python教程技术文章
-
 观察者模式是“一对多”依赖关系,被观察者状态改变时自动通知所有观察者;Python中可用函数引用和列表实现基础订阅系统,weakref可避免内存泄漏,生产环境推荐blinker等轻量库。433 收藏
观察者模式是“一对多”依赖关系,被观察者状态改变时自动通知所有观察者;Python中可用函数引用和列表实现基础订阅系统,weakref可避免内存泄漏,生产环境推荐blinker等轻量库。433 收藏 -
 不能直接在Model字段上用decrypt()方法,因为DjangoORM读取字段是惰性的,且绕过Python属性访问,直接调用from_db_value、to_python等钩子;漏掉任一钩子会导致values()、DRF序列化等场景暴露密文。433 收藏
不能直接在Model字段上用decrypt()方法,因为DjangoORM读取字段是惰性的,且绕过Python属性访问,直接调用from_db_value、to_python等钩子;漏掉任一钩子会导致values()、DRF序列化等场景暴露密文。433 收藏 -
 当用户/物品数超10⁴时,直接两两算cosine/pearson相似度时间复杂度O(N²×M)、内存爆炸(如5万×5万矩阵需~10GB),且无法跳过稀疏数据中90%+的零值;TruncatedSVD通过将稀疏user_item_matrix投影到低维潜在空间(如k=50)压缩维度、保留共现结构,显著降耗。433 收藏
当用户/物品数超10⁴时,直接两两算cosine/pearson相似度时间复杂度O(N²×M)、内存爆炸(如5万×5万矩阵需~10GB),且无法跳过稀疏数据中90%+的零值;TruncatedSVD通过将稀疏user_item_matrix投影到低维潜在空间(如k=50)压缩维度、保留共现结构,显著降耗。433 收藏 -
 Flask默认不支持真正异步任务,因其基于同步WSGI协议,无法识别协程;需用Celery等工具将任务卸载至独立worker进程执行。433 收藏
Flask默认不支持真正异步任务,因其基于同步WSGI协议,无法识别协程;需用Celery等工具将任务卸载至独立worker进程执行。433 收藏 -
 生成器抛异常后立即终止迭代;需用try/except内部捕获异常才能继续yield;throw()可外部注入异常并由生成器处理;StopIteration后生成器永久关闭不可重用。432 收藏
生成器抛异常后立即终止迭代;需用try/except内部捕获异常才能继续yield;throw()可外部注入异常并由生成器处理;StopIteration后生成器永久关闭不可重用。432 收藏 -
 按频次降序排应调用most_common()方法,它返回(key,count)元组列表,全量排序用most_common(),TopN用most_common(k),比sorted(counter.items(),key=lambdax:x[1],reverse=True)更高效且语义明确。432 收藏
按频次降序排应调用most_common()方法,它返回(key,count)元组列表,全量排序用most_common(),TopN用most_common(k),比sorted(counter.items(),key=lambdax:x[1],reverse=True)更高效且语义明确。432 收藏 -
 __enter__和__exit__必须成对出现,因为with语句依赖二者驱动:进入时调__enter__,退出时无条件调__exit__(含异常);缺一则报AttributeError,且__exit__四参数不可少,返回True可抑制异常。432 收藏
__enter__和__exit__必须成对出现,因为with语句依赖二者驱动:进入时调__enter__,退出时无条件调__exit__(含异常);缺一则报AttributeError,且__exit__四参数不可少,返回True可抑制异常。432 收藏 -
 大规模文本预处理需先解决内存与分词问题:用生成器+tf.data避免OOM,轻量分词器优先,合理设vocab_size、output_dim及trainable,转TFRecord提升I/O性能,并用padded_batch确保静态shape。432 收藏
