-
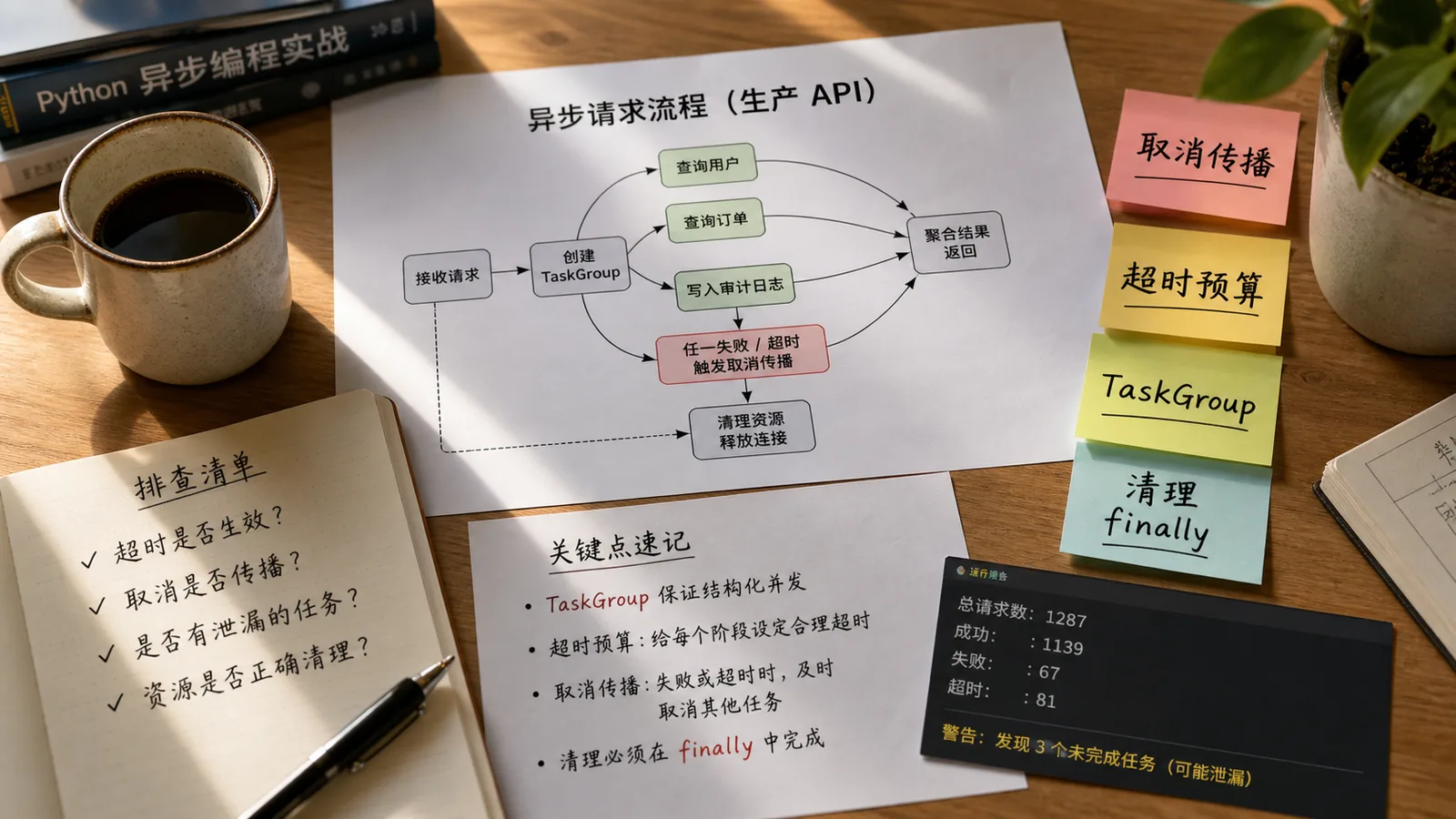
从 FastAPI 生产接口超时场景讲透 Python asyncio TaskGroup、timeout、取消传播、ExceptionGroup 和 finally 资源清理。
-

match是Python3.10+的结构化分发机制,支持路径解构、文件头匹配、数据形状识别等,需注意模式顺序、守卫条件、类型边界及fallback行为。
-

系统未将Python加入PATH导致“不是内部或外部命令”,需手动添加Python安装目录(不含python.exe)到环境变量,并用新cmd验证;多版本共存时优先用py启动器管理。
-

