open函数自动转换或手动替换统一为\n。读取时使用文本模式可自动标准化为\n;需精确控制时可用replace方法将\r\n和\r替换为\n;写入时通过newline参数指定换行格式;批量处理可结合pathlib遍历文件并统一换行符,确保跨平台兼容性。210 收藏 -
 SVM是一种通过寻找最大间隔超平面进行分类的监督学习算法,利用核函数处理非线性数据,在高维空间表现优异;Python中使用scikit-learn的SVC类实现,需注意数据标准化和参数调优以提升性能。209 收藏
SVM是一种通过寻找最大间隔超平面进行分类的监督学习算法,利用核函数处理非线性数据,在高维空间表现优异;Python中使用scikit-learn的SVC类实现,需注意数据标准化和参数调优以提升性能。209 收藏 -
 Python多异常处理有五种方法:一、多个except分别捕获;二、except元组捕获多种异常;三、用基类捕获后isinstance判断;四、嵌套try-except分层处理;五、else和finally增强流程控制。209 收藏
Python多异常处理有五种方法:一、多个except分别捕获;二、except元组捕获多种异常;三、用基类捕获后isinstance判断;四、嵌套try-except分层处理;五、else和finally增强流程控制。209 收藏 -
 Python函数参数拆解中,将可迭代对象展开为位置参数,*将字典展开为关键字参数;二者在调用时须遵循位置顺序,在定义时则用于收集多余参数,配合使用可实现灵活接口。209 收藏
Python函数参数拆解中,将可迭代对象展开为位置参数,*将字典展开为关键字参数;二者在调用时须遵循位置顺序,在定义时则用于收集多余参数,配合使用可实现灵活接口。209 收藏 -
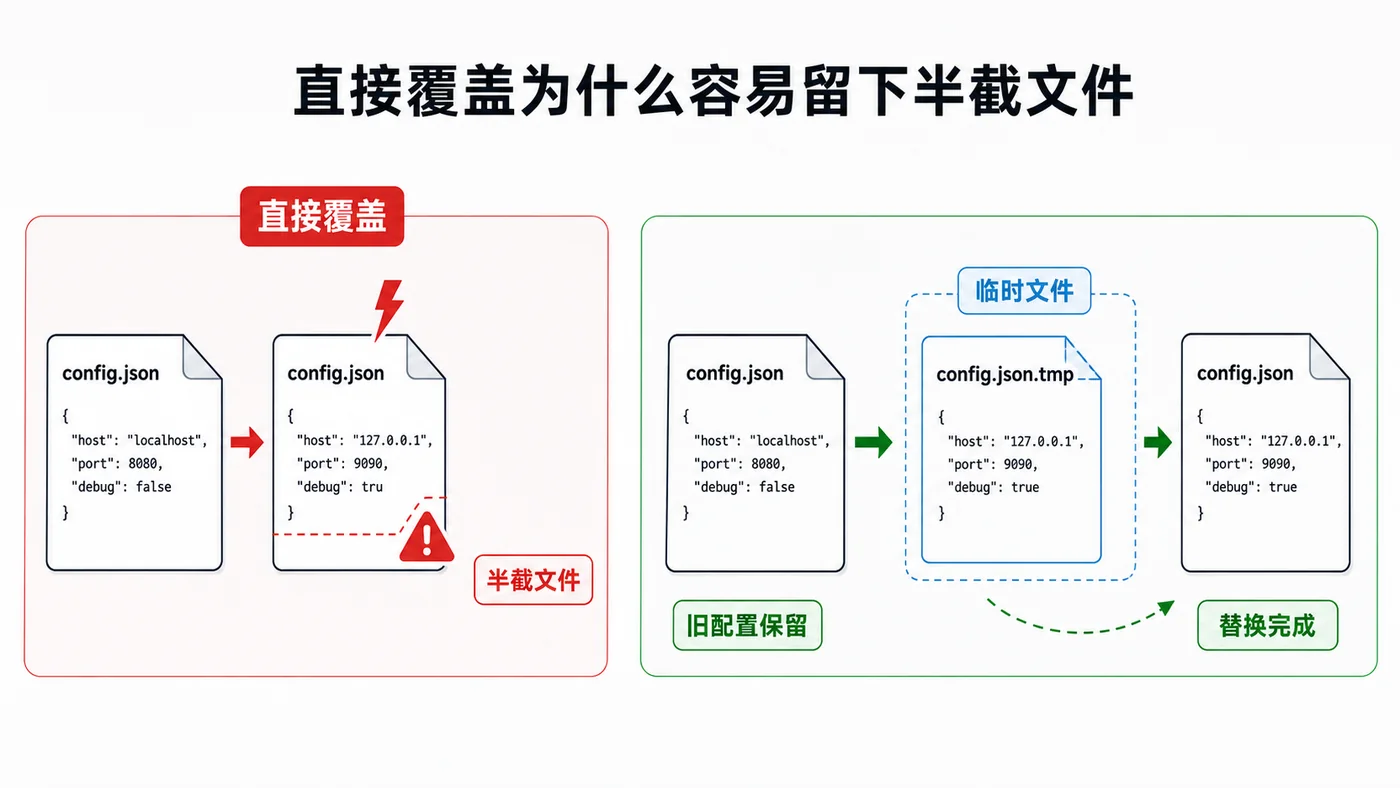 本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。209 收藏
本文用 Python 标准库实现配置文件原子写入:先写临时文件、刷盘校验,再用 os.replace 一步替换目标文件,避免程序中断时留下半截配置。209 收藏 -
 推荐用字典继承+环境变量驱动加载:config/下分base.py、development.py、production.py,主类通过dict.update合并;YAML用&anchor/*anchor复用字段,Python侧deepmerge;敏感配置走环境变量或加密文件。208 收藏
推荐用字典继承+环境变量驱动加载:config/下分base.py、development.py、production.py,主类通过dict.update合并;YAML用&anchor/*anchor复用字段,Python侧deepmerge;敏感配置走环境变量或加密文件。208 收藏 -
