python教程技术文章
-
 <p>re.search(r'.pdf$',url)更可靠,因它可配合先清理URL的#和?后内容,再精准匹配路径后缀,而str.endswith()会因查询参数或锚点返回False;且正则支持忽略大小写和多格式扩展名。</p>436 收藏
<p>re.search(r'.pdf$',url)更可靠,因它可配合先清理URL的#和?后内容,再精准匹配路径后缀,而str.endswith()会因查询参数或锚点返回False;且正则支持忽略大小写和多格式扩展名。</p>436 收藏 -
 Python3.10中Union并非新类型,真正提升重构安全性和类型检查能力的是|操作符(PEP604)与TypeGuard协同:|使联合类型更简洁、工具链更稳定,TypeGuard则实现运行时可验证、静态可收窄的精准类型分支。436 收藏
Python3.10中Union并非新类型,真正提升重构安全性和类型检查能力的是|操作符(PEP604)与TypeGuard协同:|使联合类型更简洁、工具链更稳定,TypeGuard则实现运行时可验证、静态可收窄的精准类型分支。436 收藏 -
 根本原因是pip默认超时仅15秒,而PyTorch的whl包超800MB,在网络波动时极易中断;需同时设置--timeout600、--retries5、--trusted-host及--extra-index-url官方CUDA镜像,并推荐使用带自动重试的批处理脚本。436 收藏
根本原因是pip默认超时仅15秒,而PyTorch的whl包超800MB,在网络波动时极易中断;需同时设置--timeout600、--retries5、--trusted-host及--extra-index-url官方CUDA镜像,并推荐使用带自动重试的批处理脚本。436 收藏 -
 zip(matrix)返回元组因默认打包为tuple,需用[list(row)forrowinzip(matrix)]转为可变列表;空矩阵时zip返回空迭代器,转list得[];不规则矩阵用嵌套推导式会报错,应先校验再转置。436 收藏
zip(matrix)返回元组因默认打包为tuple,需用[list(row)forrowinzip(matrix)]转为可变列表;空矩阵时zip返回空迭代器,转list得[];不规则矩阵用嵌套推导式会报错,应先校验再转置。436 收藏 -
 可通过engine.pool.checked_out()和engine.pool.checked_in()获取当前借出与空闲连接数,二者之和反映实时使用状态;需结合SELECT1执行检测真实可用性,并监控checked_out持续上升以定位连接泄漏。435 收藏
