-

Python用户输入清洗需统一格式、剔除干扰、验证边界、转为可用类型:用.strip()去首尾空白,正则压缩中间空格并过滤零宽字符;英文转小写、中文全角转半角;手机号去除非数字后验长度,金额去符号转数值,日期用专业解析;白名单过滤非法字符、截断超长输入,并在各环节嵌入清洗策略。
-

ASGI是支持异步的服务器与应用通信协议,非Python语法或内置模块;其应用必须为async可调用对象,同步框架需桥接,启动时需注意--reload限制、uvicorn.run()多进程风险及HTTP/2的TLS依赖。
-
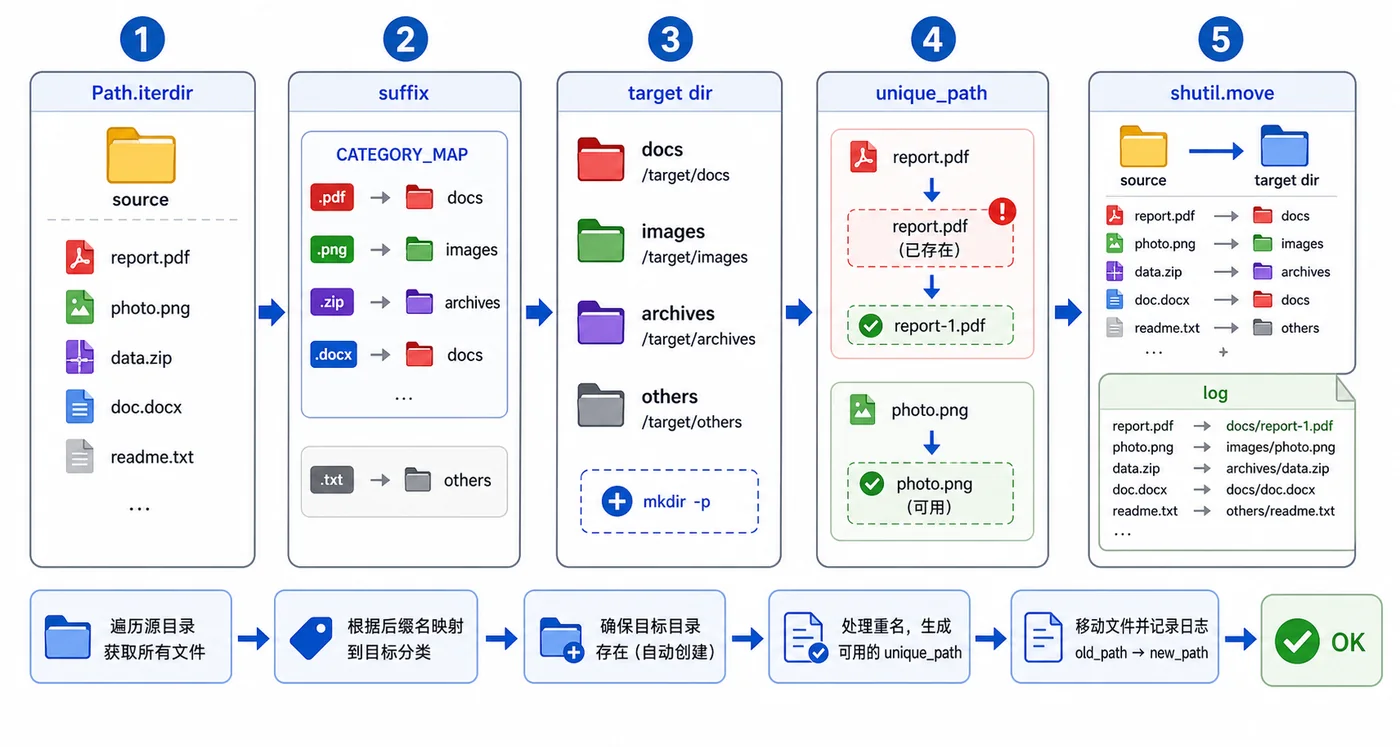
用下载目录整理场景演示 Python pathlib 的实用写法:扫描文件、按扩展名创建分类目录、处理同名冲突、移动文件并记录日志,让批量文件整理脚本更稳。
-

Python私有变量并非真正私有,仅通过命名约定(如_var)和名称修饰(如__var→_ClassName__var)实现弱约束,不提供强制访问控制,仅防误用。
-

SQLAlchemy读写分离需显式配置bind路由,仅声明SQLALCHEMY_BINDS不生效;必须通过__bind_key__、get_bind()钩子或手动指定bind参数控制连接选择,否则所有操作默认走主库。
-

Python线程阻塞通常不是因为“死循环”或“CPU耗尽”,而是卡在I/O、锁、队列、条件变量等同步原语上。排查关键在于快速定位线程当前停在哪一行、持有哪些锁、等待什么资源。查看线程堆栈(最直接)用threading.settrace()或信号中断+sys._current_frames()获取各线程当前执行位置。生产环境推荐轻量方式:发送SIGUSR1(Linux/macOS)触发堆栈打印:注册信号处理器,遍历threading.enumerate(),对每个线程调用trace
-

load_dotenv()必须在os.getenv()调用前执行,否则返回None;默认只读当前工作目录的.env文件,路径错、编码BOM、大小写不一致、变量优先级(系统变量高于.env)等均会导致失效。
-

StandardScaler不能直接对测试集fit_transform,因会泄露测试集统计信息;须用训练集fit后,再用同一scaler对测试集transform。SimpleImputer中,偏态或含异常值选"median",近似正态且缺失少选"mean"。
-

Python协程调度核心是单线程事件循环,本质为任务调度器与I/O多路复用驱动器,通过协作式调度在await点切换Task;Task是调度基本单位,需显式创建并入队,调度依赖ready、delayed和selector三类队列协同。
-

pyenv是用于管理多版本Python的命令行工具,解决不同项目需使用不同Python版本的问题。它通过修改PATH和shims机制实现版本切换,支持安装、全局/局部版本设置及与虚拟环境集成,常用命令包括install、global、local和version,轻量稳定,适合频繁切换场景。
-

不能。subinterpreter不绕过GIL,不自动利用多核,仅隔离解释器状态;默认运行于同一OS线程,需配合threading且每个线程独占一个subinterpreter,数据须用channel传bytes,不支持多数C扩展。
-

NumPy的loadtxt等函数无法读取中文路径的根本原因在于其底层调用C标准库fopen时依赖系统默认编码(如Windows的GBK),而Python3传递的是Unicode字符串,未做显式编码适配,导致OSError或UnicodeDecodeError;正确做法是用open('rb')读字节流,再经io.BytesIO包装后传入NumPy函数。
-

Python版本和平台标识不匹配是导致“Couldnotfindaversion”错误的主因,需用pipdebug--verbose查兼容标签、python-c"importplatform;..."核验架构,并优先使用官方MSI安装包确保标签一致。
-

Python中mock的核心是替换运行时依赖,专注验证自身逻辑;应对I/O、第三方服务、高成本对象及协调者类进行mock,正确使用patch与MagicMock并精准断言。
-

文件锁是防止crontab多次启动同一Python脚本的最轻量跨平台方案:脚本用os.open(...,O_CREAT|O_EXCL)原子创建锁文件,成功则写入PID并执行主逻辑,异常或退出时os.unlink()清理;systemd下还需配置Type=oneshot和StartLimitBurst/Interval防重复触发。