 Tkinter支持通过函数化封装和父子控件管理,将一个GUI的组件(而非独立窗口)嵌入到另一个主窗口中,关键在于避免调用Tk()多次、不启动mainloop()于子模块,并将UI构建逻辑改为接收父容器(如Frame或Tk实例)作为参数。208 收藏
Tkinter支持通过函数化封装和父子控件管理,将一个GUI的组件(而非独立窗口)嵌入到另一个主窗口中,关键在于避免调用Tk()多次、不启动mainloop()于子模块,并将UI构建逻辑改为接收父容器(如Frame或Tk实例)作为参数。208 收藏 -
 Python连接字符串最常用方法是f-string(推荐)和join(),加号(+)适用于已知全为字符串的简单拼接,需注意类型一致;f-string简洁高效支持表达式,join()适合批量合并带分隔符的字符串。208 收藏
Python连接字符串最常用方法是f-string(推荐)和join(),加号(+)适用于已知全为字符串的简单拼接,需注意类型一致;f-string简洁高效支持表达式,join()适合批量合并带分隔符的字符串。208 收藏 -
 ZoneInfo是Python3.9+推荐的原生时区解决方案,直接对接IANAtzdata,可直接作为tzinfo参数传入datetime构造函数,无需localize;但Windows需额外安装tzdata包,且不支持模糊时区名。208 收藏
ZoneInfo是Python3.9+推荐的原生时区解决方案,直接对接IANAtzdata,可直接作为tzinfo参数传入datetime构造函数,无需localize;但Windows需额外安装tzdata包,且不支持模糊时区名。208 收藏 -
 真正掌握目标检测需动手实践:先用简数据集跑通FasterR-CNN,确认流程;深入MMDetection或Detectron2源码理解训练逻辑;用三类可视化诊断问题;坚持小步迭代调参,三个月形成实战能力。208 收藏
真正掌握目标检测需动手实践:先用简数据集跑通FasterR-CNN,确认流程;深入MMDetection或Detectron2源码理解训练逻辑;用三类可视化诊断问题;坚持小步迭代调参,三个月形成实战能力。208 收藏 -
 Python库默认存放在site-packages目录,路径因环境和系统而异;应使用pip安装而非手动复制文件,开发时推荐pipinstall-e.。208 收藏
Python库默认存放在site-packages目录,路径因环境和系统而异;应使用pip安装而非手动复制文件,开发时推荐pipinstall-e.。208 收藏 -
 MonkeyPatch能改类但不改源码,因Python类对象可变,方法是绑定到类命名空间的函数对象,直接赋值修改类__dict__即可生效,仅对新式类可靠;动态加实例方法须用types.MethodType绑定,否则self不自动传入。208 收藏
MonkeyPatch能改类但不改源码,因Python类对象可变,方法是绑定到类命名空间的函数对象,直接赋值修改类__dict__即可生效,仅对新式类可靠;动态加实例方法须用types.MethodType绑定,否则self不自动传入。208 收藏