可通过engine.pool.checked_out()和engine.pool.checked_in()获取当前借出与空闲连接数,二者之和反映实时使用状态;需结合SELECT1执行检测真实可用性,并监控checked_out持续上升以定位连接泄漏。435 收藏 -
 Python处理JSON依赖json模块,核心是loads()解析字符串、load()读文件、dumps()转字符串、dump()写文件;需注意数据类型、编码、异常处理及with语句资源管理。435 收藏
Python处理JSON依赖json模块,核心是loads()解析字符串、load()读文件、dumps()转字符串、dump()写文件;需注意数据类型、编码、异常处理及with语句资源管理。435 收藏 -
 Python接口测试需双重校验状态码与业务码,分类型捕获requests异常,用安全取值和链式断言提升健壮性,通过参数化和mock构造异常场景并保留curl命令便于复现。435 收藏
Python接口测试需双重校验状态码与业务码,分类型捕获requests异常,用安全取值和链式断言提升健壮性,通过参数化和mock构造异常场景并保留curl命令便于复现。435 收藏 -
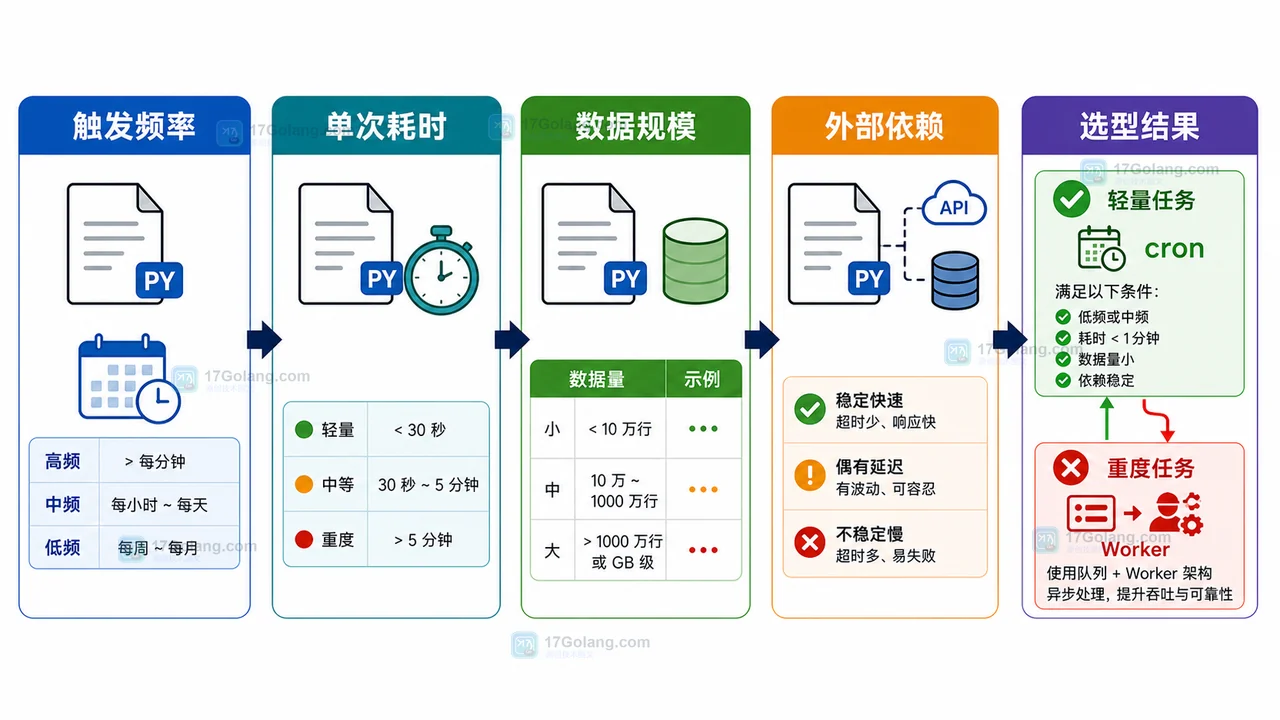 围绕 Python 定时任务上云,按负载、约束、方案对比、推荐架构、风险点和落地清单,比较单机 cron、容器任务、队列 Worker 和函数运行方案。435 收藏
围绕 Python 定时任务上云,按负载、约束、方案对比、推荐架构、风险点和落地清单,比较单机 cron、容器任务、队列 Worker 和函数运行方案。435 收藏 -
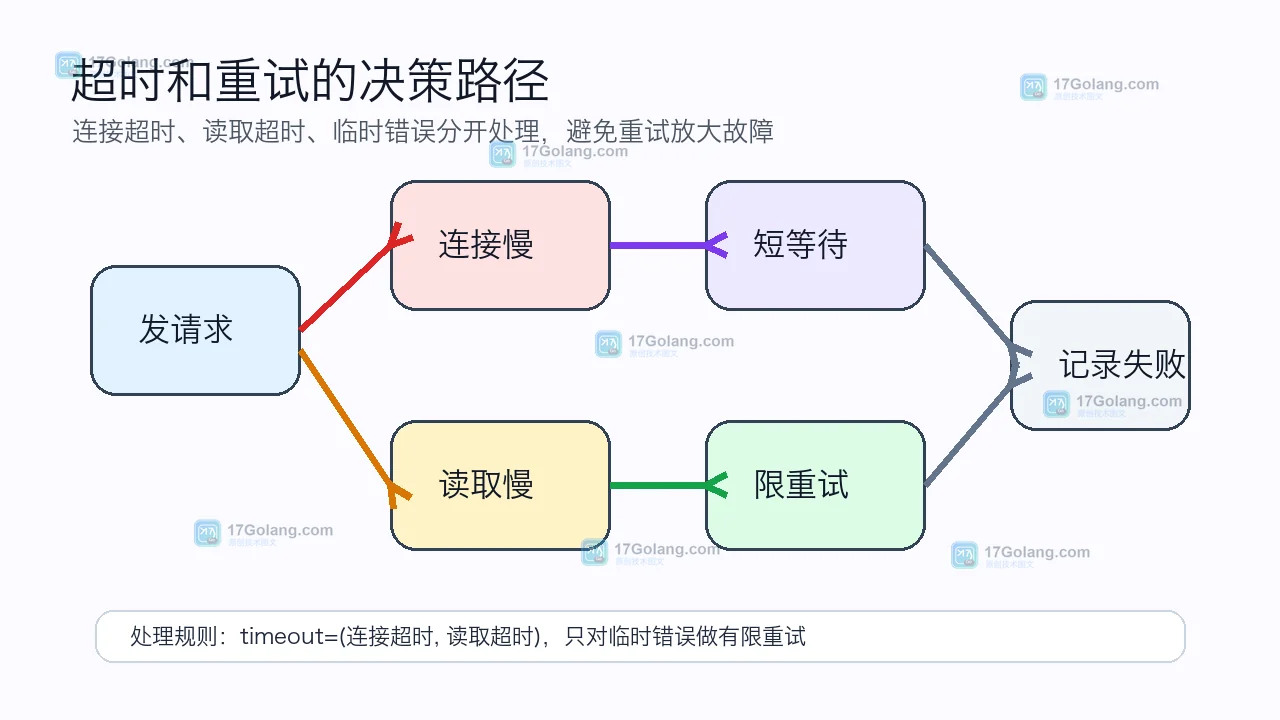 Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。435 收藏
Python 脚本调用外部接口时,如果 requests 不设置 timeout,网络抖动会把 worker 长时间挂住。本文从队列堆积现象入手,讲清排查路径、超时参数、重试策略和上线前检查清单。435 收藏 -
 Python在2002年(2.3版)通过PEP285引入bool类型,使其继承int以兼顾语义清晰性与向后兼容性;True/False是int的特化实例,支持数值运算但显示为布尔字面量,且bool被设计为final类型禁止继承。434 收藏
Python在2002年(2.3版)通过PEP285引入bool类型,使其继承int以兼顾语义清晰性与向后兼容性;True/False是int的特化实例,支持数值运算但显示为布尔字面量,且bool被设计为final类型禁止继承。434 收藏 -