离线安装TensorFlow失败主因是pip自动补缺依赖,非网络问题;需手动下载并安装gast、protobuf、tensorboard等全部精确版本依赖包。
-

本文详解如何将网格中的船移动问题建模为图搜索问题,使用DFS判断在限定步长规则(横向1格、纵向2格)下是否可达,并修正边界检查与移动约束逻辑。
-

大规模文本预处理需先解决内存与分词问题:用生成器+tf.data避免OOM,轻量分词器优先,合理设vocab_size、output_dim及trainable,转TFRecord提升I/O性能,并用padded_batch确保静态shape。
-

使用replace()删除指定字符,如text.replace("a","")可将字符串中所有"a"移除;2.利用translate()结合str.maketrans创建映射表删除多个字符,适合高效批量处理;3.通过列表推导式过滤字符并用join()重组,灵活支持复杂条件;4.使用re.sub()配合正则表达式按模式删除字符,如删除数字或元音;5.所有方法均需注意字符串不可变性,结果需重新赋值。
-

直接用re.findall匹配href易漏PDF链接,因实际链接常含查询参数、重定向、大小写混用或动态触发;应先提取所有URL候选,再统一用小写后缀及MIME类型过滤。
-

Python字符串拼接主要有五种方法:1.+运算符适合简单拼接但性能差;2.f-string语法简洁高效,推荐现代Python使用;3.str.join()适用于列表拼接,性能最优;4.str.format()功能灵活,可读性好;5.%操作符较老,逐渐被替代。
-

健康检查接口应返回200或503状态码:所有关键依赖(DB、缓存、下游API)可用时返回200,任一不可达时返回503并附简短原因;禁止使用4xx,需做轻量级业务探测且避免耗时操作。
-

GeoPandas能轻松处理地理数据,安装后即可读取Shapefile或GeoJSON文件,使用gpd.read_file()加载数据并查看结构与坐标系;通过gdf.plot()实现地图可视化,可设置颜色映射与图形比例;常见操作包括1.用gdf.to_crs()转换坐标系统,2.用.cx或.within()按位置筛选数据,3.用pd.concat()合并多个GeoDataFrame,注意统一CRS。新手可从基础入手逐步掌握其强大功能。
-

今日头条热搜榜的真实Ajax接口可通过F12打开Network→XHR,筛选含“hot”或“hotboard”的请求,典型URL为https://www.toutiao.com/hot-event/hot-board/,需携带Referer、User-Agent及有效Cookie(含tt_webid)才能成功获取JSON数据。
-

Flask中用@app.errorhandler(404)和@app.errorhandler(500)注册处理函数,返回render_template('404.html'),404;需关闭DEBUG模式、确保模板路径正确且显式返回状态码。
-

元组是不可变序列,用()创建,支持索引切片,提供count和index方法,可进行拼接、重复、解包等操作,适用于存储不变数据。
-
![Python 3.x 中出现 TypeError: 'NoneType' object is not subscriptable 错误,通常是由于尝试对一个 None 值进行索引操作(如 [] 操作符)导致的。例如,如果你有一个变量 data,它被赋值为 None,然后你写 data[0],就会触发这个错误。原因分析变量未正确赋值:在使用某个变量之前,没有给它赋值,或者赋值为 None。函数返回值](/uploads/20260515/17788532836a0725a3e5546.png)
该错误是运行时对None进行下标操作所致,因sort()等就地方法、漏写return或API失败导致返回None;需先判空再类型校验,如isinstance(items,(list,tuple))anditems。