大规模文本预处理需先解决内存与分词问题:用生成器+tf.data避免OOM,轻量分词器优先,合理设vocab_size、output_dim及trainable,转TFRecord提升I/O性能,并用padded_batch确保静态shape。432 收藏 -
 Python中取消异步任务需调用Task.cancel()触发协作式取消,协程必须在await点响应CancelledError并重抛,否则取消无效;纯CPU计算或阻塞IO需转为异步执行以支持取消。432 收藏
Python中取消异步任务需调用Task.cancel()触发协作式取消,协程必须在await点响应CancelledError并重抛,否则取消无效;纯CPU计算或阻塞IO需转为异步执行以支持取消。432 收藏 -
 剪枝本身不减模型体积,必须strip_pruning+h5导出才能看到磁盘大小下降:因PolynomialDecay仅加掩码,保存仍为稠密格式;strip_pruning移除mask后用h5保存,才利用零值压缩实现40–60%体积下降。432 收藏
剪枝本身不减模型体积,必须strip_pruning+h5导出才能看到磁盘大小下降:因PolynomialDecay仅加掩码,保存仍为稠密格式;strip_pruning移除mask后用h5保存,才利用零值压缩实现40–60%体积下降。432 收藏 -
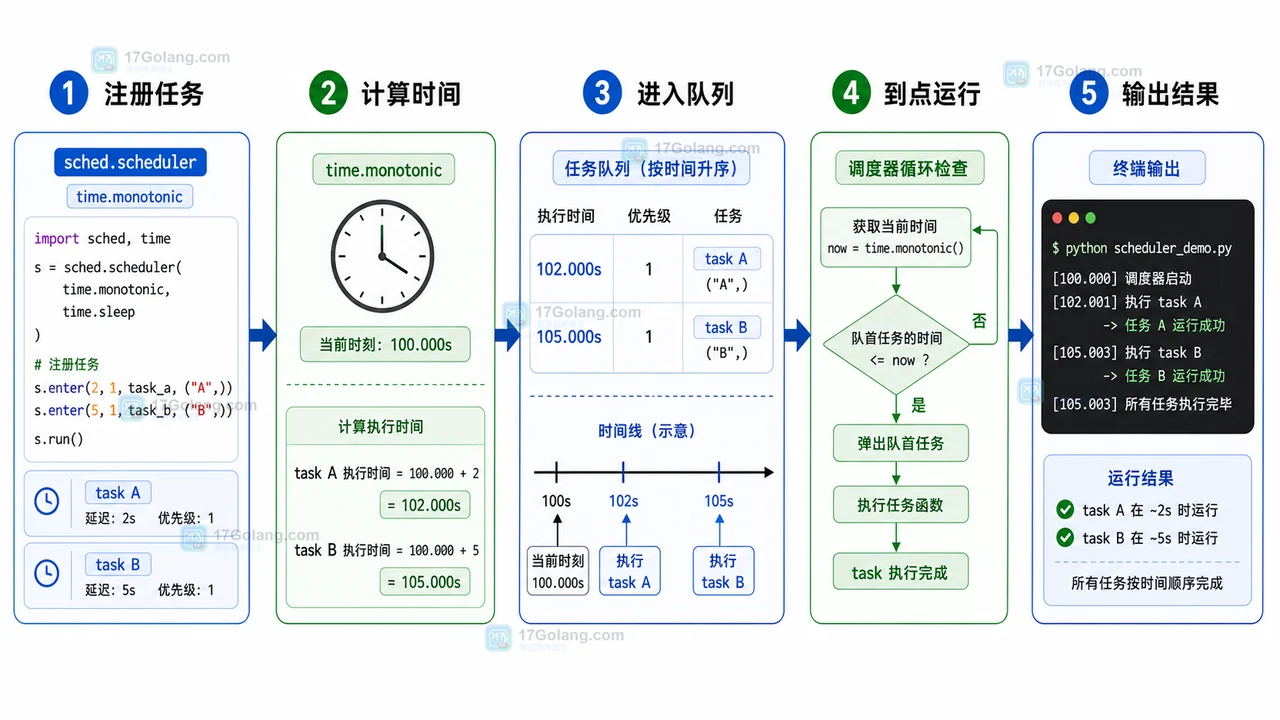 用 Python 标准库 sched 做一个本地轻量定时任务实验,覆盖任务注册、轮询运行、周期任务、失败重试、运行检查和清理边界,适合小脚本和本地自动化场景。432 收藏
用 Python 标准库 sched 做一个本地轻量定时任务实验,覆盖任务注册、轮询运行、周期任务、失败重试、运行检查和清理边界,适合小脚本和本地自动化场景。432 收藏 -
 用paramiko批量改密码须先确认目标主机支持SSH密码修改,因默认不分配pty导致passwd卡住;应使用invoke_shell()模拟终端交互,逐行发送密码并处理提示符、错误和特殊字符,同时记录详细执行日志以排查问题。431 收藏
用paramiko批量改密码须先确认目标主机支持SSH密码修改,因默认不分配pty导致passwd卡住;应使用invoke_shell()模拟终端交互,逐行发送密码并处理提示符、错误和特殊字符,同时记录详细执行日志以排查问题。431 收藏 -
 Python多线程共享数据须避免竞态条件,优先使用queue.Queue、threading.local()或Lock;禁用全局变量直接读写、非原子字典操作及“只读”假设。431 收藏
Python多线程共享数据须避免竞态条件,优先使用queue.Queue、threading.local()或Lock;禁用全局变量直接读写、非原子字典操作及“只读”假设。431 收藏 -
 pynput是跨平台轻量级鼠标键盘事件录制方案,需同步时间戳、区分事件类型并保存为JSON;回放时按时间差延迟,避免权限与坐标缩放问题。431 收藏
pynput是跨平台轻量级鼠标键盘事件录制方案,需同步时间戳、区分事件类型并保存为JSON;回放时按时间差延迟,避免权限与坐标缩放问题。431 收藏 -
 pytest_runtest_logreport不适合脱敏,因为它仅接收已字符串化的report(如longrepr、capstdout),不接触原始参数、断言表达式或日志record对象;敏感信息在进入该hook前就已固化为不可逆文本,正则替换易漏误伤且无法覆盖动态值。431 收藏
pytest_runtest_logreport不适合脱敏,因为它仅接收已字符串化的report(如longrepr、capstdout),不接触原始参数、断言表达式或日志record对象;敏感信息在进入该hook前就已固化为不可逆文本,正则替换易漏误伤且无法覆盖动态值。431 收藏