 本文介绍如何从Backtrader或类似回测框架(如backtesting.py)生成的综合图表中,精准提取并独立绘制“权益曲线(EquityCurve)”部分,适用于需深入分析资金增长路径、计算夏普比率或嵌入自定义可视化场景。434 收藏
本文介绍如何从Backtrader或类似回测框架(如backtesting.py)生成的综合图表中,精准提取并独立绘制“权益曲线(EquityCurve)”部分,适用于需深入分析资金增长路径、计算夏普比率或嵌入自定义可视化场景。434 收藏 -
 pytest默认不重试失败用例,因重试会掩盖资源竞争、状态残留、时序等真实缺陷;官方主张从测试设计和环境治理提升稳定性,而非依赖重试兜底。434 收藏
pytest默认不重试失败用例,因重试会掩盖资源竞争、状态残留、时序等真实缺陷;官方主张从测试设计和环境治理提升稳定性,而非依赖重试兜底。434 收藏 -
 推荐用time.time()+os.stat().st_size轮询判断文件是否增长,轻量跨平台;需处理日志滚动、编码(优先utf-8,fallbackgbk)、换行符、重复告警(缓存哈希或记录偏移量)、Windows文件锁(捕获PermissionError并重试)等问题。434 收藏
推荐用time.time()+os.stat().st_size轮询判断文件是否增长,轻量跨平台;需处理日志滚动、编码(优先utf-8,fallbackgbk)、换行符、重复告警(缓存哈希或记录偏移量)、Windows文件锁(捕获PermissionError并重试)等问题。434 收藏 -
 Django模型在Admin后台未显示字段,通常是因为数据库迁移未执行——模型已定义、Admin已注册,但表结构未同步到数据库,导致Admin无法读取或渲染对应字段。433 收藏
Django模型在Admin后台未显示字段,通常是因为数据库迁移未执行——模型已定义、Admin已注册,但表结构未同步到数据库,导致Admin无法读取或渲染对应字段。433 收藏 -
 Harbor中用户需显式授予Scanner角色(非仅developer)才能触发扫描和查看报告;项目级AutoScan开关须开启才自动扫描新镜像;Trivy扫描器需正确注册且镜像内保留requirements.txt等依赖文件。433 收藏
Harbor中用户需显式授予Scanner角色(非仅developer)才能触发扫描和查看报告;项目级AutoScan开关须开启才自动扫描新镜像;Trivy扫描器需正确注册且镜像内保留requirements.txt等依赖文件。433 收藏